Perguntas frequentes sobre previsão no AutoML
APLICA-SE A: Python SDK azure-ai-ml v2 (atual)
Python SDK azure-ai-ml v2 (atual)
Este artigo responde a perguntas comuns sobre previsão em aprendizado de máquina automático (AutoML). Para obter informações gerais sobre a metodologia de previsão no AutoML, consulte o artigo Visão geral dos métodos de previsão no AutoML .
Como posso começar a criar modelos de previsão no AutoML?
Você pode começar lendo o artigo Configurar o AutoML para treinar um modelo de previsão de séries temporais. Você também pode encontrar exemplos práticos em vários cadernos Jupyter:
- Exemplo de partilha de bicicletas
- Previsão usando deep learning
- Solução para muitos modelos
- Receitas de previsão
- Cenários avançados de previsão
Por que o AutoML está lento nos meus dados?
Estamos sempre trabalhando para tornar o AutoML mais rápido e escalável. Para funcionar como uma plataforma de previsão geral, o AutoML faz validações de dados extensas e engenharia de recursos complexos, e pesquisa em um grande espaço de modelo. Essa complexidade pode exigir muito tempo, dependendo dos dados e da configuração.
Uma fonte comum de tempo de execução lento é treinar o AutoML com configurações padrão em dados que contêm várias séries temporais. O custo de muitos métodos de previsão é dimensionado com o número de séries. Por exemplo, métodos como Suavização Exponencial e Profeta treinam um modelo para cada série temporal nos dados de treinamento.
O recurso Muitos Modelos do AutoML é dimensionado para esses cenários distribuindo trabalhos de treinamento em um cluster de computação. Foi aplicado com sucesso a dados com milhões de séries cronológicas. Para obter mais informações, consulte a seção de artigo Muitos modelos . Você também pode ler sobre o sucesso de Muitos Modelos em um conjunto de dados de competição de alto perfil.
Como posso tornar o AutoML mais rápido?
Consulte a resposta Por que o AutoML está lento nos meus dados? para entender por que o AutoML pode ser lento no seu caso.
Considere as seguintes alterações de configuração que podem acelerar seu trabalho:
- Bloqueie modelos de séries cronológicas como ARIMA e Prophet.
- Desative recursos de retrospetiva, como atrasos e janelas rolantes.
- Reduzir:
- O número de tentativas/iterações.
- Tempo limite de avaliação/iteração.
- Tempo limite de experimentação.
- O número de dobras de validação cruzada.
- Certifique-se de que a rescisão antecipada está ativada.
Que configuração de modelagem devo usar?
A previsão do AutoML suporta quatro configurações básicas:
| Configuração | Cenário | Prós | Contras |
|---|---|---|---|
| AutoML padrão | Recomendado se o conjunto de dados tiver um pequeno número de séries temporais com comportamento histórico aproximadamente semelhante. | - Simples de configurar a partir de código/SDK ou estúdio Azure Machine Learning. - O AutoML pode aprender em diferentes séries temporais porque os modelos de regressão agrupam todas as séries em treinamento. Para obter mais informações, consulte Agrupamento de modelos. |
- Os modelos de regressão podem ser menos precisos se as séries temporais nos dados de treinamento tiverem comportamento divergente. - Os modelos de séries cronológicas podem demorar muito tempo a treinar se os dados de treino tiverem um grande número de séries. Para obter mais informações, consulte a resposta Por que o AutoML está lento nos meus dados? |
| AutoML com aprendizagem profunda | Recomendado para conjuntos de dados com mais de 1.000 observações e, potencialmente, inúmeras séries temporais que exibem padrões complexos. Quando ativado, o AutoML varrerá os modelos de rede neural convolucional temporal (TCN) durante o treinamento. Para obter mais informações, consulte Habilitar deep learning. | - Simples de configurar a partir de código/SDK ou estúdio Azure Machine Learning. - Oportunidades de aprendizagem cruzada, porque o TCN agrupa dados em todas as séries. - Precisão potencialmente maior devido à grande capacidade dos modelos de redes neurais profundas (DNN). Para obter mais informações, consulte Modelos de previsão no AutoML. |
- O treinamento pode levar muito mais tempo devido à complexidade dos modelos DNN. - É pouco provável que séries com pequenas quantidades de história beneficiem destes modelos. |
| Muitos modelos | Recomendado se você precisar treinar e gerenciar um grande número de modelos de previsão de forma escalável. Para obter mais informações, consulte a seção de artigo Muitos modelos . | - Escalável. - Precisão potencialmente maior quando as séries temporais têm comportamento divergente umas das outras. |
- Sem aprendizagem em séries temporais. - Não é possível configurar ou executar muitos trabalhos de modelos do estúdio de Aprendizado de Máquina do Azure. Apenas a experiência de código/SDK está disponível no momento. |
| Séries temporais hierárquicas (HTS) | Recomendado se a série em seus dados tiver uma estrutura hierárquica aninhada e você precisar treinar ou fazer previsões em níveis agregados da hierarquia. Para obter mais informações, consulte a seção do artigo de previsão de séries temporais hierárquicas. | - O treinamento em níveis agregados pode reduzir o ruído nas séries temporais do nó folha e potencialmente levar a modelos de maior precisão. - Você pode recuperar previsões para qualquer nível da hierarquia agregando ou desagregando previsões do nível de treinamento. |
- Você precisa fornecer o nível de agregação para treinamento. Atualmente, o AutoML não tem um algoritmo para encontrar um nível ideal. |
Nota
Recomendamos o uso de nós de computação com GPUs quando o aprendizado profundo estiver habilitado para aproveitar melhor a alta capacidade de DNN. O tempo de treinamento pode ser muito mais rápido em comparação com nós com apenas CPUs. Para obter mais informações, consulte o artigo Tamanhos de máquinas virtuais otimizados para GPU.
Nota
O HTS é projetado para tarefas em que é necessário treinamento ou previsão em níveis agregados na hierarquia. Para dados hierárquicos que exigem apenas treinamento e previsão de nó folha, use muitos modelos .
Como posso evitar overfitting e vazamento de dados?
O AutoML usa práticas recomendadas de aprendizado de máquina, como seleção de modelo validada cruzadamente, que atenuam muitos problemas de sobreajuste. No entanto, existem outras fontes potenciais de sobreajuste:
Os dados de entrada contêm colunas de feição derivadas do destino com uma fórmula simples. Por exemplo, um recurso que é um múltiplo exato do alvo pode resultar em uma pontuação de treinamento quase perfeita. O modelo, no entanto, provavelmente não generalizará para dados fora da amostra. Recomendamos que você explore os dados antes do treinamento do modelo e solte colunas que "vazem" as informações de destino.
Os dados de treinamento usam recursos que não são conhecidos no futuro, até o horizonte de previsão. Os modelos de regressão do AutoML atualmente assumem que todos os recursos são conhecidos no horizonte de previsão. Recomendamos que você explore seus dados antes do treinamento e remova todas as colunas de recursos que são conhecidas apenas historicamente.
Existem diferenças estruturais significativas (mudanças de regime) entre as partes de treinamento, validação ou teste dos dados. Por exemplo, considere o efeito da pandemia de COVID-19 na demanda por quase qualquer bem durante 2020 e 2021. Este é um exemplo clássico de uma mudança de regime. O sobreajuste devido à mudança de regime é o problema mais desafiador a ser abordado, porque é altamente dependente do cenário e pode exigir conhecimento profundo para ser identificado.
Como primeira linha de defesa, tente reservar de 10% a 20% do histórico total para dados de validação ou dados de validação cruzada. Nem sempre é possível reservar essa quantidade de dados de validação se o histórico de treinamento for curto, mas é uma prática recomendada. Para obter mais informações, consulte Dados de treinamento e validação.
O que significa se o meu trabalho de formação atingir pontuações de validação perfeitas?
É possível ver pontuações perfeitas quando você está visualizando métricas de validação de um trabalho de treinamento. Uma pontuação perfeita significa que a previsão e os reais no conjunto de validação são os mesmos ou quase os mesmos. Por exemplo, você tem um erro quadrático médio raiz igual a 0,0 ou uma pontuação R2 de 1,0.
Uma pontuação de validação perfeita geralmente indica que o modelo está gravemente sobredimensionado, provavelmente devido ao vazamento de dados. O melhor curso de ação é inspecionar os dados em busca de vazamentos e soltar as colunas que estão causando o vazamento.
E se os dados das minhas séries cronológicas não tiverem observações espaçadas regularmente?
Todos os modelos de previsão do AutoML exigem que os dados de treinamento tenham observações espaçadas regularmente em relação ao calendário. Este requisito inclui casos, como observações mensais ou anuais, em que o número de dias entre observações pode variar. Os dados dependentes do tempo podem não atender a esse requisito em dois casos:
Os dados têm uma frequência bem definida, mas as observações em falta estão a criar lacunas na série. Neste caso, o AutoML tentará detetar a frequência, preencher novas observações para as lacunas e imputar valores de alvo e recurso ausentes. Opcionalmente, o usuário pode configurar os métodos de imputação por meio das configurações do SDK ou da interface do usuário da Web. Para obter mais informações, consulte Featurização personalizada.
Os dados não têm uma frequência bem definida. Ou seja, a duração entre as observações não tem um padrão discernível. Dados transacionais, como os de um sistema de ponto de venda, são um exemplo. Nesse caso, você pode definir o AutoML para agregar seus dados para uma frequência escolhida. Você pode escolher uma frequência regular que melhor se adapte aos dados e aos objetivos de modelagem. Para obter mais informações, consulte Agregação de dados.
Como escolher a métrica principal?
A métrica primária é importante porque seu valor nos dados de validação determina o melhor modelo durante a varredura e seleção. O erro quadrático médio de raiz normalizado (NRMSE) e o erro absoluto médio normalizado (NMAE) são geralmente as melhores escolhas para a métrica primária em tarefas de previsão.
Para escolher entre eles, observe que o NRMSE penaliza outliers nos dados de treinamento mais do que o NMAE porque usa o quadrado do erro. NMAE pode ser uma escolha melhor se você quiser que o modelo seja menos sensível a outliers. Para obter mais informações, consulte Métricas de regressão e previsão.
Nota
Não recomendamos o uso da pontuação R2, ou R2, como métrica primária para previsão.
Nota
O AutoML não suporta funções personalizadas ou fornecidas pelo usuário para a métrica principal. Você deve escolher uma das métricas primárias predefinidas suportadas pelo AutoML.
Como posso melhorar a precisão do meu modelo?
- Certifique-se de que está a configurar o AutoML da melhor forma para os seus dados. Para obter mais informações, consulte a resposta Que configuração de modelagem devo usar?
- Confira o caderno de receitas de previsão para obter guias passo a passo sobre como criar e melhorar modelos de previsão.
- Avalie o modelo usando testes retroativos ao longo de vários ciclos de previsão. Este procedimento fornece uma estimativa mais robusta do erro de previsão e fornece uma linha de base para medir as melhorias. Para obter um exemplo, consulte o bloco de anotações de backtesting.
- Se os dados forem barulhentos, considere agregá-los a uma frequência mais grosseira para aumentar a relação sinal-ruído. Para obter mais informações, consulte Agregação de dados de frequência e destino.
- Adicione novos recursos que podem ajudar a prever o alvo. A experiência no assunto pode ajudar muito quando você seleciona dados de treinamento.
- Compare os valores das métricas de validação e teste e determine se o modelo selecionado está ajustando ou sobreajustando os dados. Esse conhecimento pode guiá-lo para uma melhor configuração de treinamento. Por exemplo, você pode determinar que precisa usar mais dobras de validação cruzada em resposta ao sobreajuste.
O AutoML selecionará sempre o mesmo melhor modelo a partir dos mesmos dados de treinamento e configuração?
O processo de pesquisa de modelos do AutoML não é determinístico, portanto, nem sempre seleciona o mesmo modelo a partir dos mesmos dados e configuração.
Como faço para corrigir um erro de falta de memória?
Existem dois tipos de erros de memória:
- RAM sem memória
- Disco sem memória
Primeiro, certifique-se de que está a configurar o AutoML da melhor forma para os seus dados. Para obter mais informações, consulte a resposta Que configuração de modelagem devo usar?
Para as configurações padrão de AutoML, você pode corrigir erros de falta de memória usando nós de computação com mais RAM. Uma regra geral é que a quantidade de RAM livre deve ser pelo menos 10 vezes maior do que o tamanho dos dados brutos para executar o AutoML com as configurações padrão.
Você pode resolver erros de falta de memória de disco excluindo o cluster de computação e criando um novo.
Que cenários avançados de previsão são suportados pelo AutoML?
O AutoML suporta os seguintes cenários de previsão avançada:
- Previsões quantitativas
- Avaliação robusta do modelo através de previsões contínuas
- Previsão para além do horizonte de previsão
- Previsão de quando há um intervalo de tempo entre os períodos de treinamento e previsão
Para obter exemplos e detalhes, consulte o bloco de anotações para cenários avançados de previsão.
Como faço para visualizar as métricas da previsão de trabalhos de treinamento?
Para encontrar valores de métricas de treinamento e validação, consulte Exibir informações sobre trabalhos ou execuções no estúdio. Você pode visualizar métricas para qualquer modelo de previsão treinado em AutoML acessando um modelo da interface do usuário do trabalho AutoML no estúdio e selecionando a guia Métricas .
Como depurar falhas com a previsão de trabalhos de treinamento?
Se o trabalho de previsão do AutoML falhar, uma mensagem de erro na interface do usuário do estúdio poderá ajudá-lo a diagnosticar e corrigir o problema. A melhor fonte de informações sobre a falha além da mensagem de erro é o log de driver para o trabalho. Para obter instruções sobre como localizar logs de driver, consulte Exibir informações de trabalhos/execuções com MLflow.
Nota
Para um trabalho de Muitos Modelos ou HTS, o treinamento geralmente é feito em clusters de computação de vários nós. Os logs para esses trabalhos estão presentes para cada endereço IP do nó. Nesse caso, você precisa procurar logs de erro em cada nó. Os logs de erro, juntamente com os logs de driver, estão na pasta user_logs para cada IP de nó.
Como faço para implantar um modelo a partir da previsão de trabalhos de treinamento?
Você pode implantar um modelo a partir da previsão de trabalhos de treinamento de uma destas maneiras:
- Ponto de extremidade online: verifique o arquivo de pontuação usado na implantação ou selecione a guia Teste na página do ponto de extremidade no estúdio para entender a estrutura de entrada esperada pela implantação. Veja este bloco de notas para obter um exemplo. Para obter mais informações sobre implantação online, consulte Implantar um modelo AutoML em um ponto de extremidade online.
- Ponto de extremidade em lote: esse método de implantação requer que você desenvolva um script de pontuação personalizado. Consulte este bloco de notas para obter um exemplo. Para obter mais informações sobre a implantação em lote, consulte Usar pontos de extremidade em lote para pontuação em lote.
Para implantações de interface do usuário, recomendamos que você use uma destas opções:
- Ponto final em tempo real
- Ponto final em lote
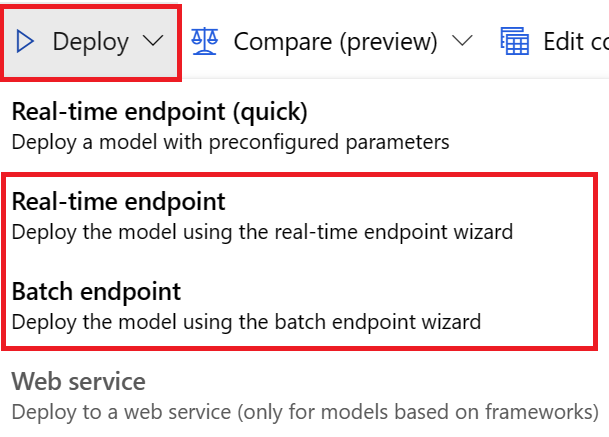
Não use a primeira opção, Real-time-endpoint (quick).
Nota
A partir de agora, não oferecemos suporte à implantação do modelo MLflow a partir da previsão de trabalhos de treinamento via SDK, CLI ou interface do usuário. Você receberá erros se tentar.
O que é um espaço de trabalho, ambiente, experimento, instância de computação ou destino de computação?
Se você não estiver familiarizado com os conceitos do Azure Machine Learning, comece com os artigos O que é o Azure Machine Learning? e O que é um espaço de trabalho do Azure Machine Learning? .
Próximos passos
- Saiba mais sobre como configurar o AutoML para treinar um modelo de previsão de séries temporais.
- Saiba mais sobre os recursos de calendário para previsão de séries temporais no AutoML.
- Saiba mais sobre como o AutoML usa o aprendizado de máquina para criar modelos de previsão.
- Saiba mais sobre a previsão do AutoML para recursos com atraso.