Benchmarks de desempenho do Azure AI Search
Importante
Essas referências se aplicam a serviços de pesquisa criados antes de 3 de abril de 2024 em implantações executadas em infraestruturas mais antigas. Os parâmetros de referência também se aplicam apenas a cargas de trabalho não vetoriais. As atualizações estão pendentes para serviços e cargas de trabalho nos novos limites.
Os benchmarks de desempenho são úteis para estimar o desempenho potencial em configurações semelhantes. O desempenho real depende de uma variedade de fatores, incluindo o tamanho do seu serviço de pesquisa e os tipos de consultas que você está enviando.
Para ajudá-lo a estimar o tamanho do serviço de pesquisa necessário para sua carga de trabalho, executamos vários benchmarks para documentar o desempenho de diferentes serviços e configurações de pesquisa.
Para cobrir uma variedade de casos de uso diferentes, executamos benchmarks para dois cenários principais:
- Pesquisa de comércio eletrônico - Este benchmark emula um cenário real de comércio eletrônico e é baseado na empresa nórdica de comércio eletrônico CDON.
- Pesquisa de documentos - Este cenário é composto pela pesquisa de palavras-chave sobre documentos de texto completo do Semantic Scholar. Isso emula uma solução típica de pesquisa de documentos.
Embora esses cenários reflitam casos de uso diferentes, cada cenário é diferente, por isso sempre recomendamos o teste de desempenho de sua carga de trabalho individual. Publicamos uma solução de teste de desempenho usando o JMeter para que você possa executar testes semelhantes em seu próprio serviço.
Metodologia de ensaio
Para avaliar comparativamente o desempenho do Azure AI Search, executamos testes para dois cenários diferentes em diferentes camadas e combinações de réplica/partição.
Para a criação destes benchmarks, foi utilizada a seguinte metodologia:
- O teste começa em
Xconsultas por segundo (QPS) durante 180 segundos. Isto era geralmente 5 ou 10 QPS. - O QPS então aumentou
Xe correu por mais 180 segundos - A cada 180 segundos, o teste aumentava pelo
XQPS até que a latência média aumentasse acima de 1000 ms ou menos de 99% das consultas fossem bem-sucedidas.
O gráfico a seguir fornece um exemplo visual de como é a carga de consulta do teste:
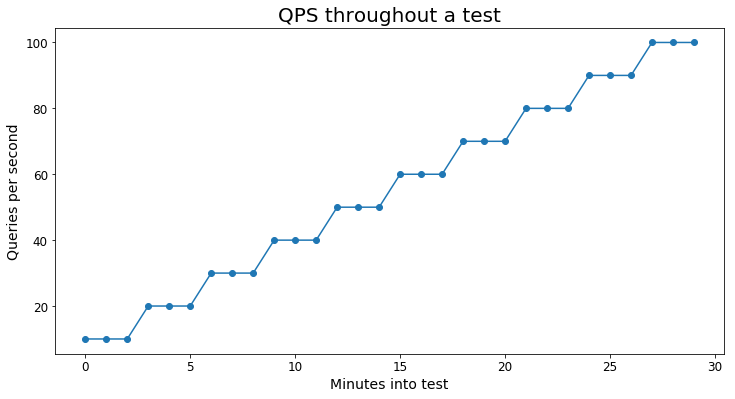
Cada cenário usou pelo menos 10.000 consultas exclusivas para evitar que os testes fossem excessivamente distorcidos pelo cache.
Importante
Esses testes incluem apenas cargas de trabalho de consulta. Se você espera ter um alto volume de operações de indexação, certifique-se de levar isso em conta em sua estimativa e teste de desempenho. O código de exemplo para simular a indexação pode ser encontrado neste tutorial.
Definições
QPS máximo - os números máximos de QPS são baseados no maior QPS alcançado em um teste onde 99% das consultas concluídas com sucesso sem limitação e latência média ficou abaixo de 1000 ms.
Percentagem do QPS máximo - Percentagem do QPS máximo alcançado para um determinado teste. Por exemplo, se um determinado teste atingisse um máximo de 100 QPS, 20% do QPS máximo seria de 20 QPS.
Latência - A latência do servidor para uma consulta, esses números não incluem atraso de ida e volta (RTT). Os valores são em milissegundos (ms).
Declaração de exoneração de responsabilidade relativa aos testes
O código que usamos para executar esses benchmarks está disponível no repositório azure-search-performance-testing . Vale a pena notar que observamos níveis de QPS ligeiramente mais baixos com a solução de teste de desempenho JMeter do que nos benchmarks. As diferenças podem ser atribuídas a diferenças no estilo dos testes. Isso fala da importância de tornar seus testes de desempenho o mais semelhantes possível à sua carga de trabalho de produção.
Importante
Esses benchmarks não garantem de forma alguma um certo nível de desempenho do seu serviço, mas podem dar uma ideia do desempenho que você pode esperar com base no seu cenário.
Se você tiver alguma dúvida ou preocupação, entre em contato conosco em azuresearch_contact@microsoft.com.
Benchmark 1: Pesquisa de comércio eletrónico
![]()
Esta referência foi criada em parceria com a empresa de comércio eletrónico CDON, o maior mercado online da região nórdica, com operações na Suécia, Finlândia, Noruega e Dinamarca. Através de seus 1.500 comerciantes, a CDON oferece uma ampla gama que inclui mais de 8 milhões de produtos. Em 2020, o CDON teve mais de 120 milhões de visitantes e 2 milhões de clientes ativos. Você pode saber mais sobre o uso do Azure AI Search pelo CDON neste artigo.
Para executar esses testes, usamos um instantâneo do índice de pesquisa de produção do CDON e milhares de consultas exclusivas de seu site.
Detalhes do cenário
- Contagem de documentos: 6.000.000
- Tamanho do índice: 20 GB
- Esquema de índice: um índice amplo com 250 campos no total, 25 campos pesquisáveis e 200 campos faciais/filtráveis
- Tipos de Consulta: consultas de pesquisa de texto completo, incluindo facetas, filtros, ordenação e perfis de pontuação
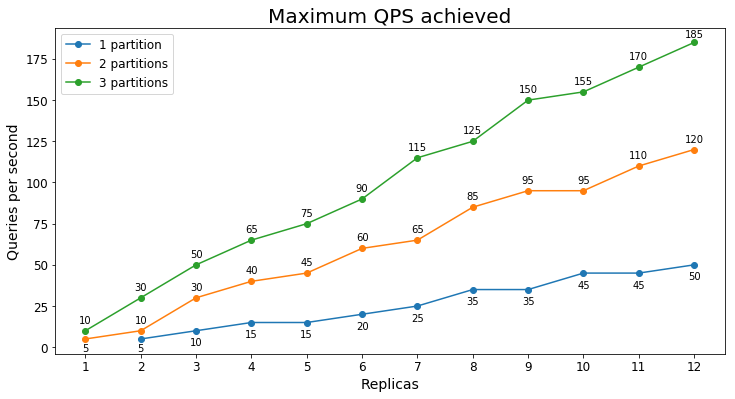
S1 Desempenho
Consultas por segundo
O gráfico a seguir mostra a maior carga de consulta que um serviço poderia lidar por um longo período de tempo em termos de consultas por segundo (QPS).
Latência da consulta
A latência da consulta varia com base na carga do serviço e os serviços sob maior tensão têm uma latência média de consulta mais alta. A tabela a seguir mostra os percentis 25, 50, 75, 90, 95 e 99 de latência de consulta para três níveis de uso diferentes.
| Percentagem de QPS máximo | Latência média | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 104 ms | 35 ms | 115 ms | 177 ms | 257 ms | 738 ms |
| 50% | 140 ms | 47 ms | 144 ms | 241 ms | 400 ms | 1175 ms |
| 80% | 239 ms | 77 ms | 248 ms | 466 ms | 763 ms | 1752 ms |
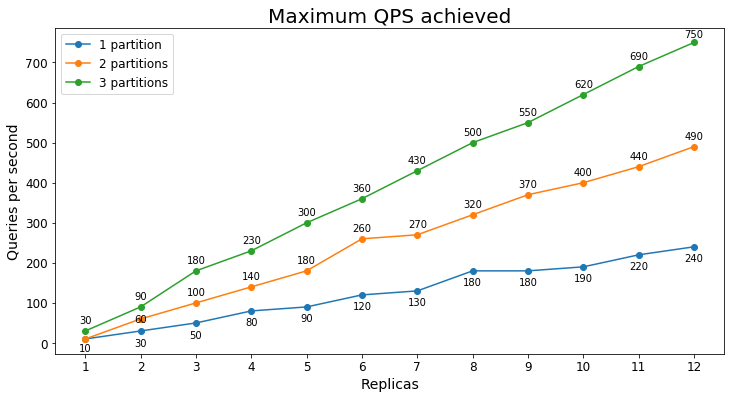
Desempenho do S2
Consultas por segundo
O gráfico a seguir mostra a maior carga de consulta que um serviço poderia lidar por um longo período de tempo em termos de consultas por segundo (QPS).
Latência da consulta
A latência da consulta varia com base na carga do serviço e os serviços sob maior tensão têm uma latência média de consulta mais alta. A tabela a seguir mostra os percentis 25, 50, 75, 90, 95 e 99 de latência de consulta para três níveis de uso diferentes.
| Percentagem de QPS máximo | Latência média | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 56 ms | 21 ms | 68 ms | 106 ms | 132 ms | 210 ms |
| 50% | 71 ms | 26 ms | 83 ms | 132 ms | 177 ms | 329 ms |
| 80% | 140 ms | 47 ms | 153 ms | 293 ms | 452 ms | 924 ms |
Desempenho do S3
Consultas por segundo
O gráfico a seguir mostra a maior carga de consulta que um serviço poderia lidar por um longo período de tempo em termos de consultas por segundo (QPS).
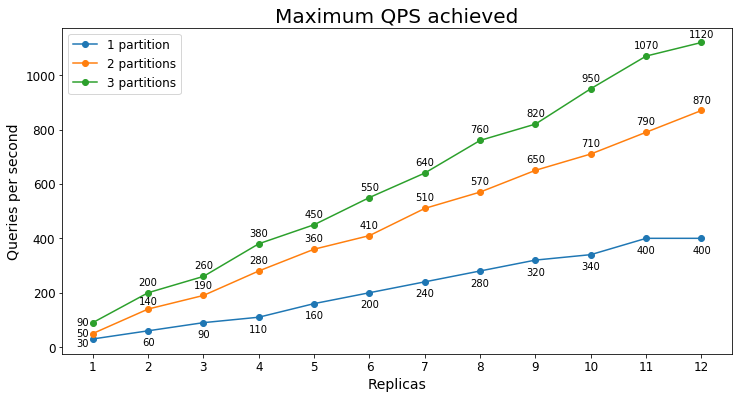
Neste caso, vemos que adicionar uma segunda partição aumenta significativamente o QPS máximo, mas adicionar uma terceira partição fornece retornos marginais decrescentes. A melhoria menor é provável porque todos os dados já estão sendo puxados para a memória ativa do S3 com apenas duas partições.
Latência da consulta
A latência da consulta varia com base na carga do serviço e os serviços sob maior tensão têm uma latência média de consulta mais alta. A tabela a seguir mostra os percentis 25, 50, 75, 90, 95 e 99 de latência de consulta para três níveis de uso diferentes.
| Percentagem de QPS máximo | Latência média | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 50 ms | 20 ms | 64 ms | 83 ms | 98 ms | 160 ms |
| 50% | 62 ms | 24 ms | 80 ms | 107 ms | 130 ms | 253 ms |
| 80% | 115 ms | 38 ms | 121 ms | 218 ms | 352 ms | 828 em |
Parâmetro de referência 2: Pesquisa de documentos
Detalhes do cenário
- Contagem de documentos: 7,5 milhões
- Tamanho do índice: 22 GB
- Esquema de Índice: 23 campos; 8 pesquisáveis, 10 filtráveis/facetable
- Tipos de Consulta: pesquisas de palavras-chave com facetas e realce de cliques
S1 Desempenho
Consultas por segundo
O gráfico a seguir mostra a maior carga de consulta que um serviço poderia lidar por um longo período de tempo em termos de consultas por segundo (QPS).
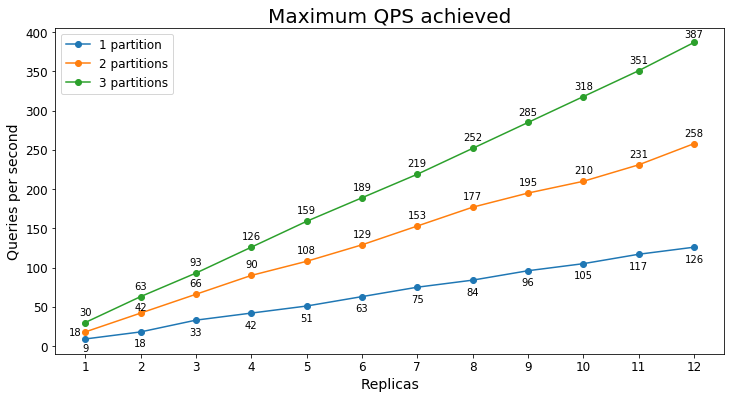
Latência da consulta
A latência da consulta varia com base na carga do serviço e os serviços sob maior tensão têm uma latência média de consulta mais alta. A tabela a seguir mostra os percentis 25, 50, 75, 90, 95 e 99 de latência de consulta para três níveis de uso diferentes.
| Percentagem de QPS máximo | Latência média | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 67 ms | 44 ms | 77 ms | 103 ms | 126 ms | 216 ms |
| 50% | 93 ms | 59 ms | 110 ms | 150 ms | 184 ms | 304 ms |
| 80% | 150 ms | 96 ms | 184 ms | 248 ms | 297 ms | 424 ms |
Desempenho do S2
Consultas por segundo
O gráfico a seguir mostra a maior carga de consulta que um serviço poderia lidar por um longo período de tempo em termos de consultas por segundo (QPS).
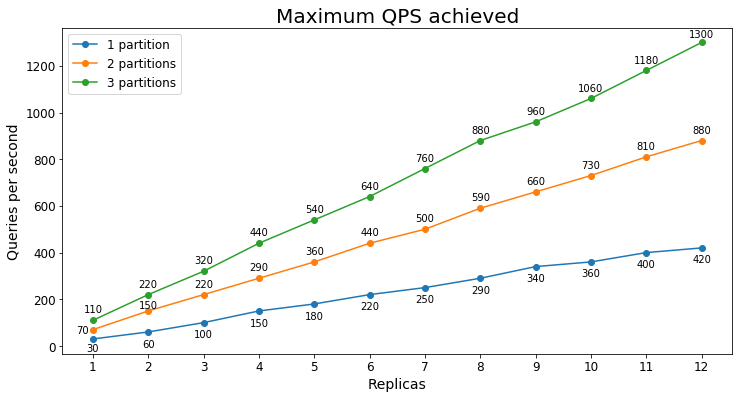
Latência da consulta
A latência da consulta varia com base na carga do serviço e os serviços sob maior tensão têm uma latência média de consulta mais alta. A tabela a seguir mostra os percentis 25, 50, 75, 90, 95 e 99 de latência de consulta para três níveis de uso diferentes.
| Percentagem de QPS máximo | Latência média | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 45 ms | 31 ms | 55 ms | 73 ms | 84 ms | 109 ms |
| 50% | 63 ms | 39 ms | 81 ms | 106 ms | 123 ms | 163 ms |
| 80% | 115 ms | 73 ms | 145 ms | 191 ms | 224 ms | 291 ms |
Desempenho do S3
Consultas por segundo
O gráfico a seguir mostra a maior carga de consulta que um serviço poderia lidar por um longo período de tempo em termos de consultas por segundo (QPS).
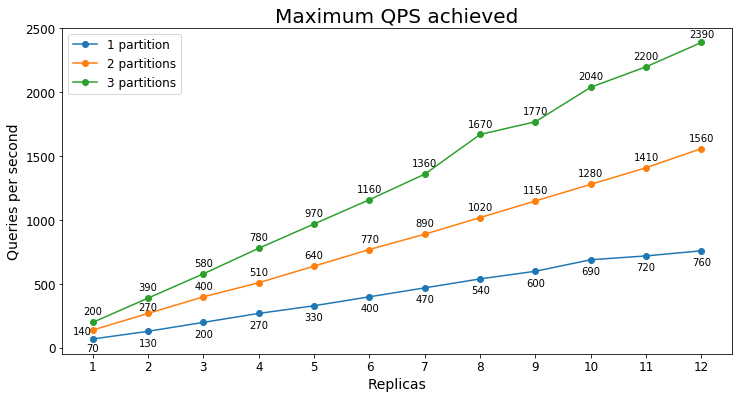
Latência da consulta
A latência da consulta varia com base na carga do serviço e os serviços sob maior tensão têm uma latência média de consulta mais alta. A tabela a seguir mostra os percentis 25, 50, 75, 90, 95 e 99 de latência de consulta para três níveis de uso diferentes.
| Percentagem de QPS máximo | Latência média | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 43 ms | 29 ms | 53 ms | 74 ms | 86 ms | 111 ms |
| 50% | 65 ms | 37 ms | 85 ms | 111 ms | 128 ms | 164 ms |
| 80% | 126 ms | 83 ms | 162 ms | 205 ms | 233 ms | 281 ms |
Conclusões
Por meio desses benchmarks, você pode ter uma ideia do desempenho que o Azure AI Search oferece. Você também pode ver a diferença entre os serviços em diferentes níveis.
Alguns dos principais caminhos a partir desses benchmarks são:
- Um S2 normalmente pode lidar com pelo menos quatro vezes o volume de consulta como um S1
- Um S2 normalmente tem latência menor do que um S1 em volumes de consulta comparáveis
- À medida que você adiciona réplicas, o QPS que um serviço pode manipular normalmente é dimensionado linearmente (por exemplo, se uma réplica pode lidar com 10 QPS, então cinco réplicas geralmente podem lidar com 50 QPS)
- Quanto maior a carga no serviço, maior a latência média
Você também pode ver que o desempenho pode variar drasticamente entre os cenários. Se você não está obtendo o desempenho esperado, confira as dicas para um melhor desempenho.
Próximos passos
Agora que você já viu os benchmarks de desempenho, pode saber mais sobre como analisar o desempenho do Azure AI Search e os principais fatores que influenciam o desempenho.