Tutorial: Otimizar a indexação usando a API push
O Azure AI Search dá suporte a duas abordagens básicas para importar dados para um índice de pesquisa: enviar seus dados para o índice programaticamente ou extrair os dados apontando um indexador do Azure AI Search para uma fonte de dados suportada.
Este tutorial explica como indexar dados de forma eficiente usando o modelo push enviando solicitações em lote e usando uma estratégia de repetição de backoff exponencial. Você pode baixar e executar o aplicativo de exemplo. Este artigo explica os principais aspetos do aplicativo e quais fatores considerar ao indexar dados.
Este tutorial usa C# e a biblioteca Azure.Search.Documents do SDK do Azure para .NET para executar as seguintes tarefas:
- Criar um índice
- Teste vários tamanhos de lote para determinar o tamanho mais eficiente
- Indexar lotes de forma assíncrona
- Use vários threads para aumentar as velocidades de indexação
- Use uma estratégia de repetição de backoff exponencial para repetir documentos com falha
Pré-requisitos
Os seguintes serviços e ferramentas são necessários para este tutorial.
Uma subscrição do Azure. Se não tiver uma, poderá criar uma conta gratuita.
Visual Studio, qualquer edição. Exemplos de código e instruções foram testados na edição gratuita da Comunidade.
Transferir ficheiros
O código-fonte deste tutorial está na pasta optimize-data-indexing/v11 no repositório GitHub Azure-Samples/azure-search-dotnet-scale .
Considerações principais
Os fatores que afetam as velocidades de indexação são listados a seguir. Para saber mais, consulte Indexar grandes conjuntos de dados.
- Camada de serviço e número de partições/réplicas: Adicionar partições ou atualizar sua camada aumenta as velocidades de indexação.
- Complexidade do esquema de índice: Adicionar campos e propriedades de campo reduz as velocidades de indexação. Índices menores são mais rápidos para indexar.
- Tamanho do lote: o tamanho ideal do lote varia com base no esquema de índice e no conjunto de dados.
- Número de threads/trabalhadores: um único thread não aproveita ao máximo as velocidades de indexação.
- Estratégia de repetição: uma estratégia de repetição de backoff exponencial é uma prática recomendada para indexação ideal.
- Velocidades de transferência de dados de rede: As velocidades de transferência de dados podem ser um fator limitante. Indexe dados de dentro do seu ambiente do Azure para aumentar as velocidades de transferência de dados.
Etapa 1: Criar um serviço de Pesquisa de IA do Azure
Para concluir este tutorial, você precisa de um serviço Azure AI Search, que você pode criar no portal do Azure ou encontrar um serviço existente em sua assinatura atual. Recomendamos usar a mesma camada que você planeja usar na produção para que você possa testar e otimizar com precisão as velocidades de indexação.
Obter uma chave de administrador e URL para o Azure AI Search
Este tutorial usa autenticação baseada em chave. Copie uma chave de API admin para colar no arquivo appsettings.json .
Inicie sessão no portal do Azure. Obtenha o URL do ponto de extremidade na página Visão geral do serviço de pesquisa. Um ponto final de exemplo poderá ser parecido com
https://mydemo.search.windows.net.Em Teclas de Configurações>, obtenha uma chave de administrador para obter todos os direitos no serviço. Há duas chaves de administrador intercambiáveis, fornecidas para continuidade de negócios no caso de você precisar rolar uma. Você pode usar a chave primária ou secundária em solicitações para adicionar, modificar e excluir objetos.
Etapa 2: configurar seu ambiente
Inicie o Visual Studio e abra OptimizeDataIndexing.sln.
No Gerenciador de Soluções, abra appsettings.json para fornecer as informações de conexão do serviço.
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
Etapa 3: Explore o código
Depois de atualizar appsettings.json, o programa de exemplo em OptimizeDataIndexing.sln deve estar pronto para ser compilado e executado.
Esse código é derivado da seção C# de Guia de início rápido: pesquisa de texto completo usando os SDKs do Azure. Você pode encontrar informações mais detalhadas sobre os conceitos básicos de trabalhar com o SDK do .NET nesse artigo.
Este aplicativo de console C#/.NET simples executa as seguintes tarefas:
- Cria um novo índice com base na estrutura de dados da classe C#
Hotel(que também faz referência àAddressclasse) - Testa vários tamanhos de lote para determinar o tamanho mais eficiente
- Indexa dados de forma assíncrona
- Usando vários threads para aumentar as velocidades de indexação
- Usando uma estratégia de repetição de backoff exponencial para repetir itens com falha
Antes de executar o programa, reserve um minuto para estudar o código e as definições de índice para este exemplo. O código relevante está em vários ficheiros:
- Hotel.cs e Address.cs contêm o esquema que define o índice
- DataGenerator.cs contém uma classe simples para facilitar a criação de grandes quantidades de dados do hotel
- ExponentialBackoff.cs contém código para otimizar o processo de indexação, conforme descrito neste artigo
- Program.cs contém funções que criam e excluem o índice do Azure AI Search, indexam lotes de dados e testam diferentes tamanhos de lote
Criar o índice
Este programa de exemplo usa o SDK do Azure para .NET para definir e criar um índice do Azure AI Search. Ele aproveita a FieldBuilder classe para gerar uma estrutura de índice a partir de uma classe de modelo de dados C#.
O modelo de dados é definido pela Hotel classe, que também contém referências à Address classe. O FieldBuilder detalha várias definições de classe para gerar uma estrutura de dados complexa para o índice. As tags de metadados são usadas para definir os atributos de cada campo, como se é pesquisável ou classificável.
Os trechos a seguir do arquivo Hotel.cs mostram como um único campo e uma referência a outra classe de modelo de dados podem ser especificados.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
No arquivo Program.cs, o índice é definido com um nome e uma coleção de campos gerados pelo FieldBuilder.Build(typeof(Hotel)) método e, em seguida, criado da seguinte maneira:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Gerar dados
Uma classe simples é implementada no arquivo DataGenerator.cs para gerar dados para teste. O único objetivo desta classe é facilitar a geração de um grande número de documentos com um ID exclusivo para indexação.
Para obter uma lista de 100.000 hotéis com IDs exclusivos, execute as seguintes linhas de código:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Há dois tamanhos de hotéis disponíveis para teste nesta amostra: pequenos e grandes.
O esquema do seu índice tem um efeito nas velocidades de indexação. Por esse motivo, faz sentido converter essa classe para gerar dados que melhor correspondam ao esquema de índice pretendido depois de executar este tutorial.
Etapa 4: Testar tamanhos de lotes
O Azure AI Search dá suporte às seguintes APIs para carregar um ou vários documentos em um índice:
A indexação de documentos em lotes melhora significativamente o desempenho da indexação. Esses lotes podem ter até 1.000 documentos ou até cerca de 16 MB por lote.
Determinar o tamanho de lote ideal para seus dados é um componente fundamental para otimizar as velocidades de indexação. Os dois principais fatores que influenciam o tamanho ideal do lote são:
- O esquema do seu índice
- O tamanho dos seus dados
Como o tamanho de lote ideal depende do seu índice e dos seus dados, a melhor abordagem é testar diferentes tamanhos de lote para determinar o que resulta nas velocidades de indexação mais rápidas para o seu cenário.
A função a seguir demonstra uma abordagem simples para testar tamanhos de lote.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Como nem todos os documentos têm o mesmo tamanho (embora estejam nesta amostra), estimamos o tamanho dos dados que enviamos para o serviço de pesquisa. Você pode fazer isso usando a seguinte função que primeiro converte o objeto em json e, em seguida, determina seu tamanho em bytes. Esta técnica permite-nos determinar quais os tamanhos de lote mais eficientes em termos de velocidades de indexação MB/s.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
A função requer um SearchClient mais o número de tentativas que você gostaria de testar para cada tamanho de lote. Como pode haver variabilidade nos tempos de indexação para cada lote, tente cada lote três vezes por padrão para tornar os resultados estatisticamente mais significativos.
await TestBatchSizesAsync(searchClient, numTries: 3);
Ao executar a função, você verá uma saída no console como o exemplo a seguir:
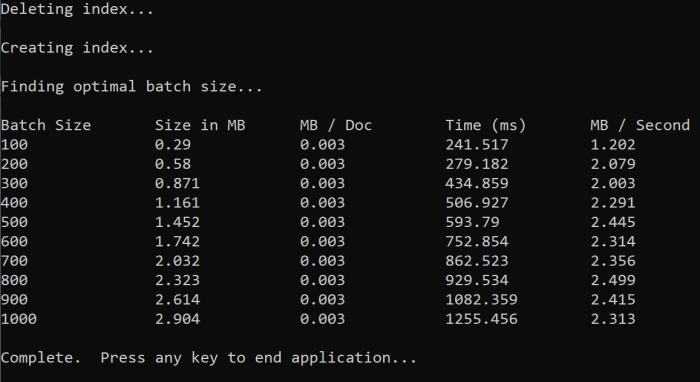
Identifique qual tamanho de lote é mais eficiente e, em seguida, use esse tamanho de lote na próxima etapa do tutorial. Você pode ver um platô em MB/s em diferentes tamanhos de lote.
Etapa 5: indexar os dados
Agora que você identificou o tamanho do lote que pretende usar, o próximo passo é começar a indexar os dados. Para indexar dados de forma eficiente, este exemplo:
- usa vários threads/workers
- implementa uma estratégia de repetição de backoff exponencial
Descomente as linhas 41 a 49 e, em seguida, execute novamente o programa. Nessa execução, o exemplo gera e envia lotes de documentos, até 100.000 se você executar o código sem alterar os parâmetros.
Usar vários threads/trabalhadores
Para aproveitar ao máximo as velocidades de indexação do Azure AI Search, use vários threads para enviar solicitações de indexação em lote simultaneamente para o serviço.
Várias das principais considerações mencionadas anteriormente podem afetar o número ideal de threads. Você pode modificar este exemplo e testar com diferentes contagens de threads para determinar a contagem de threads ideal para seu cenário. No entanto, desde que você tenha vários threads funcionando simultaneamente, você deve ser capaz de aproveitar a maioria dos ganhos de eficiência.
À medida que você aumenta as solicitações que chegam ao serviço de pesquisa, você pode encontrar códigos de status HTTP indicando que a solicitação não foi totalmente bem-sucedida. Durante a indexação, dois códigos de status HTTP comuns são:
- 503 Serviço indisponível: Este erro significa que o sistema está sob carga pesada e o seu pedido não pode ser processado neste momento.
- 207 Multi-Status: Este erro significa que alguns documentos foram bem-sucedidos, mas pelo menos um falhou.
Implementar uma estratégia de repetição de backoff exponencial
Se ocorrer uma falha, as solicitações devem ser repetidas usando uma estratégia de repetição de backoff exponencial.
O SDK .NET do Azure AI Search tenta automaticamente 503s e outras solicitações com falha, mas você deve implementar sua própria lógica para repetir 207s. Ferramentas de código aberto como Polly podem ser úteis em uma estratégia de repetição.
Neste exemplo, implementamos nossa própria estratégia de repetição de backoff exponencial. Começamos definindo algumas variáveis, incluindo o maxRetryAttempts e o inicial delay para uma solicitação com falha:
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Os resultados da operação de indexação são armazenados na variável IndexDocumentResult result. Essa variável é importante porque permite verificar se algum documento do lote falhou, como mostra o exemplo a seguir. Se houver uma falha parcial, um novo lote será criado com base na ID dos documentos com falha.
RequestFailedException As exceções também devem ser detetadas, pois indicam que o pedido falhou completamente e também devem ser repetidas.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
A partir daqui, envolva o código de backoff exponencial em uma função para que ele possa ser facilmente chamado.
Outra função é então criada para gerenciar os threads ativos. Para simplificar, essa função não está incluída aqui, mas pode ser encontrada em ExponentialBackoff.cs. A função pode ser chamada com o seguinte comando, onde hotels estão os dados que queremos carregar, 1000 é o tamanho do lote e 8 é o número de threads simultâneos:
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
Quando você executa a função, você deve ver uma saída:
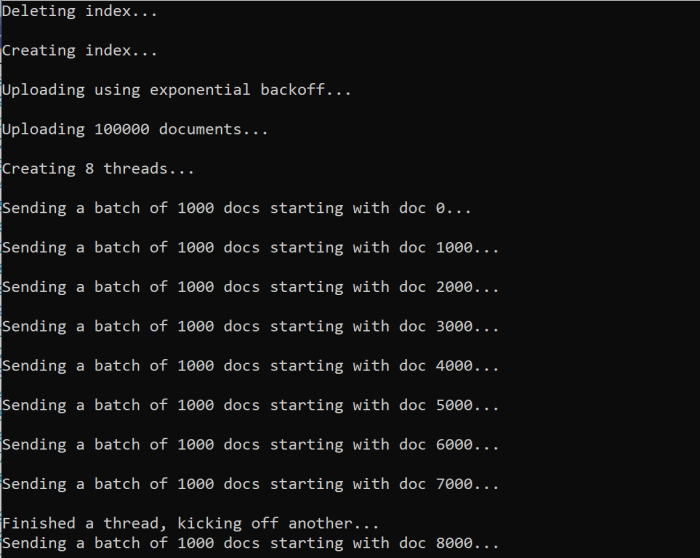
Quando um lote de documentos falha, um erro é impresso indicando a falha e que o lote está sendo repetido:
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Depois que a função terminar de ser executada, você poderá verificar se todos os documentos foram adicionados ao índice.
Passo 6: Explore o índice
Você pode explorar o índice de pesquisa preenchido depois que o programa for executado programaticamente ou usando o Gerenciador de Pesquisa no portal do Azure.
Programaticamente
Há duas opções principais para verificar o número de documentos em um índice: a API Count Documents e a Get Index Statistics API. Ambos os caminhos requerem tempo para serem processados, por isso não se assuste se o número de documentos devolvidos for inicialmente inferior ao esperado.
Contar documentos
A operação Contar documentos recupera uma contagem do número de documentos em um índice de pesquisa:
long indexDocCount = await searchClient.GetDocumentCountAsync();
Obter estatísticas de índice
A operação Obter estatísticas de índice retorna uma contagem de documentos para o índice atual, além do uso de armazenamento. As estatísticas de índice levam mais tempo do que a contagem de documentos para serem atualizadas.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Portal do Azure
No portal do Azure, no painel de navegação esquerdo, localize o índice de indexação otimizada na lista Índices .

A contagem de documentos e o tamanho do armazenamento são baseados na API Get Index Statistics e podem levar vários minutos para serem atualizados.
Repor e executar novamente
Nos estágios experimentais iniciais de desenvolvimento, a abordagem mais prática para iteração de design é excluir os objetos da Pesquisa de IA do Azure e permitir que seu código os reconstrua. Os nomes dos recursos são exclusivos. Quando elimina um objeto, pode recriá-lo com o mesmo nome.
O código de exemplo para este tutorial verifica os índices existentes e os exclui para que você possa executar novamente o código.
Você também pode usar o portal do Azure para excluir índices.
Clean up resources (Limpar recursos)
Quando estiver a trabalhar na sua própria subscrição, no final de um projeto, é uma boa ideia remover os recursos de que já não necessita. Os recursos que deixar em execução podem custar dinheiro. Pode eliminar recursos individualmente ou eliminar o grupo de recursos para eliminar todo o conjunto de recursos.
Você pode localizar e gerenciar recursos no portal do Azure, usando o link Todos os recursos ou Grupos de recursos no painel de navegação esquerdo.
Próximo passo
Para saber mais sobre a indexação de dados de grandes quantidades, tente o tutorial a seguir.