Migração: pools SQL dedicados do Azure Synapse Analytics para malha
Aplica-se a:✅ Armazém no Microsoft Fabric
Este artigo detalha a estratégia, as considerações e os métodos de migração de data warehousing nos pools SQL dedicados do Azure Synapse Analytics para o Microsoft Fabric Warehouse.
Introdução à migração
Como a Microsoft apresentou o Microsoft Fabric, uma solução de análise SaaS tudo-em-um para empresas que oferece um conjunto abrangente de serviços, incluindo Data Factory, Engenharia de Dados, Data Warehousing, Ciência de Dados, Inteligência em Tempo Real e Power BI.
Este artigo se concentra em opções para migração de esquema (DDL), migração de código de banco de dados (DML) e migração de dados. A Microsoft oferece várias opções, e aqui discutimos cada opção em detalhes e fornecemos orientação sobre qual dessas opções você deve considerar para o seu cenário. Este artigo usa o benchmark do setor TPC-DS para ilustração e testes de desempenho. Seu resultado real pode variar dependendo de muitos fatores, incluindo tipo de dados, tipos de dados, largura das tabelas, latência da fonte de dados, etc.
Prepare para a migração
Planeje cuidadosamente seu projeto de migração antes de começar e certifique-se de que seu esquema, código e dados sejam compatíveis com o Fabric Warehouse. Existem algumas limitações que você precisa considerar. Quantifique o trabalho de refatoração dos itens incompatíveis, bem como quaisquer outros recursos necessários antes da entrega da migração.
Outro objetivo importante do planejamento é ajustar seu design para garantir que sua solução aproveite ao máximo o alto desempenho de consulta que o Fabric Warehouse foi projetado para fornecer. Projetar armazéns de dados para escala introduz padrões de design exclusivos, de modo que as abordagens tradicionais nem sempre são as melhores. Analise as diretrizes de desempenho do Fabric Warehouse, porque, embora alguns ajustes de design possam ser feitos após a migração, fazer alterações no início do processo economizará tempo e esforço. A migração de uma tecnologia/ambiente para outro é sempre um grande esforço.
O diagrama a seguir mostra o Ciclo de Vida da Migração listando os principais pilares que consistem em Avaliar e Avaliar, Planejar e Projetar, Migrar, Monitorar e Governar, Otimizar e Modernizar os pilares com as tarefas associadas em cada pilar para planejar e preparar a migração suave.

Runbook para migração
Considere as atividades a seguir como um runbook de planejamento para sua migração de pools SQL dedicados Synapse para o Fabric Warehouse.
- Avaliar e avaliar
- Identificar objetivos e motivações. Estabeleça resultados claros desejados.
- Decifrar, avaliar e fazer a linha de base da arquitetura existente.
- Identificar as principais partes interessadas e patrocinadores.
- Defina o escopo do que deve ser migrado.
- Comece pequeno e simples, prepare-se para várias pequenas migrações.
- Comece a acompanhar e documentar todas as etapas do processo.
- Crie um inventário de dados e processos para migração.
- Defina as alterações do modelo de dados (se houver).
- Configure o espaço de trabalho de malha.
- Qual é o seu conjunto de competências/preferência?
- Automatize sempre que possível.
- Use as ferramentas e os recursos internos do Azure para reduzir o esforço de migração.
- Treine a equipe logo no início da nova plataforma.
- Identifique as necessidades de aperfeiçoamento e os ativos de treinamento, incluindo o Microsoft Learn.
- Planejar e projetar
- Defina a arquitetura desejada.
- Selecione o método/ferramentas para a migração para realizar as seguintes tarefas:
- Extração de dados da fonte.
- Conversão de esquema (DDL), incluindo metadados para tabelas e exibições
- Ingestão de dados, incluindo dados históricos.
- Se necessário, reprojete o modelo de dados usando o novo desempenho e escalabilidade da plataforma.
- Migração de código de banco de dados (DML).
- Migre ou refatore procedimentos armazenados e processos de negócios.
- Inventarie e extraia os recursos de segurança e as permissões de objeto da fonte.
- Projetar e planejar a substituição/modificação de processos ETL/ELT existentes para carga incremental.
- Crie processos ETL/ELT paralelos para o novo ambiente.
- Prepare um plano de migração detalhado.
- Mapeie o estado atual para o novo estado desejado.
- Migrar
- Execute a migração de esquema, dados e código.
- Extração de dados da fonte.
- Conversão de esquema (DDL)
- Ingestão de dados
- Migração de código de banco de dados (DML).
- Se necessário, dimensione temporariamente os recursos dedicados do pool SQL para ajudar na velocidade da migração.
- Aplique segurança e permissões.
- Migre processos ETL/ELT existentes para carga incremental.
- Migre ou refatore processos de carga incremental ETL/ELT.
- Teste e compare processos de carga de incremento paralelos.
- Adapte o plano de migração detalhado conforme necessário.
- Execute a migração de esquema, dados e código.
- Monitorar e governar
- Execute em paralelo, compare com seu ambiente de origem.
- Teste aplicativos, plataformas de business intelligence e ferramentas de consulta.
- Avalie e otimize o desempenho da consulta.
- Monitore e gerencie custos, segurança e desempenho.
- Benchmark e avaliação de governança.
- Execute em paralelo, compare com seu ambiente de origem.
- Otimizar e modernizar
- Quando a empresa estiver confortável, faça a transição de aplicativos e plataformas de relatórios principais para o Fabric.
- Aumente ou diminua os recursos à medida que a carga de trabalho muda do Azure Synapse Analytics para o Microsoft Fabric.
- Crie um modelo repetível a partir da experiência adquirida para migrações futuras. Iterar.
- Identificar oportunidades de otimização de custos, segurança, escalabilidade e excelência operacional
- Identifique oportunidades para modernizar seu patrimônio de dados com os recursos mais recentes do Fabric.
- Quando a empresa estiver confortável, faça a transição de aplicativos e plataformas de relatórios principais para o Fabric.
'Levantar e mudar' ou modernizar?
Em geral, há dois tipos de cenários de migração, independentemente da finalidade e do escopo da migração planejada: lift and shift no estado em que se encontra ou uma abordagem em fases que incorpora alterações de arquitetura e código.
Migração lift-and-shift
Em uma migração de elevação e deslocamento, um modelo de dados existente é migrado com pequenas alterações no novo Fabric Warehouse. Essa abordagem minimiza o risco e o tempo de migração, reduzindo o novo trabalho necessário para obter os benefícios da migração.
A migração de elevação e deslocamento é uma boa opção para estes cenários:
- Você tem um ambiente existente com um pequeno número de data marts para migrar.
- Você tem um ambiente existente com dados que já estão em um esquema de estrela ou floco de neve bem projetado.
- Você está sob pressão de tempo e custo para mudar para o Fabric Warehouse.
Em resumo, essa abordagem funciona bem para as cargas de trabalho otimizadas com seu ambiente atual de pools SQL dedicados Synapse e, portanto, não requer grandes alterações na malha.
Modernize-se em uma abordagem faseada com mudanças arquitetônicas
Se um data warehouse herdado tiver evoluído durante um longo período de tempo, talvez seja necessário reprojetá-lo para manter os níveis de desempenho necessários.
Você também pode querer redesenhar a arquitetura para aproveitar os novos mecanismos e recursos disponíveis no Fabric Workspace.
Diferenças de design: pools SQL dedicados Synapse e Fabric Warehouse
Considere as seguintes diferenças de armazenamento de dados do Azure Synapse e do Microsoft Fabric, comparando pools SQL dedicados com o Fabric Warehouse.
Considerações sobre a tabela
Quando você migra tabelas entre ambientes diferentes, normalmente apenas os dados brutos e os metadados são migrados fisicamente. Outros elementos de banco de dados do sistema de origem, como índices, geralmente não são migrados porque podem ser desnecessários ou implementados de forma diferente no novo ambiente.
As otimizações de desempenho no ambiente de origem, como índices, indicam onde você pode adicionar otimização de desempenho em um novo ambiente, mas agora o Fabric cuida disso automaticamente para você.
Considerações sobre o T-SQL
Há várias diferenças de sintaxe DML (Data Manipulation Language) a serem observadas. Consulte a área de superfície T-SQL no Microsoft Fabric. Considere também uma avaliação de código ao escolher o(s) método(s) de migração para o código do banco de dados (DML).
Dependendo das diferenças de paridade no momento da migração, talvez seja necessário reescrever partes do código DML do T-SQL.
Diferenças de mapeamento de tipo de dados
Há várias diferenças de tipo de dados no Fabric Warehouse. Para obter mais informações, consulte Tipos de dados no Microsoft Fabric.
A tabela a seguir fornece o mapeamento de tipos de dados suportados de pools SQL dedicados Synapse para o Fabric Warehouse.
| Pools SQL dedicados Synapse | Armazém de Tecidos |
|---|---|
| dinheiro | decimal(19,4) |
| dinheiro pequeno | decimais(10,4) |
| PequenoDateTime | datetime2 |
| datetime | datetime2 |
| Nchar | char |
| Nvarchar | varchar |
| tinyint | smallint |
| binário | Varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 não armazena as informações de deslocamento de fuso horário extra que são armazenadas em. Como o tipo de dados datetimeoffset não é suportado atualmente no Fabric Warehouse, os dados de deslocamento de fuso horário precisariam ser extraídos em uma coluna separada.
Esquema, código e métodos de migração de dados
Analise e identifique qual dessas opções se encaixa no seu cenário, nos conjuntos de habilidades da equipe e nas características dos seus dados. A(s) opção(ões) escolhida(s) dependerá(ão) da sua experiência, preferência e dos benefícios de cada uma das ferramentas. Nosso objetivo é continuar a desenvolver ferramentas de migração que mitiguem o atrito e a intervenção manual para tornar essa experiência de migração perfeita.
Esta tabela resume informações para esquema de dados (DDL), código de banco de dados (DML) e métodos de migração de dados. Expandiremos ainda mais cada cenário mais adiante neste artigo, vinculado na coluna Opção .
| Número da opção | Opção | O que faz | Habilidade/Preferência | Cenário |
|---|---|---|---|---|
| 1 | Data Factory | Conversão de esquema (DDL) Extração de dados Ingestão de dados |
ADF/Gasoduto | Esquema tudo em um simplificado (DDL) e migração de dados. Recomendado para tabelas de dimensões. |
| 2 | Data Factory com partição | Conversão de esquema (DDL) Extração de dados Ingestão de dados |
ADF/Gasoduto | Usando opções de particionamento para aumentar o paralelismo de leitura/gravação fornecendo taxa de transferência de 10x vs opção 1, recomendada para tabelas de fatos. |
| 3 | Data Factory com código acelerado | Conversão de esquema (DDL) | ADF/Gasoduto | Converta e migre o esquema (DDL) primeiro, depois use o CETAS para extrair e o COPY/Data Factory para ingerir dados para um desempenho de ingestão geral ideal. |
| 4 | Código acelerado de procedimentos armazenados | Conversão de esquema (DDL) Extração de dados Avaliação de código |
T-SQL | Usuário SQL usando IDE com controle mais granular sobre quais tarefas eles querem trabalhar. Use COPY/Data Factory para ingerir dados. |
| 5 | Extensão do Projeto de Banco de Dados SQL para o Azure Data Studio | Conversão de esquema (DDL) Extração de dados Avaliação de código |
Projeto SQL | Projeto de Banco de Dados SQL para implantação com a integração da opção 4. Use COPY ou Data Factory para ingerir dados. |
| 6 | CRIAR TABELA EXTERNA COMO SELECIONAR (CETAS) | Extração de dados | T-SQL | Extração de dados econômica e de alto desempenho para o Azure Data Lake Storage (ADLS) Gen2. Use COPY/Data Factory para ingerir dados. |
| 7 | Migrar usando dbt | Conversão de esquema (DDL) conversão de código de banco de dados (DML) |
DBT | Os usuários dbt existentes podem usar o adaptador dbt Fabric para converter suas DDL e DML. Em seguida, você deve migrar dados usando outras opções nesta tabela. |
Escolha uma carga de trabalho para a migração inicial
Ao decidir por onde começar no pool SQL dedicado do Synapse para o projeto de migração do Fabric Warehouse, escolha uma área de carga de trabalho onde você possa:
- Comprove a viabilidade da migração para o Fabric Warehouse oferecendo rapidamente os benefícios do novo ambiente. Comece pequeno e simples, prepare-se para várias pequenas migrações.
- Permita que sua equipe técnica interna ganhe experiência relevante com os processos e ferramentas que eles usam quando migram para outras áreas.
- Crie um modelo para migrações adicionais que seja específico para o ambiente Synapse de origem e as ferramentas e processos em vigor para ajudar.
Gorjeta
Crie um inventário de objetos que precisam ser migrados e documente o processo de migração do início ao fim, para que ele possa ser repetido para outros pools SQL dedicados ou cargas de trabalho.
O volume de dados migrados em uma migração inicial deve ser grande o suficiente para demonstrar os recursos e benefícios do ambiente do Fabric Warehouse, mas não muito grande para demonstrar valor rapidamente. Um tamanho na faixa de 1-10 terabytes é típico.
Migração com o Fabric Data Factory
Nesta seção, discutimos as opções que usam o Data Factory para a persona low-code/no-code que estão familiarizadas com o Azure Data Factory e o Synapse Pipeline. Esta opção de arrastar e soltar a interface do usuário fornece uma etapa simples para converter a DDL e migrar os dados.
O Fabric Data Factory pode executar as seguintes tarefas:
- Converta o esquema (DDL) em sintaxe do Fabric Warehouse.
- Crie o esquema (DDL) no Fabric Warehouse.
- Migre os dados para o Fabric Warehouse.
Opção 1. Migração de esquema/dados - Assistente de cópia e atividade de cópia ForEach
Esse método usa o Assistente de Cópia do Data Factory para se conectar ao pool SQL dedicado de origem, converter a sintaxe DDL do pool SQL dedicado em Malha e copiar dados para o Fabric Warehouse. Você pode selecionar 1 ou mais tabelas de destino (para o conjunto de dados TPC-DS há 22 tabelas). Ele gera o ForEach para percorrer a lista de tabelas selecionadas na interface do usuário e gerar 22 threads paralelos de atividade de cópia.
- 22 consultas SELECT (uma para cada tabela selecionada) foram geradas e executadas no pool SQL dedicado.
- Certifique-se de ter a DWU e a classe de recurso apropriadas para permitir que as consultas geradas sejam executadas. Para esse caso, você precisa de um mínimo de DWU1000 para permitir um máximo de 32 consultas para lidar com
staticrc1022 consultas enviadas. - A cópia direta de dados do Data Factory do pool SQL dedicado para o Fabric Warehouse requer preparação. O processo de ingestão consistiu em duas fases.
- A primeira fase consiste em extrair os dados do pool SQL dedicado para o ADLS e é chamada de preparação.
- A segunda fase consiste em ingerir os dados do preparo no Fabric Warehouse. A maioria dos tempos de ingestão de dados está na fase de estadiamento. Em resumo, o estadiamento tem um enorme impacto no desempenho da ingestão.
Utilização recomendada
Usar o Assistente de Cópia para gerar um ForEach fornece uma interface do usuário simples para converter DDL e ingerir as tabelas selecionadas do pool SQL dedicado para o Fabric Warehouse em uma etapa.
No entanto, não é ideal com a taxa de transferência geral. O requisito de usar preparo, a necessidade de paralelizar leitura e gravação para a etapa "Source to Stage" são os principais fatores para a latência de desempenho. Recomenda-se usar essa opção apenas para tabelas de dimensão.
Opção 2. DDL/Migração de dados - Pipeline de dados usando a opção de partição
Para abordar a melhoria da taxa de transferência para carregar tabelas de fatos maiores usando o pipeline de dados de malha, é recomendável usar a opção Copiar atividade para cada tabela de fatos com partição. Isso proporciona o melhor desempenho com a atividade de cópia.
Você tem a opção de usar o particionamento físico da tabela de origem, se disponível. Se a tabela não tiver particionamento físico, você deverá especificar a coluna de partição e fornecer valores min/max para usar o particionamento dinâmico. Na captura de tela a seguir, as opções de origem do pipeline de dados estão especificando um intervalo dinâmico de partições com base na ws_sold_date_sk coluna.
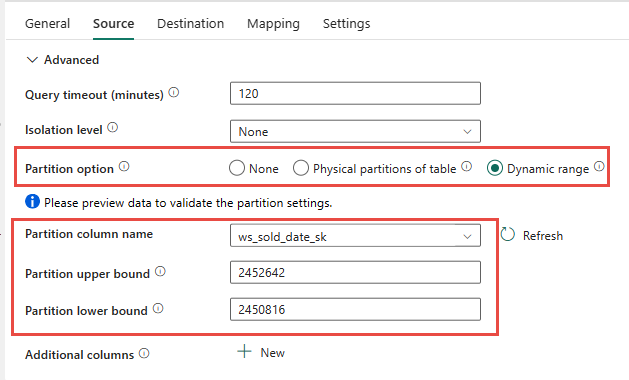
Embora o uso da partição possa aumentar a taxa de transferência com a fase de preparo, há considerações para fazer os ajustes apropriados:
- Dependendo do seu intervalo de partições, ele pode potencialmente usar todos os slots de simultaneidade, pois pode gerar mais de 128 consultas no pool SQL dedicado.
- É necessário dimensionar para um mínimo de DWU6000 para permitir que todas as consultas sejam executadas.
- Por exemplo, para a tabela TPC-DS
web_sales, 163 consultas foram enviadas ao pool SQL dedicado. Em DWU6000, 128 consultas foram executadas enquanto 35 consultas estavam na fila. - A partição dinâmica seleciona automaticamente a partição de intervalo. Nesse caso, um intervalo de 11 dias para cada consulta SELECT enviada ao pool SQL dedicado. Por exemplo:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Utilização recomendada
Para tabelas de fatos, recomendamos o uso do Data Factory com a opção de particionamento para aumentar a taxa de transferência.
No entanto, o aumento das leituras paralelizadas requer que o pool SQL dedicado seja dimensionado para DWU mais alto para permitir que as consultas de extração sejam executadas. Aproveitando o particionamento, a taxa é melhorada 10x em relação a nenhuma opção de partição. Você pode aumentar a DWU para obter uma taxa de transferência adicional por meio de recursos de computação, mas o pool SQL dedicado tem um máximo de 128 consultas ativas permitidas.
Nota
Para obter mais informações sobre o mapeamento Synapse DWU to Fabric, consulte Blog: Mapeando pools SQL dedicados do Azure Synapse para computação de data warehouse de malha.
Opção 3. Migração DDL - Assistente de cópia para cada atividade de cópia
As duas opções anteriores são ótimas opções de migração de dados para bancos de dados menores . Mas se você precisar de uma taxa de transferência mais alta, recomendamos uma opção alternativa:
- Extraia os dados do pool SQL dedicado para o ADLS, reduzindo assim a sobrecarga de desempenho do palco.
- Use o comando Data Factory ou COPY para ingerir os dados no Fabric Warehouse.
Utilização recomendada
Você pode continuar a usar o Data Factory para converter seu esquema (DDL). Usando o Assistente de Cópia, você pode selecionar a tabela específica ou Todas as tabelas. Por design, isso migra o esquema e os dados em uma etapa, extraindo o esquema sem linhas, usando a condição false, TOP 0 na instrução query.
O exemplo de código a seguir aborda a migração de esquema (DDL) com o Data Factory.
Exemplo de código: migração de esquema (DDL) com o Data Factory
Você pode usar os Pipelines de Dados de Malha para migrar facilmente DDL (esquemas) para objetos de tabela de qualquer Banco de Dados SQL do Azure de origem ou pool SQL dedicado. Esse pipeline de dados migra pelo esquema (DDL) das tabelas de pool SQL dedicadas de origem para o Fabric Warehouse.
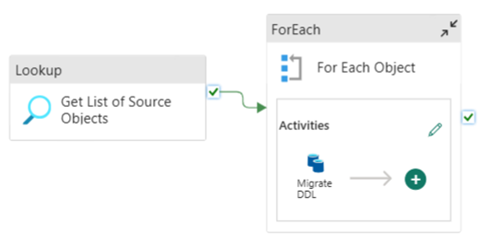
Projeto de tubulação: parâmetros
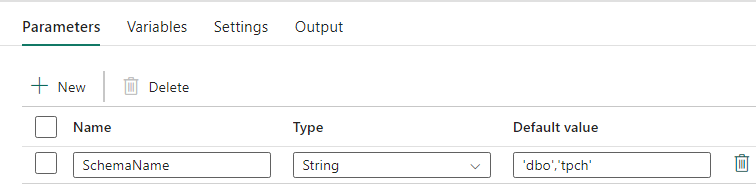
Este Pipeline de Dados aceita um parâmetro SchemaName, que permite especificar quais esquemas devem ser migrados. O dbo esquema é o padrão.
No campo Valor padrão, insira uma lista delimitada por vírgulas do esquema de tabela indicando quais esquemas migrar: 'dbo','tpch' para fornecer dois esquemas dbo e tpch.
Design de pipeline: atividade de pesquisa
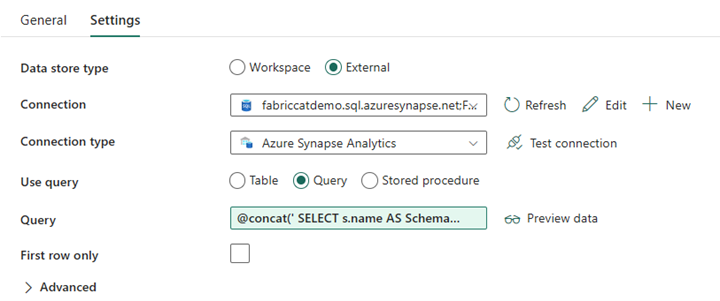
Crie uma Atividade de Pesquisa e defina a Conexão para apontar para o banco de dados de origem.
Na guia Configurações:
Defina Tipo de armazenamento de dados como Externo.
A conexão é o pool SQL dedicado do Azure Synapse. O tipo de conexão é o Azure Synapse Analytics.
Usar consulta é definido como Consulta.
O campo Consulta precisa ser criado usando uma expressão dinâmica, permitindo que o parâmetro SchemaName seja usado em uma consulta que retorna uma lista de tabelas de origem de destino. Selecione Consulta e, em seguida, selecione Adicionar conteúdo dinâmico.
Essa expressão dentro da Atividade de Pesquisa gera uma instrução SQL para consultar as exibições do sistema para recuperar uma lista de esquemas e tabelas. Faz referência ao parâmetro SchemaName para permitir a filtragem em esquemas SQL. A saída disso é uma matriz de esquema SQL e tabelas que serão usadas como entrada na atividade ForEach.
Use o código a seguir para retornar uma lista de todas as tabelas de usuário com seu nome de esquema.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
Design de pipeline: ForEach Loop
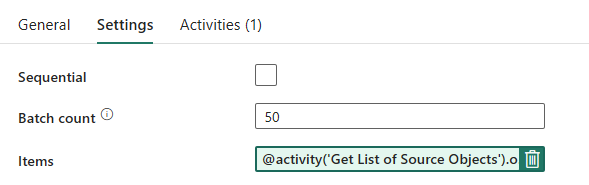
Para o ForEach Loop, configure as seguintes opções na guia Configurações :
- Desative Sequencial para permitir que várias iterações sejam executadas simultaneamente.
- Defina Contagem de lotes como
50, limitando o número máximo de iterações simultâneas. - O campo Itens precisa usar conteúdo dinâmico para fazer referência à saída da Atividade de Pesquisa. Use o seguinte trecho de código:
@activity('Get List of Source Objects').output.value
Design de pipeline: Copiar atividade dentro do loop ForEach
Dentro da Atividade ForEach, adicione uma Atividade de cópia. Esse método usa a linguagem de expressão dinâmica dentro de pipelines de dados para criar um SELECT TOP 0 * FROM <TABLE> para migrar somente o esquema sem dados para um Fabric Warehouse.
Na guia Origem:
- Defina Tipo de armazenamento de dados como Externo.
- A conexão é o pool SQL dedicado do Azure Synapse. O tipo de conexão é o Azure Synapse Analytics.
- Defina Usar consulta como consulta.
- No campo Consulta, cole na consulta de conteúdo dinâmico e use esta expressão que retornará zero linhas, somente o esquema da tabela:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

Na guia Destino:
- Defina Tipo de armazenamento de dados como Espaço de trabalho.
- O tipo de armazenamento de dados Espaço de trabalho é Data Warehouse e o Data Warehouse é definido como Armazém de malha.
- O esquema da tabela de destino e o nome da tabela são definidos usando conteúdo dinâmico.
- Schema refere-se ao campo da iteração atual, SchemaName com o trecho:
@item().SchemaName - Table está fazendo referência a TableName com o trecho:
@item().TableName
- Schema refere-se ao campo da iteração atual, SchemaName com o trecho:

Projeto da tubulação: Pia
Para Sink, aponte para o Warehouse e faça referência ao Esquema de origem e ao nome da tabela.
Depois de executar esse pipeline, você verá seu Data Warehouse preenchido com cada tabela em sua origem, com o esquema adequado.
Migração usando procedimentos armazenados no pool SQL dedicado Synapse
Essa opção usa procedimentos armazenados para executar a migração de malha.
Você pode obter os exemplos de código em microsoft/fabric-migration no GitHub.com. Este código é compartilhado como código aberto, então sinta-se à vontade para contribuir para colaborar e ajudar a comunidade.
O que os procedimentos armazenados de migração podem fazer:
- Converta o esquema (DDL) em sintaxe do Fabric Warehouse.
- Crie o esquema (DDL) no Fabric Warehouse.
- Extraia dados do pool SQL dedicado Synapse para ADLS.
- Sinalizar sintaxe de malha sem suporte para códigos T-SQL (procedimentos armazenados, funções, exibições).
Utilização recomendada
Esta é uma ótima opção para quem:
- Estão familiarizados com T-SQL.
- Deseja usar um ambiente de desenvolvimento integrado, como o SQL Server Management Studio (SSMS).
- Querem um controle mais granular sobre quais tarefas eles querem trabalhar.
Você pode executar o procedimento armazenado específico para a conversão de esquema (DDL), extração de dados ou avaliação de código T-SQL.
Para a migração de dados, você precisará usar COPY INTO ou Data Factory para ingerir os dados no Fabric Warehouse.
Migrar usando projetos de banco de dados SQL
O Microsoft Fabric Data Warehouse tem suporte na extensão Projetos do Banco de Dados SQL disponível dentro do Azure Data Studio e do Visual Studio Code.
Esta extensão está disponível dentro do Azure Data Studio e do Visual Studio Code. Esse recurso permite recursos para controle do código-fonte, teste de banco de dados e validação de esquema.
Para obter mais informações sobre o controle do código-fonte para armazéns no Microsoft Fabric, incluindo pipelines de integração e implantação do Git, consulte Controle do código-fonte com depósito.
Utilização recomendada
Essa é uma ótima opção para aqueles que preferem usar o SQL Database Project para sua implantação. Essa opção essencialmente integrou os procedimentos armazenados de migração de malha no projeto de banco de dados SQL para fornecer uma experiência de migração perfeita.
Um projeto de banco de dados SQL pode:
- Converta o esquema (DDL) em sintaxe do Fabric Warehouse.
- Crie o esquema (DDL) no Fabric Warehouse.
- Extraia dados do pool SQL dedicado Synapse para ADLS.
- Sinalizar sintaxe sem suporte para códigos T-SQL (procedimentos armazenados, funções, exibições).
Para a migração de dados, você usará COPY INTO ou Data Factory para ingerir os dados no Fabric Warehouse.
Adicionando à capacidade de suporte do Azure Data Studio do Microsoft Fabric, a equipe CAT do Microsoft Fabric forneceu um conjunto de scripts do PowerShell para lidar com a extração, criação e implantação de esquema (DDL) e código de banco de dados (DML) por meio de um projeto de banco de dados SQL. Para obter um passo a passo sobre como usar o projeto do Banco de dados SQL com nossos scripts úteis do PowerShell, consulte microsoft/fabric-migration on GitHub.com.
Para obter mais informações sobre projetos do Banco de dados SQL, consulte Introdução à extensão Projetos do Banco de dados SQL e Criar e publicar um projeto.
Migração de dados com o CETAS
O comando T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) fornece o método mais econômico e ideal para extrair dados de pools SQL dedicados Synapse para o Azure Data Lake Storage (ADLS) Gen2.
O que o CETAS pode fazer:
- Extraia dados para ADLS.
- Essa opção exige que os usuários criem o esquema (DDL) no Fabric Warehouse antes de ingerir os dados. Considere as opções neste artigo para migrar esquema (DDL).
As vantagens desta opção são:
- Apenas uma única consulta por tabela é enviada em relação ao pool SQL dedicado Synapse de origem. Isso não usará todos os slots de simultaneidade e, portanto, não bloqueará a produção simultânea de ETL/consultas de clientes.
- O dimensionamento para DWU6000 não é necessário, pois apenas um único slot de simultaneidade é usado para cada tabela, para que os clientes possam usar DWUs mais baixas.
- A extração é executada em paralelo em todos os nós de computação, e esta é a chave para a melhoria do desempenho.
Utilização recomendada
Use CETAS para extrair os dados para ADLS como arquivos Parquet. Os arquivos Parquet oferecem a vantagem de armazenamento de dados eficiente com compactação colunar que levará menos largura de banda para se mover pela rede. Além disso, como o Fabric armazenou os dados como formato de parquet Delta, a ingestão de dados será 2,5x mais rápida em comparação com o formato de arquivo de texto, uma vez que não há conversão para o formato Delta durante a ingestão.
Para aumentar o rendimento do CETAS:
- Adicione operações CETAS paralelas, aumentando o uso de slots de simultaneidade, mas permitindo mais taxa de transferência.
- Dimensione o DWU no pool SQL dedicado do Synapse.
Migração via dbt
Nesta seção, discutimos a opção dbt para os clientes que já estão usando dbt em seu ambiente atual de pool SQL dedicado Synapse.
O que o dbt pode fazer:
- Converta o esquema (DDL) em sintaxe do Fabric Warehouse.
- Crie o esquema (DDL) no Fabric Warehouse.
- Converta o código do banco de dados (DML) em sintaxe de malha.
O framework dbt gera DDL e DML (scripts SQL) em tempo real a cada execução. Com arquivos de modelo expressos em instruções SELECT, o DDL/DML pode ser traduzido instantaneamente para qualquer plataforma de destino, alterando o perfil (cadeia de conexão) e o tipo de adaptador.
Utilização recomendada
A estrutura dbt é uma abordagem code-first. Os dados devem ser migrados usando as opções listadas neste documento, como CETAS ou COPY/Data Factory.
O adaptador dbt para o Microsoft Fabric Data Warehouse permite que os projetos dbt existentes destinados a diferentes plataformas, como pools SQL dedicados Synapse, Snowflake, Databricks, Google Big Query ou Amazon Redshift, sejam migrados para um Fabric Warehouse com uma simples alteração de configuração.
Para começar a usar um projeto dbt direcionado ao Fabric Warehouse, consulte Tutorial: Configurar o dbt para o Fabric Data Warehouse. Este documento também lista uma opção para mover entre diferentes armazéns / plataformas.
Ingestão de dados no Fabric Warehouse
Para ingestão no Fabric Warehouse, use COPY INTO ou Fabric Data Factory, dependendo da sua preferência. Ambos os métodos são as opções recomendadas e de melhor desempenho, pois têm taxa de transferência de desempenho equivalente, dado o pré-requisito de que os arquivos já sejam extraídos para o Azure Data Lake Storage (ADLS) Gen2.
Vários fatores a serem observados para que você possa projetar seu processo para obter o máximo desempenho:
- Com o Fabric, não há qualquer contenção de recursos ao carregar várias tabelas do ADLS para o Fabric Warehouse simultaneamente. Como resultado, não há degradação de desempenho ao carregar threads paralelos. A taxa de transferência máxima de ingestão será limitada apenas pelo poder de computação da sua capacidade de malha.
- O gerenciamento de carga de trabalho de malha fornece separação de recursos alocados para carga e consulta. Não há contenção de recursos enquanto consultas e carregamento de dados são executados ao mesmo tempo.