Exportar dados do Dataverse no formato Delta Lake
Utilize o Azure Synapse Link for Dataverse para exportar os dados do Microsoft Dataverse para o Azure Synapse Analytics no formato Delta Lake. Em seguida, explore os dados e acelere o tempo para obter informações. Este artigo fornece as seguintes informações e mostra como efetuar as seguintes tarefas:
- Fornece explicações sobre Delta Lake e Parquet e porque motivo deve exportar dados neste formato.
- Exporte os seus dados do Dataverse para a sua área de trabalho do Azure Synapse Analytics no Formato Delta Lake com o Azure Synapse Link.
- Monitorize o seu Azure Synapse Link e a conversão de dados.
- Veja os seus dados a partir do Azure Data Lake Storage Gen2.
- Veja os dados a partir da Área de Trabalho do Synapse.
Importante
- Se estiver a atualizar a versão de CSV para Delta Lake com vistas personalizadas existentes, recomendamos a atualização do script para substituir todas as tabelas partitioned para non_partitioned. Faça-o procurando instâncias de
_partitionede substitua-as por uma cadeia vazia. - Para configuração do Dataverse, só a opção de acrescentar está ativada por predefinição para exportar dados CSV no modo
appendonly. Mas a tabela Delta Lake terá uma estrutura de atualização no local, porque a conversão Delta Lake é apresentada num processo de união periódica. - Não existem custos incorridos com a criação de conjuntos do Spark. Só são incorridos encargos depois de uma tarefa Spark ser executada no conjunto do Spark de destino e a instância do Spark ser instantânea a pedido. Estes custos estão relacionados com a utilização do Spark do Azure Synapse workspace e são faturados mensalmente. O custo da realização de cálculo do Spark depende principalmente do intervalo de tempo para atualização incremental e dos volumes de dados. Mais informações: Preços do Azure Synapse Analytics
- É importante ter em conta estes custos adicionais quando optar por utilizar esta caraterística, uma vez que não são opcionais e têm de ser pagos para continuar a utilizar esta caraterística.
- O fim de vida anunciado (EOLA) para o Runtime do Azure Synapse para o Apache Spark 3.1 foi anunciado a 26 de janeiro de 2023. De acordo com a política do ciclo de vida do Synapse para o Apache Spark, o runtime do Azure Synapse para o Apache Spark 3.1 será preterido e desativado a partir de 26 de janeiro de 2024. Após a data de EOL, os runtimes preteridos estarão indisponíveis para novos conjuntos do Spark e os fluxos de trabalho existentes não poderão ser executados. Os metadados permanecerão temporariamente na área de trabalho do Synapse. Mais informações: Runtime do Azure Synapse para o Apache Spark 3.1 (EOLA). Para ter o seu Synapse Link para o Dataverse com a atualização de versão do formato de exportação para Delta Lake para o Spark 3.3, faça uma atualização no local para os seus perfis existentes. Mais informações: Atualização no local para Apache Spark 3.3 com Delta Lake 2.2
- A partir de 4 de janeiro de 2024, apenas o Conjunto do Spark versão 3.3 será suportado na criação inicial da ligação.
Nota
O estado do Azure Synapse Link no Power Apps (make.powerapps.com) reflete o estado de conversão do Delta Lake:
Countmostra o número de registos na tabela do Delta Lake.Last synchronized onDatetime representa o último carimbo de data/hora de conversão com êxito.Sync statusé mostrado como ativo assim que a sincronização de dados e a conversão do Delta Lake forem concluídas, indicando que os dados estão prontos para consumo.
O que é o Delta Lake?
O Delta Lake é um projeto open source que permite a criação de uma arquitetura lakehouse por cima de data lakes. O Delta Lake fornece transações ACID (atomicidade, consistência, isolamento e durabilidade), processamento de metadados escaláveis e unifica a transmissão em fluxo e o processamento de dados em lote por cima de data lakes existentes. O Azure Synapse Analytics é compatível com a o Delta Lake da Linux Foundation. A versão atual do Delta Lake incluída no Azure Synapse tem suporte de idioma para Scala, PySpark e .NET. Mais informações: O que é o Delta Lake?. Também pode obter mais informações a partir do vídeo Introdução às Tabelas Delta.
O Apache Parquet é o formato de linha de base para Delta Lake, que lhe permite tirar partido dos esquemas eficientes de compressão e codificação nativos do formato. O formato de ficheiro Parquet utiliza compressão por coluna. É eficiente e poupa espaço de armazenamento. As consultas que obtêm valores de coluna específicos não necessitam de ler os dados completos da linha, melhorando assim o desempenho. Por conseguinte, o conjunto de SQL sem servidor necessita de menos tempo e menos pedidos de armazenamento para ler os dados.
Porquê usar o Delta Lake?
- Escalabilidade: o Delta Lake está construído sobre a licença Apache open source, que foi concebida para ir ao encontro das normas do setor para tratamento de workloads de processamento de dados em grande escala.
- Fiabilidade: o Delta Lake fornece transações ACID, assegurando consistência e fiabilidade dos dados mesmo face a falhas ou acesso simultâneo.
- Desempenho: o Delta Lake tira partido do formato de armazenamento em colunas do Parquet, fornecendo melhores técnicas de compressão e codificação, o que pode levar a um melhor desempenho da consulta comparativamente com os ficheiros CSV de consulta.
- Custo-benefício: o formato de ficheiro do Delta Lake é uma tecnologia de armazenamento de dados altamente comprimida que oferece potenciais poupanças significativas de armazenamento às empresas. Este formato foi concebido especificamente para otimizar o processamento de dados e, potencialmente, reduzir a quantidade total de dados processados ou em execução necessários para cálculo a pedido.
- Conformidade com a proteção de dados: o Delta Lake com Azure Synapse Link fornece ferramentas e funcionalidades incluindo a eliminação flexível e a eliminação automática, em conformidade com várias regulamentações de privacidade de dados, incluindo o Regulamento Geral sobre a Proteção de Dados (RGPD).
Como funciona o Delta Lake com o Azure Synapse Link for Dataverse?
Ao configurar um Azure Synapse Link for Dataverse pode ativar a caraterística exportar para o Delta Lake e ligar a uma área de trabalho do Synapse e ao conjunto do Spark. O Azure Synapse Link exporta as tabelas selecionadas do Dataverse em formato CSV em intervalos de tempo designados, processando-as através da uma tarefa de conversão Spark do Delta Lake. Quando este processo de conversão for concluído, os dados CSV são limpos para poupar armazenamento. Além disso, estão agendadas uma série de tarefas de manutenção para execução diária, realizando automaticamente a compactação e limpeza de processos para unir e limpar os ficheiros de dados, de modo a otimizar o armazenamento e melhorar o desempenho das consultas.
Pré-requisitos
- Dataverse: Tem de ter o direito de acesso administrador de sistema do Dataverse. Além disso, as tabelas que pretende exportar através do Azure Synapse Link devem ter a propriedade Controlar alterações ativada. Mais informações: Opções avançadas
- Azure Data Lake Storage Gen2: é necessário ter uma conta do Azure Data Lake Storage Gen2 e o direito de acesso Proprietário e Contribuidor de Dados do Blob de Armazenamento. A sua conta de armazenamento tem de ativar o Espaço de nomes hierárquico e o acesso à rede pública para a configuração inicial e para a sincronização delta. Permitir o acesso-chave à conta de armazenamento só é necessário para a configuração inicial.
- Área de trabalho do Synapse: é necessário ter uma área de trabalho do Synapse e a função Proprietário no controlo de acesso (IAM) e o direito de acesso Administrador do Synapse no Synapse Studio. A área de trabalho do Synapse tem de estar na mesma região que a sua conta do Azure Data Lake Storage Gen2. A conta de armazenamento deve ser adicionada como um serviço ligado dentro do Synapse Studio. Para criar uma área de trabalho do Synapse, aceda a Criar uma área de trabalho do Synapse.
- Um Apache Spark pool no espaço de trabalho conectado Azure Synapse com Apache Spark a Versão 3.3 usando esta configuração recomendada do Pool de Faíscas. Para obter informações sobre como criar um Conjunto do Spark, aceda a Criar novo conjunto do Apache Spark.
- O requisito mínimo da versão do Microsoft Dynamics 365 para usar esta caraterística é 9.2.22082. Mais informações: Optar ativamente pelas atualizações de acesso antecipado
Configuração recomendada do Conjunto do Spark
Esta configuração pode ser considerada um passo de programa de arranque para casos de utilização média.
- Tamanho do nó: pequeno (4 vCores / 32 GB)
- Dimensionamento automático: ativado
- Número de nós: 5 a 10
- Pausa automática: ativada
- Número de minutos de tempo inativo: 5
- Apache Spark: 3.3
- Alocar executores dinamicamente: ativado
- Número predefinido de executores: 1 a 9
Importante
Use o pool Spark exclusivamente para a operação de conversação Delta Lake com Synapse Link para Dataverse. Para obter fiabilidade e desempenho ideais, evite executar outros trabalhos do Spark usando o mesmo pool do Spark.
Ligar o Dataverse à área de trabalho do Synapse e exportar dados no formato Delta Lake
Inicie sessão no Power Apps e selecione o ambiente que pretende.
No painel de navegação esquerdo, selecione Azure Synapse Link. Se o item não estiver no painel lateral, selecione ...Mais e, em seguida, selecione o item pretendido.
Na barra de comandos, selecione + Nova ligação
Selecione Ligar à sua área de trabalho do Azure Synapse Analytics e, em seguida, selecione a Subscrição, Grupo de Recursos e Área de Trabalho.
Selecione Utilizar o conjunto do Spark para processamento e, em seguida, selecione o Conjunto do Spark e a Conta de armazenamento pré-criados.
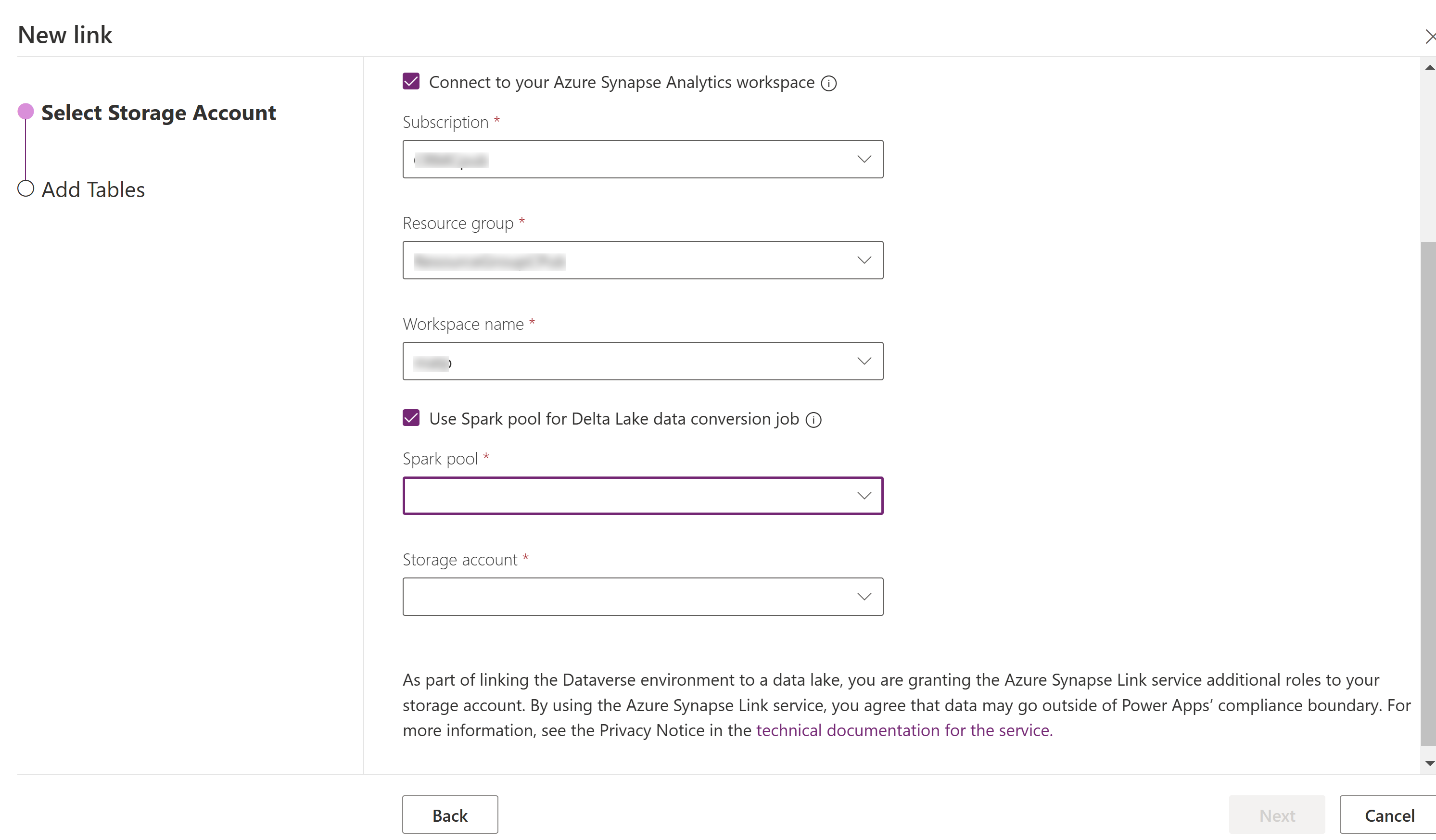
Selecione Seguinte.
Adicione as tabelas que pretende exportar e, em seguida, selecione Avançado.
Opcionalmente, selecione Mostrar definições de configuração avançadas e introduza o intervalo de tempo, em minutos, para a frequência com que as atualizações incrementais devem ser capturadas.
Selecione Guardar.
Monitorizar o seu Azure Synapse Link e a conversão de dados
- Selecione o Azure Synapse Link que pretende e, em seguida, selecione Aceder à área de trabalho do Azure Synapse Analytics na sua barra de comando.
- Selecione Monitorizar > Aplicações do Apache Spark. Mais informações: Usar o Synapse Studio para monitorizar as suas aplicações do Apache Spark
Ver os dados a partir da área de trabalho do Synapse
- Selecione o Azure Synapse Link que pretende e, em seguida, selecione Aceder à área de trabalho do Azure Synapse Analytics na sua barra de comando.
- Expanda Bases de dados do Lake no painel esquerdo, selecione dataverse-environmentNameorganizationUniqueName e, em seguida, expanda Tabelas. Todas as tabelas Parquet estão listadas e disponíveis para análise com a convenção de nomenclatura DataverseTableName. (Tabela Non_partitioned).
Nota
Não utilize tabelas com a convenção de nomenclatura _partitioned. Quando escolhe Delta parquet como o formato, as tabelas com a convenção de nomenclatura _partition são utilizadas como tabelas de teste e removidas depois de serem utilizadas pelo sistema.
Ver os seus dados a partir do Azure Data Lake Storage Gen2
- Selecione o Azure Synapse Link que pretende e, em seguida, selecione Ir para o Azure data lake na barra de comando.
- Selecione os Contentores sob Armazenamento de Dados.
- Selecione dataverse- environmentName-organizationUniqueName. Todos os ficheiros parquet são armazenados na pasta deltalake .
Atualização no local para Apache Spark 3.3 com Delta Lake 2.2
Pré-requisitos
- Tem de ter um perfil Delta Lake existente do Azure Synapse Link for Dataverse em execução com a versão 3.1. do Synapse Spark.
- Tem de criar um novo conjunto do Synapse Spark com o Spark versão 3.3, usando a mesma configuração de hardware de nós ou superior dentro da mesma área de trabalho do Synapse. Para obter informações sobre como criar um Conjunto do Spark, aceda a Criar novo conjunto do Apache Spark. Este conjunto do Spark deve ser criado independentemente do conjunto 3.1 atual.
Atualização no local para Spark 3.3:
- Inicie sessão no Power Apps e selecione o seu ambiente preferido.
- No painel de navegação esquerdo, selecione Azure Synapse Link. Se o item não estiver no painel de navegação do lado esquerdo, selecione ...Mais e, em seguida, selecione o item pretendido.
- Abra o perfil do Azure Synapse Link e, em seguida, selecione Atualizar para Apache Spark 3.3 com Delta Lake 2.2.
- Selecione o conjunto do Spark na lista disponível e, em seguida, Atualizar.
Nota
A atualização do conjunto do Spark ocorre só quando uma nova tarefa do Spark de conversão do Delta Lake é acionada. Certifique-se de que tem, pelo menos, uma alteração de dados depois de selecionar Atualizar.