Melhores práticas de análise do Microsoft Purview
As soluções de governação do Microsoft Purview suportam a análise automatizada de origens de dados no local, multicloud e software como serviço (SaaS).
A execução de uma análise invoca o processo para ingerir metadados das origens de dados registadas. Os metadados organizados no final do processo de análise e curadoria incluem metadados técnicos. Estes metadados podem incluir nomes de recursos de dados, como nomes de tabelas ou nomes de ficheiros, tamanho de ficheiro, colunas e linhagem de dados. Os detalhes do esquema também são capturados para origens de dados estruturadas. Um sistema de gestão de bases de dados relacionais é um exemplo deste tipo de origem.
O processo de curadoria aplica etiquetas de classificação automatizadas nos atributos de esquema com base no conjunto de regras de análise configurado. As etiquetas de confidencialidade são aplicadas se a sua conta do Microsoft Purview estiver ligada ao portal de conformidade do Microsoft Purview.
Importante
Se tiver políticas do Azure que impeçam atualizações para contas de Armazenamento, isso causará erros no processo de análise do Microsoft Purview. Siga o guia de etiquetas de exceção do Microsoft Purview para criar uma exceção para contas do Microsoft Purview.
Por que precisa de melhores práticas para gerir origens de dados?
As melhores práticas permitem-lhe:
- Otimizar o custo.
- Crie excelência operacional.
- Melhorar a conformidade de segurança.
- Obtenha eficiência de desempenho.
Registar uma origem e estabelecer uma ligação
As seguintes considerações e recomendações de design ajudam-no a registar uma origem e a estabelecer uma ligação.
Considerações de design
- Utilize coleções para criar a hierarquia alinhada com a estratégia da organização, como geográfico, função empresarial ou origem de dados. A hierarquia define as origens de dados a registar e analisar.
- Por predefinição, não pode registar origens de dados várias vezes na mesma conta do Microsoft Purview. Esta arquitetura ajuda a evitar o risco de atribuir um controlo de acesso diferente à mesma origem de dados.
Recomendações de conceção
Se os metadados da mesma origem de dados forem consumidos por várias equipas, pode registar e gerir a origem de dados numa coleção principal. Em seguida, pode criar análises correspondentes em cada subcoleção. Desta forma, os recursos relevantes são apresentados em cada coleção subordinada. As origens sem encarregados de educação são agrupadas numa caixa pontilhada na vista de mapa. Nenhuma seta as liga aos pais.
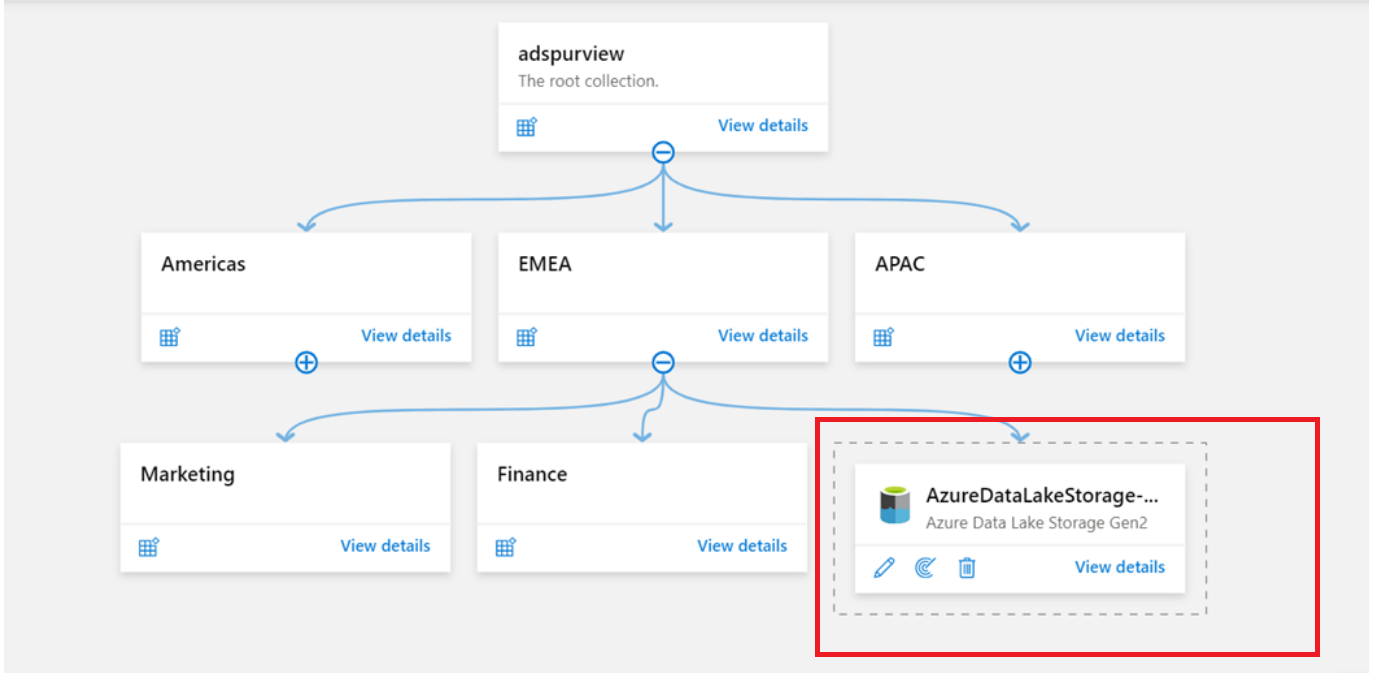
Utilize a opção Múltiplos do Azure se precisar de registar várias origens, como subscrições do Azure ou grupos de recursos, na cloud. Para obter mais informações, veja a seguinte documentação:
Depois de uma origem de dados ser registada, poderá analisar a mesma origem várias vezes, caso a mesma origem esteja a ser utilizada de forma diferente por várias equipas ou unidades empresariais.
Para obter mais informações sobre como definir uma hierarquia para registar origens de dados, veja Melhores práticas na arquitetura de coleções.
Verificação
As seguintes considerações e recomendações de design são organizadas com base nos principais passos envolvidos no processo de análise.
Considerações de design
- Após o registo da origem de dados, configure uma análise para gerir a análise e a curadoria de metadados automatizadas e seguras.
- A configuração da análise inclui configurar o nome da análise, o âmbito da análise, o runtime de integração, a frequência do acionador de análise, o conjunto de regras de análise e o conjunto de recursos de forma exclusiva para cada origem de dados por frequência de análise.
- Antes de criar credenciais, considere os seus tipos de origem de dados e requisitos de rede. Estas informações ajudam-no a decidir de que método de autenticação e runtime de integração precisa para o seu cenário.
Recomendações de conceção
Depois de registar a sua origem na coleção relevante, planeie e siga a ordem apresentada aqui quando configurar a análise. Esta ordem de processo ajuda-o a evitar custos e reformulações inesperados.

Identifique os requisitos de classificação das regras de classificação incorporadas do sistema. Em alternativa, pode criar regras de classificação personalizadas específicas, conforme necessário. Baseie-os em requisitos específicos do setor, da empresa ou regionais, que não estão disponíveis de forma inicial:
Crie conjuntos de regras de análise antes de configurar a análise.
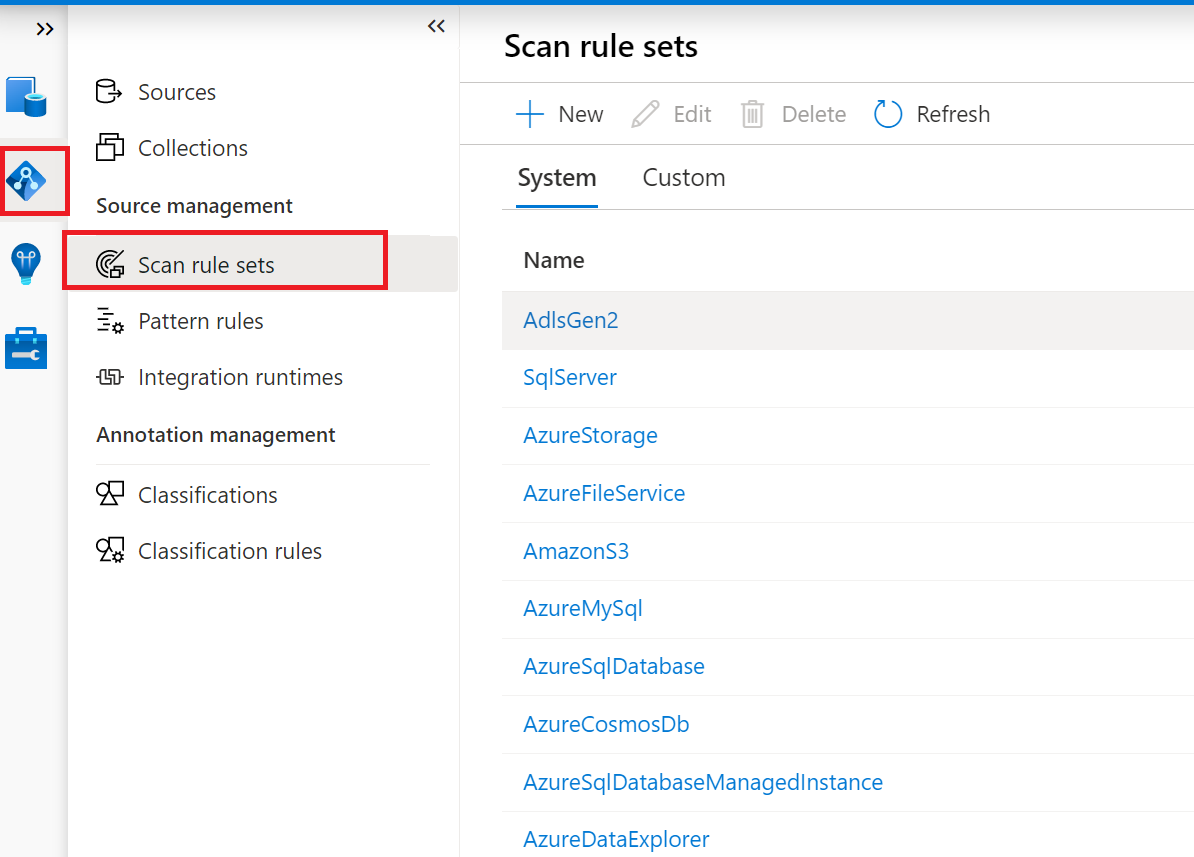
Quando criar o conjunto de regras de análise, confirme os seguintes pontos:
Verifique se o conjunto de regras de análise predefinido do sistema é suficiente para a origem de dados que está a ser analisada. Caso contrário, defina o conjunto de regras de análise personalizado.
O conjunto de regras de análise personalizada pode incluir a predefinição do sistema e personalizada, pelo que desmarque essas opções não relevantes para os recursos de dados que estão a ser analisados.
Sempre que necessário, crie um conjunto de regras personalizado para excluir etiquetas de classificação indesejadas. Por exemplo, o conjunto de regras do sistema contém padrões genéricos de código governamental para o planeta e não apenas o Estados Unidos. Os seus dados podem corresponder ao padrão de outro tipo, como "Número de Carta de Condução da Bélgica".
Limite as regras de classificação personalizadas às etiquetas mais importantes e relevantes para evitar a desorganização. Não quer ter demasiadas etiquetas etiquetadas no elemento.
Se modificar a classificação personalizada ou o conjunto de regras de análise, é acionada uma análise completa. Configure o conjunto de regras de classificação e análise adequadamente para evitar a reformulação e análises completas dispendiosas.
Observação
Quando analisa uma conta de armazenamento, o Microsoft Purview utiliza um conjunto de padrões definidos para determinar se um grupo de recursos forma um conjunto de recursos. Pode utilizar regras de padrão de conjunto de recursos para personalizar ou substituir a forma como o Microsoft Purview deteta quais os recursos agrupados como conjuntos de recursos. As regras também determinam a forma como os recursos são apresentados no catálogo. Para obter mais informações, veja Criar regras de padrão de conjunto de recursos. Esta funcionalidade tem considerações de custos. Para obter informações, veja a página de preços.
Configure uma análise para as origens de dados registadas.
Nome da análise: por predefinição, o Microsoft Purview utiliza a convenção de nomenclatura SCAN-[A-Z][a-z][a-z], o que não é útil quando está a tentar identificar uma análise que executou. Certifique-se de que utiliza uma convenção de nomenclatura significativa. Por exemplo, pode nomear environment-source-frequency-time como DEVODS-Daily-0200. Este nome representa uma análise diária às 02:00 horas.
Autenticação: o Microsoft Purview oferece vários métodos de autenticação para analisar origens de dados, consoante o tipo de origem. Pode ser uma cloud do Azure, origens no local ou de terceiros. Siga o princípio de menor privilégio para o método de autenticação nesta ordem de preferência:
- Microsoft Purview MSI – Identidade de Serviço Gerida (por exemplo, para origens Azure Data Lake Storage Gen2)
- Identidade gerida atribuída pelo utilizador
- Entidade de serviço
- Autenticação SQL (por exemplo, para origens no local ou SQL do Azure)
- Chave de conta ou autenticação básica (por exemplo, para origens SAP S/4HANA)
Para obter mais informações, veja o guia de procedimentos para gerir credenciais.
Observação
Se tiver uma firewall ativada para a conta de armazenamento, tem de utilizar o método de autenticação de identidade gerida quando configurar uma análise. Quando configura uma nova credencial, o nome da credencial só pode conter letras, números, carateres de sublinhado e hífenes.
Runtime de integração
- Para obter mais informações, veja Melhores práticas de arquitetura de rede.
- Se o runtime de integração autoalojado (SHIR) for eliminado, todas as análises em curso que dependem dele falharão.
- Quando utilizar o SHIR, certifique-se de que a memória é suficiente para a origem de dados que está a ser analisada. Por exemplo, quando utiliza o SHIR para analisar uma origem SAP, se vir "erro de memória insuficiente":
- Certifique-se de que a máquina SHIR tem memória suficiente. O valor recomendado é de 128 GB.
- Na definição de análise, defina a memória máxima disponível como um valor adequado, por exemplo, 100.
- Para obter mais informações, veja os pré-requisitos em Analisar e gerir o SAP ECC Microsoft Purview.
Análise de âmbito
Quando configurar o âmbito da análise, selecione apenas os recursos que são relevantes a um nível granular ou ao nível principal. Esta prática garante que o custo da análise é ideal e o desempenho é eficiente. Todos os recursos futuros num determinado elemento principal serão selecionados automaticamente se o elemento principal estiver totalmente ou parcialmente selecionado.
Alguns exemplos de algumas origens de dados:
- Para SQL do Azure Base de Dados ou Data Lake Storage Gen2, pode definir o âmbito da análise para partes específicas da origem de dados. Selecione os itens adequados na lista, tais como pastas, subpastas, coleções ou esquemas.
- Para origens oracle, Metastore do Hive e Teradata, uma lista específica de esquemas a exportar pode ser especificada através de valores separados por ponto e vírgula ou padrões de nome de esquema.
- Para a consulta Google Big, uma lista específica de conjuntos de dados a exportar pode ser especificada através de valores separados por ponto e vírgula.
- Quando cria uma análise para uma conta do AWS inteira, pode selecionar registos específicos para analisar. Quando cria uma análise para um registo específico do AWS S3, pode selecionar pastas específicas a analisar.
- Para o Erwin, pode definir o âmbito da análise ao fornecer uma lista separada por pontos e vírgulas de cadeias de localização de modelos Erwin.
- Para o Cassandra, uma lista específica de espaços chave a exportar pode ser especificada através de valores separados por ponto e vírgula ou através de padrões de nome de espaços de chaves.
- Para o Looker, pode definir o âmbito da análise ao fornecer uma lista separada por ponto e vírgula de projetos do Looker.
- Para o inquilino do Power BI, só pode especificar se pretende incluir ou excluir a área de trabalho pessoal.
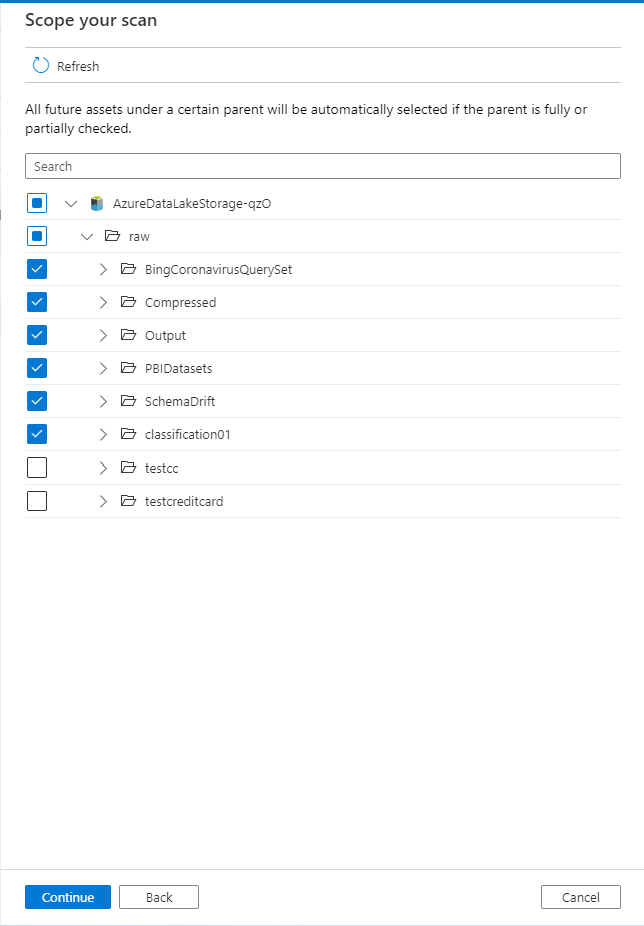
Em geral, utilize "ignorar padrões", onde são suportados, com base em cartões universais (por exemplo, para data lakes) para excluir ficheiros temporários, de configuração, tabelas de sistema RDBMS ou tabelas de cópia de segurança ou STG.
Quando digitaliza documentos ou dados não estruturados, evite analisar um grande número desses documentos. A análise processa os primeiros 20 MB desses documentos e pode resultar numa duração de análise mais longa.
Conjunto de regras de análise
- Quando selecionar o conjunto de regras de análise, certifique-se de que configura o sistema relevante ou o conjunto de regras de análise personalizado que foi criado anteriormente.
- Pode criar tipos de ficheiro personalizados e preencher os detalhes em conformidade. Atualmente, o Microsoft Purview suporta apenas um caráter no Delimitador Personalizado. Se utilizar delimitadores personalizados, como ~, nos seus dados reais, tem de criar um novo conjunto de regras de análise.
Tipo e agenda de análise
- O processo de análise pode ser configurado para executar análises completas ou incrementais.
- Execute as análises durante horas fora do negócio ou fora das horas de ponta para evitar qualquer sobrecarga de processamento na origem.
- A análise inicial é uma análise completa e cada análise subsequente é incremental. As análises subsequentes podem ser agendadas como análises incrementais periódicas. Saiba mais sobre as opções de agendamento suportadas.
- A frequência das análises deve estar alinhada com a agenda de gestão de alterações da origem de dados ou dos requisitos empresariais. Por exemplo:
- Se a estrutura de origem puder potencialmente mudar semanalmente, a frequência de análise deverá estar sincronizada. As alterações incluem novos recursos ou campos dentro de um recurso que são adicionados, modificados ou eliminados.
- Se se esperar que as etiquetas de classificação ou confidencialidade estejam atualizadas semanalmente, talvez por razões regulamentares, a frequência de análise deve ser semanal. Por exemplo, se forem adicionados ficheiros de partições todas as semanas num data lake de origem, poderá agendar análises mensais. Não precisa de agendar análises semanais porque não existem alterações nos metadados. Esta sugestão pressupõe que não existem novos cenários de classificação.
- A duração máxima que a análise pode executar é de sete dias, possivelmente devido a problemas de memória. Este período de tempo exclui o processo de ingestão. Se o progresso não tiver sido atualizado após sete dias, a análise será marcada como falhada. Atualmente, o processo de ingestão (para catálogo) não tem tal limitação.
Cancelar análises
- Atualmente, as análises só podem ser canceladas ou colocadas em pausa se o status da análise tiver transitado para o estado "Em Curso" a partir de "Em fila" depois de acionar a análise.
- O cancelamento de uma análise subordinada individual não é suportado.
Aponta para nota
- Se um campo ou coluna, tabela ou um ficheiro for removido do sistema de origem após a execução da análise, este só será refletido (removido) no Microsoft Purview após a próxima análise completa ou incremental agendada.
- Um recurso pode ser eliminado de um catálogo do Microsoft Purview com o ícone Eliminar sob o nome do recurso. Esta ação não remove o objeto na origem. Se executar uma análise completa na mesma origem, esta será reestida no catálogo. Em vez disso, se executar a análise incremental, o recurso eliminado não será escolhido, a menos que o objeto seja modificado na origem. Um exemplo é se uma coluna for adicionada ou removida da tabela.
- Para compreender o comportamento das análises subsequentes após editar manualmente um recurso de dados ou um esquema subjacente através do portal de governação do Microsoft Purview, veja Detalhes do recurso do catálogo.
- Para obter mais informações, veja o tutorial sobre como ver, editar e eliminar recursos.