Resurshantering i Azure SQL Database
gäller för:![]() Azure SQL Database
Azure SQL Database
Den här artikeln innehåller en översikt över resurshantering i Azure SQL Database. Den innehåller information om vad som händer när resursgränser nås och beskriver mekanismer för resursstyrning som används för att tillämpa dessa gränser.
Specifika resursgränser per prisnivå för enskilda databaser finns i antingen:
- DTU-baserade resursbegränsningar för en enskild databas
- resursbegränsningar för virtuella kärnor som baseras på en enskild databas
För resursbegränsningar för elastiska pooler, se antingen:
- DTU-baserade resursgränser för elastisk pool
- resursgränser för virtuella kärnor som baseras på elastisk pool
För dedikerade SQL-poolgränser för Azure Synapse Analytics läser du:
Begränsningar för virtuella kärnor för prenumeration per region
Från och med mars 2024 har prenumerationer följande gränser för virtuella kärnor per region per prenumeration:
| Prenumerationstyp | Standardgränser för virtuella kärnor |
|---|---|
| Enterprise-avtal (EA) | 2000 |
| Kostnadsfria utvärderingsversioner | 10 |
| Microsoft för nystartade företag | 100 |
| MSDN/MPN/Imagine/AzurePass/Azure for Students | 40 |
| Betala per användning (PAYG) | 150 |
Tänk på följande:
- Dessa gränser gäller för nya och befintliga prenumerationer.
- Databaser och elastiska pooler som etablerats med DTU-inköpsmodell räknas mot vCore-kvoten och vice versa. Varje virtuell kärna som förbrukas anses motsvara 100 DTU:er som förbrukas för servernivåkvoten.
- Standardgränserna omfattar både virtuella kärnor som konfigurerats för etablerade beräkningsdatabaser/elastiska pooler och maximalt antal virtuella kärnor konfigurerat för serverlösa databaser.
- Du kan använda prenumerationsanvändning – Hämta REST API-anrop för att fastställa din aktuella användning av virtuella kärnor för din prenumeration.
- Om du vill begära en högre kvot för virtuell kärna än standard skickar du en ny supportbegäran i Azure-portalen. Mer information finns i Begärandekvotökningar för Azure SQL Database och SQL Managed Instance.
Gränser för logisk server
| Resurs | Gräns |
|---|---|
| Databaser per logisk server | 5000 |
| Standardantal logiska servrar per prenumeration i en region | 250 |
| Maximalt antal logiska servrar per prenumeration i en region | 250 |
| Maximalt antal elastiska pooler per logisk server | Begränsas av antalet DTU:er eller virtuella kärnor. Om varje pool till exempel är 1 000 DTU:er kan en server stödja 54 pooler. |
Viktig
När antalet databaser närmar sig gränsen per logisk server kan följande inträffa:
- Ökad svarstid vid körning av frågor mot
master-databasen. Detta inkluderar vyer av resursanvändningsstatistik, till exempelsys.resource_stats. - Öka svarstiden i hanteringsåtgärder och återge portalvyer som omfattar uppräkning av databaser på servern.
Vad händer när resursgränser nås
Beräknings-CPU
När processoranvändningen för databasberäkning blir hög ökar frågefördröjningen och frågor kan till och med överskrida tidsgränsen. Under dessa förhållanden kan frågor köas av tjänsten och tillhandahålls resurser för körning när resurser blir kostnadsfria.
Om du observerar hög beräkningsanvändning kan du använda åtgärdsalternativen:
- Öka beräkningsstorleken för databasen eller den elastiska poolen för att ge databasen fler beräkningsresurser. Se Skala resurser för en enskild databas och Skala elastiska poolresurser.
- Optimera frågor för att minska cpu-resursanvändningen för varje fråga. Mer information finns i Query Tuning/Hinting.
Lagring
När datautrymmet som används når den maximala datastorleksgränsen, antingen på databasnivå eller på elastisk poolnivå, infogar och uppdaterar som ökar datastorleken misslyckas, och klienter får ett felmeddelande. SELECT- och DELETE-instruktioner påverkas inte.
På tjänstnivåerna Premium och Affärskritisk får klienterna också ett felmeddelande om den kombinerade lagringsförbrukningen efter data, transaktionsloggen och tempdb för en enskild databas eller en elastisk pool överskrider den maximala lokala lagringsstorleken. Mer information finns i Lagringsutrymmesstyrning.
Om du ser hög lagringsutrymmesanvändning omfattar åtgärdsalternativen:
- Öka den maximala datastorleken för databasen eller den elastiska poolen, eller skala upp till ett tjänstmål med en högre maximal datastorleksgräns. Se Skala resurser för en enskild databas och Skala elastiska poolresurser.
- Om databasen finns i en elastisk pool kan du också flytta databasen utanför poolen så att dess lagringsutrymme inte delas med andra databaser.
- Krymp en databas för att frigöra outnyttjat utrymme. Mer information finns i Hantera filutrymme för databaser.
- I elastiska pooler ger krympning av en databas mer lagringsutrymme för andra databaser i poolen.
- Kontrollera om hög utrymmesanvändning beror på en topp i storleken på Persistent Version Store (PVS). PVS är en del av varje databas och används för att implementera accelererad databasåterställning. Information om hur du fastställer aktuell PVS-storlek finns i Felsöka accelererad databasåterställning. En vanlig orsak till stor PVS-storlek är en transaktion som är öppen under lång tid (timmar), vilket förhindrar rensning av äldre radversioner i PVS.
- För databaser och elastiska pooler på premium- och affärskritiska tjänstnivåer som förbrukar stora mängder lagringsutrymme kan du få ett out-of-space-fel trots att använt utrymme i databasen eller den elastiska poolen ligger under den maximala datastorleksgränsen. Detta kan inträffa om
tempdb- eller transaktionsloggfiler använder en stor mängd lagringsutrymme mot den maximala lokala lagringsgränsen. Redundansväxla databasen eller den elastiska poolen för att återställatempdbtill den ursprungliga mindre storleken eller krympa transaktionslogg för att minska den lokala lagringsförbrukningen.
Sessioner, arbetare och begäranden
Sessioner, arbetare och begäranden definieras på följande sätt:
- En session representerar en process som är ansluten till databasmotorn.
- En begäran är den logiska representationen av en fråga eller batch. En begäran utfärdas av en klient som är ansluten till en session. Med tiden kan flera begäranden utfärdas i samma session.
- En arbetstråd, även kallad arbetare eller tråd, är en logisk representation av en operativsystemtråd. En begäran kan ha många arbetare när de körs med en parallell frågekörningsplan, eller en enskild arbetare när den körs med en seriell (en trådad) körningsplan. Arbetare måste också stödja aktiviteter utanför begäranden: till exempel krävs en arbetare för att bearbeta en inloggningsbegäran när en session ansluter.
Mer information om dessa begrepp finns i tråd- och aktivitetsarkitekturguiden.
Det maximala antalet arbetare bestäms av tjänstnivån och beräkningsstorleken. Nya begäranden avvisas när sessions- eller arbetsgränser nås och klienter får ett felmeddelande. Även om antalet anslutningar kan styras av programmet är antalet samtidiga arbetare ofta svårare att uppskatta och kontrollera. Detta gäller särskilt under perioder med hög belastning när databasresursgränser nås och arbetare staplas upp på grund av längre frågor som körs, stora blockeringskedjor eller överdriven frågeparallellitet.
Not
Det första erbjudandet för Azure SQL Database stöds endast för enstaka trådade frågor. Vid den tidpunkten motsvarades antalet begäranden alltid av antalet arbetare. Felmeddelandet 10928 i Azure SQL Database innehåller formuleringen The request limit for the database is *N* and has been reached endast i bakåtkompatibilitetssyfte. Den gräns som uppnåtts är faktiskt antalet arbetstagare.
Om maxgraden av parallelliteten (MAXDOP) är lika med noll eller större än en, kan antalet arbetare vara mycket högre än antalet begäranden och gränsen kan nås mycket tidigare än när MAXDOP är lika med en.
- Läs mer om fel 10928 i Resursstyrningsfel.
- Läs mer om överbelastning av begäranden i Fel 10928 och 10936.
Du kan undvika att närma dig eller nå arbets- eller sessionsgränser genom att:
- Öka tjänstnivån eller beräkningsstorleken för databasen eller den elastiska poolen. Se Skala resurser för en enskild databas och Skala elastiska poolresurser.
- Optimera frågor för att minska resursanvändningen om orsaken till ökad arbetskraft är konkurrens om beräkningsresurser. Mer information finns i Query Tuning/Hinting.
- Optimera frågearbetsbelastningen för att minska antalet förekomster och varaktigheten för frågeblockering. Mer information finns i Förstå och lösa blockeringsproblem.
- Minska inställningen MAXDOP när det är lämpligt.
Hitta arbets- och sessionsgränser för Azure SQL Database efter tjänstnivå och beräkningsstorlek:
- Resursgränser för enskilda databaser med köpmodellen för virtuella kärnor
- Resursgränser för elastiska pooler med köpmodellen för virtuella kärnor
- Resursgränser för enskilda databaser med hjälp av DTU-inköpsmodellen
- Resursgränser för elastiska pooler med hjälp av DTU-inköpsmodellen
Läs mer om felsökning av specifika fel för sessions- eller arbetsgränser i Resursstyrningsfel.
Externa anslutningar
Antalet samtidiga anslutningar till externa slutpunkter som görs via sp_invoke_external_rest_endpoint begränsas till 10% arbetstrådar, med ett hårt tak på högst 150 arbetare.
Minne
Till skillnad från andra resurser (CPU, arbetare, lagring) påverkar det inte frågeprestanda negativt att nå minnesgränsen och orsakar inte fel och fel. Enligt beskrivningen i arkitekturguide för minneshanteringanvänder databasmotorn ofta allt tillgängligt minne, avsiktligt. Minnet används främst för cachelagring av data för att undvika långsammare lagringsåtkomst. Högre minnesanvändning förbättrar därför vanligtvis frågeprestanda på grund av snabbare läsningar från minnet i stället för långsammare läsningar från lagring.
När databasmotorn har startats cachelagrar databasmotorn data i minnet när arbetsbelastningen börjar läsa data från lagring. Efter den här inledande upprampningsperioden är det vanligt och förväntas att se kolumnerna avg_memory_usage_percent och avg_instance_memory_percent i sys.dm_db_resource_statsoch sql_instance_memory_percent Azure Monitor-måttet är nära 100%, särskilt för databaser som inte är inaktiva och som inte får plats helt i minnet.
Not
Måttet sql_instance_memory_percent återspeglar databasmotorns totala minnesförbrukning. Det här måttet kanske inte når 100% även när högintensiva arbetsbelastningar körs. Det beror på att en liten del av det tillgängliga minnet är reserverat för kritiska minnesallokeringar förutom datacachen, till exempel trådstackar och körbara moduler.
Förutom datacachen används minne i andra komponenter i databasmotorn. När det finns efterfrågan på minne och allt tillgängligt minne har använts av datacachen minskar databasmotorn datacachestorleken för att göra minnet tillgängligt för andra komponenter och växer dynamiskt datacachen när andra komponenter frigör minne.
I sällsynta fall kan en tillräckligt krävande arbetsbelastning orsaka ett otillräckligt minnestillstånd, vilket leder till minnesfel. Minnesfel kan inträffa på valfri minnesanvändningsnivå mellan 0% och 100%. Det är mer troligt att minnesfel uppstår på mindre beräkningsstorlekar som har proportionellt mindre minnesgränser och/eller med arbetsbelastningar som använder mer minne för frågebearbetning, till exempel i kompakta elastiska pooler.
Om du får minnesfel kan du till exempel åtgärda följande:
- Granska informationen om OOM-villkoret i sys.dm_os_out_of_memory_events.
- Öka tjänstnivån eller beräkningsstorleken för databasen eller den elastiska poolen. Se Skala resurser för en enskild databas och Skala elastiska poolresurser.
- Optimera frågor och konfiguration för att minska minnesanvändningen. Vanliga lösningar beskrivs i följande tabell.
| Lösning | Beskrivning |
|---|---|
| Minska storleken på minnesbidrag | Mer information om minnesbidrag finns i blogginlägget Understanding SQL Server memory grants . En vanlig lösning för att undvika alltför stora minnesbidrag är att hålla statistik uppdaterad. Detta resulterar i mer exakta uppskattningar av frågemotorns minnesförbrukning, vilket undviker stora minnesbidrag. I databaser med kompatibilitetsnivå 140 och senare kan databasmotorn som standard automatiskt justera storleken på minnesbidraget med hjälp av Minnesåtergivning i Batch-läge. I databaser som använder kompatibilitetsnivå 150 och senare använder databasmotorn också minnesåtergivning i radläge, för vanligare frågor i radläge. Den här inbyggda funktionen hjälper till att undvika minnesfel på grund av stora minnesbidrag. |
| Minska storleken på cachen för frågeplan | Databasmotorn cachelagrar frågeplaner i minnet för att undvika att kompilera en frågeplan för varje frågekörning. Om du vill undvika uppsvälld frågeplanscache som orsakas av cachelagringsplaner som endast används en gång ska du använda parametriserade frågor och överväga att aktivera OPTIMIZE_FOR_AD_HOC_WORKLOADS databasomfattande konfiguration. |
| Minska storleken på låsminnet | Databasmotorn använder minne för låser. Undvik om möjligt stora transaktioner som kan hämta ett stort antal lås och orsaka hög minnesförbrukning för lås. |
Resursförbrukning efter användararbetsbelastningar och interna processer
Azure SQL Database kräver beräkningsresurser för att implementera grundläggande tjänstfunktioner som hög tillgänglighet och haveriberedskap, säkerhetskopiering och återställning av databaser, övervakning, Query Store, automatisk justering osv. Systemet reserverar en begränsad del av de totala resurserna för dessa interna processer med hjälp av resursstyrning mekanismer, vilket gör resten av resurserna tillgängliga för användararbetsbelastningar. När interna processer inte använder beräkningsresurser gör systemet dem tillgängliga för användararbetsbelastningar.
Total cpu- och minnesförbrukning efter användararbetsbelastningar och interna processer rapporteras i sys.dm_db_resource_stats- och sys.resource_stats-vyerna i kolumnerna avg_instance_cpu_percent och avg_instance_memory_percent. Dessa data rapporteras också via måtten sql_instance_cpu_percent och sql_instance_memory_percent Azure Monitor för enskilda databaser och elastiska pooler på poolnivå.
Not
Måtten sql_instance_cpu_percent och sql_instance_memory_percent Azure Monitor är tillgängliga sedan juli 2023. De är helt likvärdiga med tidigare tillgängliga sqlserver_process_core_percent respektive sqlserver_process_memory_percent mått. De två senare måtten är fortfarande tillgängliga, men tas bort i framtiden. Använd inte de äldre måtten för att undvika avbrott i databasövervakningen.
Dessa mått är inte tillgängliga för databaser med hjälp av tjänstmålen Basic, S1 och S2. Samma data är tillgängliga i följande dynamiska hanteringsvyer.
Processor- och minnesförbrukning efter användararbetsbelastningar i varje databas rapporteras i vyerna sys.dm_db_resource_stats och sys.resource_stats, i kolumnerna avg_cpu_percent och avg_memory_usage_percent. För elastiska pooler rapporteras resursförbrukning på poolnivå i vyn sys.elastic_pool_resource_stats (för historiska rapporteringsscenarier) och i sys.dm_elastic_pool_resource_stats för realtidsövervakning. Cpu-förbrukning för användararbetsbelastning rapporteras också via måttet cpu_percent Azure Monitor för enskilda databaser och elastiska pooler på poolnivå.
En mer detaljerad uppdelning av den senaste resursförbrukningen efter användararbetsbelastningar och interna processer rapporteras i vyerna sys.dm_resource_governor_resource_pools_history_ex och sys.dm_resource_governor_workload_groups_history_ex. Mer information om resurspooler och arbetsbelastningsgrupper som refereras i dessa vyer finns i Resursstyrning. Dessa vyer rapporterar om resursanvändning efter användararbetsbelastningar och specifika interna processer i de associerade resurspoolerna och arbetsbelastningsgrupperna.
Dricks
När du övervakar eller felsöker arbetsbelastningsprestanda är det viktigt att tänka på både användar-CPU-förbrukning (avg_cpu_percent, cpu_percent) och total CPU-förbrukning av användararbetsbelastningar och interna processer (avg_instance_cpu_percent,sql_instance_cpu_percent). Prestanda kan påverkas märkbart om någon av av dessa mått ligger inom intervallet 70–100%.
Användar-CPU-förbrukning definieras som en procentandel mot användarbelastningens CPU-gräns i varje tjänstmål. På samma sätt definieras totala CPU-förbrukningen som procentandelen mot CPU-gränsen för alla arbetsbelastningar. Eftersom de två gränserna är olika mäts användarens och den totala CPU-förbrukningen på olika skalor och är inte direkt jämförbara med varandra.
Om användarens CPU-förbrukning når 100%innebär det att användararbetsbelastningen helt använder den processorkapacitet som är tillgänglig för den i det valda tjänstmålet, även om total CPU-förbrukning förblir under 100%.
När totala CPU-förbrukningen når intervallet 70–100% går det att se att dataflödet för användararbetsbelastningar planar ut och frågesvarstiden ökar, även om användarens CPU-förbrukning ligger betydligt under 100%. Detta är mer sannolikt när du använder mindre tjänstmål med en måttlig allokering av beräkningsresurser, men relativt intensiva användararbetsbelastningar, till exempel i kompakta elastiska pooler. Detta kan också inträffa med mindre tjänstmål när interna processer tillfälligt kräver fler resurser, till exempel när du skapar en ny replik av databasen eller säkerhetskopierar databasen.
På samma sätt, när användarens CPU-förbrukning når intervallet 70–100%, planar användararbetsbelastningens dataflöde ut och frågesvarstiden ökar, även om totala CPU-förbrukningen ligger långt under gränsen.
När antingen användarens CPU-förbrukning eller total CPU-förbrukning är hög, är åtgärdsalternativen desamma som i avsnittet Compute CPU och inkluderar optimering av tjänstmål och/eller användararbetsbelastning.
Not
Även i en helt inaktiv databas eller elastisk pool total CPU-förbrukning aldrig ligger på noll på grund av bakgrundsdatabasmotoraktiviteter. Det kan variera i ett brett intervall beroende på specifika bakgrundsaktiviteter, beräkningsstorlek och tidigare användararbetsbelastning.
Resursstyrning
För att framtvinga resursgränser använder Azure SQL Database en implementering av resursstyrning som baseras på SQL Server Resource Governor, ändras och utökas för att köras i molnet. I SQL Database ger flera resurspooler och arbetsbelastningsgrupper, med resursgränser inställda på både pool- och gruppnivå, en balanserad databas som en tjänst. Användararbetsbelastningar och interna arbetsbelastningar klassificeras i separata resurspooler och arbetsbelastningsgrupper. Användararbetsbelastningen på de primära och läsbara sekundära replikerna, inklusive geo-repliker, klassificeras i SloSharedPool1 resurspool och UserPrimaryGroup.DBId[N] arbetsbelastningsgrupper, där [N] står för databas-ID-värdet. Dessutom finns det flera resurspooler och arbetsbelastningsgrupper för olika interna arbetsbelastningar.
Förutom att använda Resource Governor för att styra resurser i databasmotorn använder Azure SQL Database även Windows Job Objects för resursstyrning på processnivå och Windows File Server Resource Manager (FSRM) för hantering av lagringskvoter.
Resursstyrning i Azure SQL Database är hierarkisk. Uppifrån och ned framtvingas begränsningar på os-nivå och på lagringsvolymnivå med hjälp av mekanismer för styrning av operativsystemresurser och Resource Governor, sedan på resurspoolsnivå med hjälp av Resource Governor och sedan på arbetsbelastningsgruppsnivå med hjälp av Resource Governor. Begränsningar för resursstyrning som gäller för den aktuella databasen eller den elastiska poolen rapporteras i sys.dm_user_db_resource_governance vy.
Data-I/O-styrning
Data-I/O-styrning är en process i Azure SQL Database som används för att begränsa både läs- och skrivskyddade fysiska I/O-filer mot datafiler i en databas. IOPS-gränser anges för varje tjänstnivå för att minimera effekten "bullrig granne", för att ge resursallokering rättvisa i en tjänst med flera klientorganisationer och för att hålla dig inom funktionerna i den underliggande maskinvaran och lagringen.
För enskilda databaser tillämpas arbetsbelastningsgruppens gränser på alla lagrings-I/O mot databasen. För elastiska pooler gäller begränsningar för arbetsbelastningsgrupper för varje databas i poolen. Dessutom gäller resurspoolgränsen för den elastiska poolens kumulativa I/O. I tempdbomfattas I/O av arbetsbelastningsgruppens begränsningar, förutom tjänstnivån Basic, Standard och Generell användning, där högre tempdb I/O-gränser gäller. I allmänhet kanske resurspoolsbegränsningar inte kan uppnås av arbetsbelastningen mot en databas (antingen enskild eller poolad), eftersom arbetsbelastningsgruppens gränser är lägre än resurspoolsgränserna och begränsar IOPS/dataflödet tidigare. Poolgränser kan dock nås av den kombinerade arbetsbelastningen mot flera databaser i samma pool.
Om en fråga till exempel genererar 1 000 IOPS utan någon I/O-resursstyrning, men arbetsbelastningsgruppens maximala IOPS-gräns är inställd på 900 IOPS, kan frågan inte generera mer än 900 IOPS. Men om den maximala IOPS-gränsen för resurspoolen är inställd på 1 500 IOPS och den totala I/O från alla arbetsbelastningsgrupper som är associerade med resurspoolen överskrider 1 500 IOPS kan I/O för samma fråga minskas under arbetsgruppsgränsen på 900 IOPS.
Maxvärdena för IOPS och dataflöde som returneras av sys.dm_user_db_resource_governance-vyn fungerar som gränser/tak, inte som garantier. Dessutom garanterar resursstyrning inte någon specifik lagringsfördröjning. Den bästa möjliga svarstiden, IOPS och dataflödet för en viss användararbetsbelastning beror inte bara på I/O-resursstyrningsgränser, utan även på blandningen av I/O-storlekar som används och på funktionerna i den underliggande lagringen. SQL Database använder I/O-åtgärder som varierar i storlek mellan 512 byte och 4 MB. För att framtvinga IOPS-gränser redovisas varje I/O oavsett storlek, förutom databaser med datafiler i Azure Storage. I så fall redovisas IO:er som är större än 256 KB som flera 256 KB I/Os för att anpassas till Azure Storage I/O-redovisning.
För basic-, standard- och general purpose-databaser, som använder datafiler i Azure Storage, kan primary_group_max_io-värdet kanske inte uppnås om en databas inte har tillräckligt med datafiler för att kumulativt ange det här antalet IOPS, eller om data inte fördelas jämnt mellan filer, eller om prestandanivån för underliggande blobar begränsar IOPS/dataflöde under resursstyrningsgränserna. Med små logg-I/O-åtgärder som genereras av frekventa incheckningar av transaktioner kan det primary_max_log_rate värdet kanske inte uppnås av en arbetsbelastning på grund av IOPS-gränsen för den underliggande Azure Storage-bloben. För databaser som använder Azure Premium Storage använder Azure SQL Database tillräckligt stora lagringsblobar för att erhålla nödvändig IOPS/dataflöde, oavsett databasstorlek. För större databaser skapas flera datafiler för att öka den totala IOPS/dataflödeskapaciteten.
Resursanvändningsvärden som avg_data_io_percent och avg_log_write_percent, som rapporteras i sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_statsoch sys.elastic_pool_resource_stats vyer, beräknas som procentandelar av maximala resursstyrningsgränser. När andra faktorer än resursstyrning begränsar IOPS/dataflöde är det därför möjligt att se att IOPS/dataflödet planar ut och svarstiderna ökar när arbetsbelastningen ökar, även om den rapporterade resursanvändningen fortfarande är under 100%.
Om du vill övervaka IOPS, dataflöde och svarstid för läsning och skrivning per databasfil använder du funktionen sys.dm_io_virtual_file_stats(). Den här funktionen visar all I/O mot databasen, inklusive bakgrunds-I/O som inte redovisas mot avg_data_io_percent, men som använder IOPS och dataflöde för den underliggande lagringen och kan påverka den observerade lagringsfördröjningen. Funktionen rapporterar ytterligare svarstider som kan introduceras av I/O-resursstyrning för läsningar och skrivningar i kolumnerna io_stall_queued_read_ms respektive io_stall_queued_write_ms.
Styrning av transaktionsloggfrekvens
Styrning av transaktionsloggfrekvens är en process i Azure SQL Database som används för att begränsa höga inmatningshastigheter för arbetsbelastningar som massinfogning, SELECT INTO och indexversioner. Dessa gränser spåras och framtvingas på undersekunder till genereringshastigheten för loggposter, vilket begränsar dataflödet oavsett hur många IO:er som kan utfärdas mot datafiler. Genereringshastigheter för transaktionsloggar skalas för närvarande linjärt upp till en punkt som är maskinvaruberoende och tjänstnivåberoende.
Loggfrekvenser anges så att de kan uppnås och upprätthållas i olika scenarier, medan det övergripande systemet kan behålla sina funktioner med minimerad påverkan på användarbelastningen. Logghastighetsstyrning säkerställer att säkerhetskopior av transaktionsloggar håller sig inom publicerade serviceavtal för återställning. Den här styrningen förhindrar också en överdriven kvarvarande belastning på sekundära repliker som annars kan leda till längre stilleståndstid än förväntat under redundansväxlingar.
De faktiska fysiska IO:erna till transaktionsloggfilerna styrs inte eller begränsas. När loggposter genereras utvärderas och utvärderas varje åtgärd för om den ska fördröjas för att upprätthålla en maximal önskad loggfrekvens (MB/s per sekund). Fördröjningarna läggs inte till när loggposterna töms till lagring, snarare tillämpas logghastighetsstyrning under själva logghastighetsgenereringen.
De faktiska logggenereringsfrekvenserna som tillämpas vid körning påverkas också av feedbackmekanismer, vilket tillfälligt minskar de tillåtna loggfrekvenserna så att systemet kan stabiliseras. Loggfilutrymmeshantering, undvika att få slut på loggutrymmesförhållanden och datareplikeringsmekanismer kan tillfälligt minska de övergripande systemgränserna.
Trafikformningen för logghastighetsguvernören visas via följande väntetyper (exponeras i sys.dm_exec_requests och sys.dm_os_wait_stats vyer):
| Väntetyp | Anteckningar |
|---|---|
LOG_RATE_GOVERNOR |
Databasbegränsning |
POOL_LOG_RATE_GOVERNOR |
Poolbegränsning |
INSTANCE_LOG_RATE_GOVERNOR |
Instansnivåbegränsning |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Feedbackkontroll, fysisk replikering av tillgänglighetsgrupp i Premium/Affärskritisk håller inte jämna steg |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Feedbackkontroll, begränsande priser för att undvika ett villkor för out-of-log space |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Feedbackkontroll för geo-replikering, begränsning av loggfrekvens för att undvika hög datasvarstid och otillgänglighet för geo-sekundärfiler |
När du stöter på en logghastighetsgräns som hämmar önskad skalbarhet bör du överväga följande alternativ:
- Skala upp till en högre tjänstnivå för att få den maximala logghastigheten för en tjänstnivå eller växla till en annan tjänstnivå. Tjänstnivån Hyperskala ger en loggfrekvens på 100 MB/s per databas och 125 MB/s per elastisk pool, oavsett vald tjänstnivå. Logggenereringshastigheten på 150 MB/s är tillgänglig som en förhandsversionsfunktion. Mer information och om du vill välja 150 MB/s finns i Blogg: Förbättringar av hyperskala i november 2024.
- Om data som läses in är tillfälliga, till exempel mellanlagringsdata i en ETL-process, kan de läsas in i
tempdb(som är minimalt loggad). - För analysscenarier läser du in i en klustrad kolumnarkiv tabell eller en tabell med index som använder datakomprimering. Detta minskar den loggfrekvens som krävs. Den här tekniken ökar processoranvändningen och gäller endast för datauppsättningar som drar nytta av klustrade kolumnlagringsindex eller datakomprimering.
Styrning av lagringsutrymme
I premium- och affärskritiska tjänstnivåer lagras kunddata, inklusive datafiler, transaktionsloggfiler och tempdb filer, på den lokala SSD-lagringen på den dator som är värd för databasen eller den elastiska poolen. Lokal SSD-lagring ger hög IOPS och dataflöde och låg I/O-svarstid. Förutom kunddata används lokal lagring för operativsystemet, hanteringsprogramvaran, övervakningsdata och loggar samt andra filer som krävs för systemdrift.
Storleken på lokal lagring är begränsad och beror på maskinvarufunktioner, som avgör högsta lokala lagringsgräns eller lokal lagring som reserverats för kunddata. Den här gränsen är inställd för att maximera kundens datalagring, samtidigt som säker och tillförlitlig systemdrift säkerställs. Information om hur du hittar det högsta värdet för lokal lagring för varje tjänstmål finns i dokumentationen om resursbegränsningar för enskilda databaser och elastiska pooler.
Du kan också hitta det här värdet och mängden lokal lagring som för närvarande används av en viss databas eller elastisk pool med hjälp av följande fråga:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Spalt | Beskrivning |
|---|---|
server_name |
Namn på logisk server |
database_name |
Databasnamn |
slo_name |
Namn på tjänstmål, inklusive maskinvarugenerering |
user_data_directory_space_quota_mb |
Maximal lokal lagringi MB |
user_data_directory_space_usage_mb |
Aktuell lokal lagringsförbrukning efter datafiler, transaktionsloggfiler och tempdb filer i MB. Uppdaterad var femte minut. |
Den här frågan ska köras i användardatabasen, inte i master-databasen. För elastiska pooler kan frågan köras i valfri databas i poolen. Rapporterade värden gäller för hela poolen.
Viktig
Om arbetsbelastningen försöker öka den kombinerade lokala lagringsförbrukningen efter datafiler, transaktionsloggfiler och
Lokal SSD-lagring används också av databaser på andra tjänstnivåer än Premium och Business Critical för tempdb-databasen och Hyperskala RBPEX-cachen. När databaser skapas, tas bort och ökar eller minskar i storlek varierar den totala lokala lagringsförbrukningen på en dator över tid. Om systemet upptäcker att den tillgängliga lokala lagringen på en dator är låg och en databas eller en elastisk pool riskerar att få slut på utrymme flyttas databasen eller den elastiska poolen till en annan dator med tillräckligt med lokalt lagringsutrymme tillgängligt.
Den här flytten sker online, på samma sätt som en databasskalningsåtgärd, och har en liknande påverkan, inklusive en kort redundansväxling (sekunder) i slutet av åtgärden. Den här redundansväxlingen avslutar öppna anslutningar och återställer transaktioner, vilket kan påverka program som använder databasen vid den tidpunkten.
Eftersom alla data kopieras till lokala lagringsvolymer på olika datorer kan det ta lång tid att flytta större databaser i premium- och affärskritiska tjänstnivåer. Om den lokala utrymmesförbrukningen för en databas eller en elastisk pool, eller av tempdb databas växer snabbt, ökar risken för att utrymmet börjar ta slut under den tiden. Systemet initierar databasflytt på ett balanserat sätt för att minimera out-of-space-fel samtidigt som onödiga redundansväxlingar undviks.
tempdb storlekar
Storleksbegränsningar för tempdb i Azure SQL Database beror på inköps- och distributionsmodellen.
Mer information finns i tempdb storleksgränser för:
- Köpmodell för virtuella kärnor: enkla databaser, pooldatabaser
- DTU-inköpsmodell: enkla databaser, pooldatabaser.
Tidigare tillgänglig maskinvara
Det här avsnittet innehåller information om tidigare tillgänglig maskinvara.
- Gen4-maskinvaran har dragits tillbaka och är inte tillgänglig för etablering, uppskalning eller nedskalning. Migrera databasen till en maskinvarugenerering som stöds för ett bredare utbud av skalbarhet för virtuella kärnor och lagring, accelererat nätverk, bästa I/O-prestanda och minimal svarstid. Mer information finns i supporten har upphört för Gen 4-maskinvara i Azure SQL Database.
Du kan använda Azure Resource Graph Explorer för att identifiera alla Azure SQL Database-resurser som för närvarande använder Gen4-maskinvara, eller så kan du kontrollera vilken maskinvara som används av resurser för en specifik logisk server i Azure-portalen.
Du måste ha minst read behörigheter till Azure-objektet eller objektgruppen för att se resultat i Azure Resource Graph Explorer.
Följ dessa steg om du vill använda Resource Graph Explorer för att identifiera Azure SQL-resurser som fortfarande använder Gen4-maskinvara:
Gå till Azure-portalen.
Sök efter
Resource graphi sökrutan och välj tjänsten Resource Graph Explorer i sökresultaten.I frågefönstret skriver du följande fråga och väljer sedan Kör fråga:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"Fönstret Resultat visar alla för närvarande distribuerade resurser i Azure som använder Gen4-maskinvara.
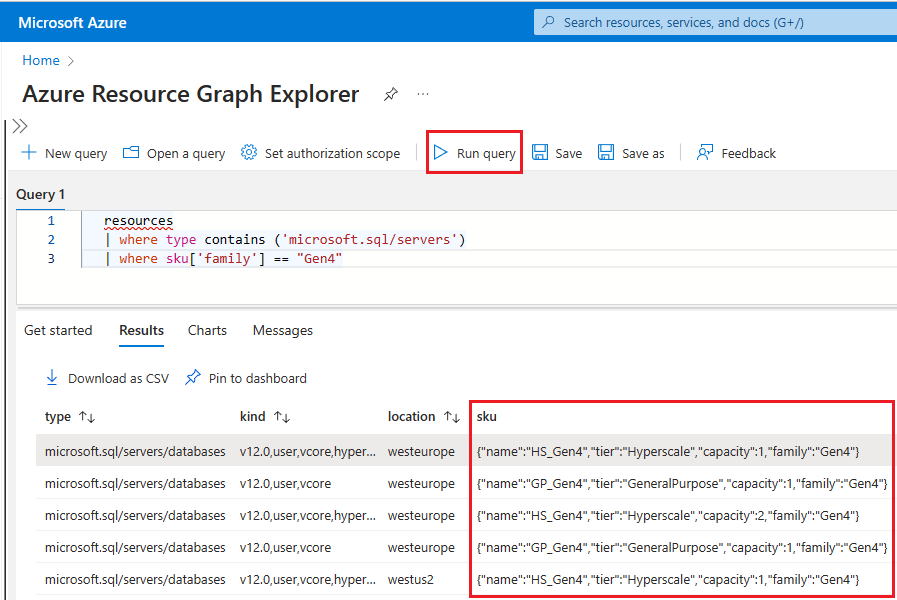
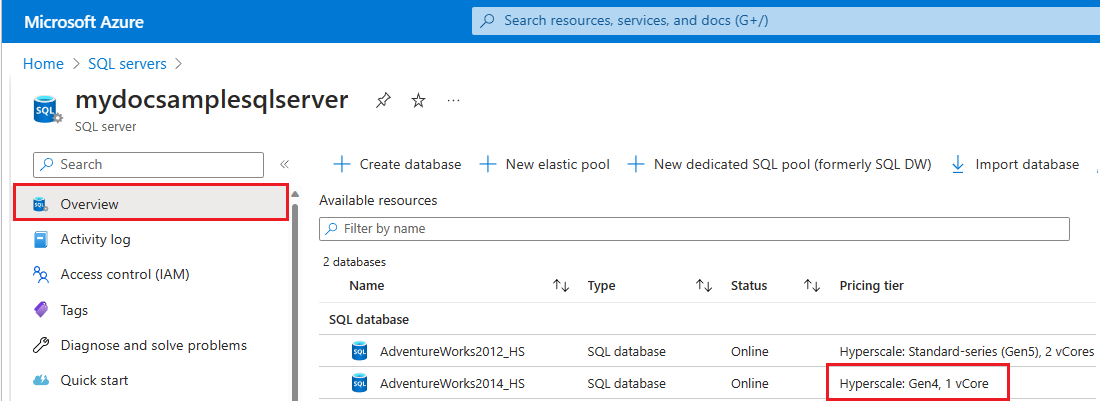
Följ dessa steg för att kontrollera vilken maskinvara som används av resurser för en specifik logisk server i Azure:
- Gå till Azure-portalen.
- Sök efter
SQL serversi sökrutan och välj SQL-servrar från sökresultaten för att öppna sidan SQL-servrar och visa alla servrar för de valda prenumerationerna. - Välj servern av intresse för att öppna sidan Översikt för servern.
- Rulla ned till tillgängliga resurser och kontrollera kolumnen prisnivå för resurser som använder gen4-maskinvara.
Om du vill migrera resurser till maskinvara i standardserien läser du Ändra maskinvara.
Relaterat innehåll
- Information om allmänna Azure-gränser finns i Azure-prenumerations- och tjänstgränser, kvoter och begränsningar.
- Information om DTU:er och eDTU:er finns i DTU:er och eDTU:er.
- Information om
tempdbstorleksgränser finns i databaser med en virtuell kärna, pooldatabaser med virtuella kärnor, enkla DTU-databaseroch poolade DTU-databaser.