Översikt över failovergrupper & bästa praxis – Azure SQL Managed Instance
gäller för:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Med funktionen failovergrupper kan du hantera replikering och failover av alla användardatabaser i en hanterad instans till en annan Azure-region. Den här artikeln innehåller en översikt över funktionen för redundansgrupper med metodtips och rekommendationer för att använda den med Azure SQL Managed Instance.
Kom igång med funktionen genom att läsa Konfigurera en redundansgrupp för Azure SQL Managed Instance.
Överblick
Med funktionen failover-grupper kan du hantera replikering och överflyttning av användardatabaser från en hanterad instans till en annan hanterad instans i en annan Azure-region. Redundansgrupper är utformade för att förenkla distribution och hantering av geo-replikerade databaser i stor skala.
Mer information finns i Hög tillgänglighet för Azure SQL Managed Instance. Information om geo-failover RPO och RTO kan hittas i översikten över affärskontinuitet.
Omdirigering av slutpunkt
Redundansgrupper tillhandahåller skrivbara och skrivskyddade lyssnarens slutpunkter som förblir oförändrade under geo-failovers. Du behöver inte ändra anslutningssträngen för ditt program efter en geografisk failover eftersom anslutningar automatiskt dirigeras till den nuvarande primära servern. En geo-failover gör att samtliga sekundära databaser i gruppen övertar den primära rollen. När geo-failover är klar uppdateras DNS-posten automatiskt för att omdirigera slutpunkterna till den nya regionen.
Avlasta endast läsbara arbetsbelastningar
Om du vill minska trafiken till dina primära databaser kan du också använda de sekundära databaserna i en redundansgrupp för att avlasta skrivskyddade arbetsbelastningar. Använd den skrivskyddade lyssnaren för att dirigera skrivskyddad trafik till en läsbar sekundär databas.
Återställa ett program
För att uppnå fullständig affärskontinuitet är det bara en del av lösningen att lägga till regional databasredundans. Återställning av ett program (tjänst) från slutpunkt till slutpunkt efter ett oåterkalleligt fel kräver återställning av alla komponenter som utgör tjänsten och alla beroende tjänster. Exempel på dessa komponenter är klientprogramvaran (till exempel en webbläsare med ett anpassat JavaScript), webbklientdelar, lagring och DNS. Det är viktigt att alla komponenter är motståndskraftiga mot samma fel och blir tillgängliga inom programmets mål för återställningstid (RTO). Därför måste du identifiera alla beroende tjänster och förstå de garantier och funktioner som de tillhandahåller. Sedan måste du vidta lämpliga åtgärder för att säkerställa att tjänsten fungerar under redundansväxlingen av de tjänster som den är beroende av.
Redundansprincip
Failovergrupper stöder två failover-policyer:
-
Kundhanterad (rekommenderas) – Kunder kan utföra en failover av en grupp när de märker ett oväntat avbrott som påverkar en eller flera databaser i failovergruppen. När du använder kommandoradsverktyg som PowerShell, Azure CLI eller REST API, är värdet för failover-politiken för kundhanterad
manual. -
Microsoft-hanterade – I händelse av ett omfattande avbrott som påverkar en primär region, initierar Microsoft felövergång av alla berörda failovergrupper som har sin felövergångspolicy konfigurerad för att hanteras av Microsoft. Microsofts hanterade redundans initieras inte för enskilda redundansgrupper eller en delmängd av redundansgrupper i en region. När du använder kommandoradsverktyg som PowerShell, Azure CLI eller Rest-API är värdet för överflyttningspolicyn för Microsoft-hanterad
automatic.
Varje redundansprincip har en unik uppsättning användningsfall och motsvarande förväntningar på redundansomfånget och dataförlusten, som följande tabell sammanfattar:
| Redundansprincip | Redundansomfång | Användningsfall | Potentiell dataförlust |
|---|---|---|---|
| Hanteras av kunden (rekommenderas) |
Failover-grupp(er) | En eller flera databaser i en redundansgrupp påverkas av ett avbrott och blir otillgängliga. Du kan välja att redundansväxla. | Ja |
| hanterad av Microsoft | Alla failover-grupper i regionen | Ett omfattande avbrott i ett datacenter, en tillgänglighetszon eller en region orsakar otillgänglighet för databaser och Microsoft Azure SQL-tjänstteamet bestämmer sig för att utlösa en tvingad redundansväxling. Använd endast det här alternativet om du vill delegera ansvaret för haveriberedskap till Microsoft och programmet är tolerant mot RTO (stilleståndstid) på minst en timme eller mer. |
Ja |
Hanterad av kunden
I sällsynta fall räcker inte den inbyggda tillgänglighet eller hög tillgänglighet för att minska ett avbrott, och dina databaser i en redundansgrupp kan vara otillgängliga under en tid som inte är acceptabel för serviceavtalet (SLA) för de program som använder databaserna. Databaser kan inte vara tillgängliga på grund av ett lokaliserat problem som påverkar bara några få databaser, eller på datacenter-, tillgänglighetszon- eller regionnivå. I något av dessa fall kan du initiera en tvingad failover för att återställa affärskontinuiteten.
Att ställa in din redundansprincip på kundhanterad rekommenderas starkteftersom du får kontroll över när du ska initiera en övergång till reservsystem och återställa driftskontinuitet. Du kan initiera en redundansväxling när du märker ett oväntat avbrott som påverkar en eller flera databaser i redundansgruppen.
Microsoft hanterad
Med en Microsoft-hanterad redundansprincip delegeras ansvaret för haveriberedskap till Azure SQL-tjänsten. För att Azure SQL-tjänsten ska kunna initiera en tvingad redundansväxling måste följande villkor uppfyllas:
- Avbrott på datacenter-, tillgänglighetszon- eller regionnivå som orsakas av en naturkatastrof, konfigurationsändringar, programvarubuggar eller maskinvarukomponentfel och många databaser i regionen påverkas.
- Respitperioden har upphört att gälla. Eftersom verifiering av omfattningen och hanteringen av avbrottet beror på mänskliga åtgärder, kan respitperioden inte sättas till under en timme.
När dessa villkor uppfylls initierar Azure SQL-tjänsten framtvingade redundansväxlingar för alla redundansgrupper i regionen som har redundansprincipen inställd på Microsoft hanterad.
Viktig
Använd kundhanterad redundansprincip för att testa och implementera din haveriberedskapsplan. Förlita dig inte på Microsofts hanterade failöver, som kanske bara utförs av Microsoft under extrema omständigheter. En Microsoft-hanterad failover initieras för alla failovergrupper i regionen som har en failoverpolicy inställd på Microsoft-hanterad. Det kan inte initieras för en enskild redundansgrupp. Om du behöver möjlighet att selektivt överväxla din failover-grupp, använder du en kundhanterad växlingsprincip.
Ange failover-policy som Microsoft-hanterad endast när:
- Du vill delegera ansvaret för haveriberedskap till Azure SQL-tjänsten.
- Programmet är tolerant mot att databasen inte är tillgänglig i minst en timme eller mer.
- Det är acceptabelt att utlösa framtvingade redundansväxlingar en tid efter att respitperioden upphör att gälla eftersom den faktiska tiden för den framtvingade redundansväxlingen kan variera avsevärt.
- Det är acceptabelt att alla databaser i redundansgruppen redundansväxlar, oavsett zonredundanskonfiguration eller tillgänglighetsstatus. Även om databaser som konfigurerats för zonredundans är motståndskraftiga mot zonfel och kanske inte påverkas av ett avbrott, kommer de fortfarande att redundansväxlas om de ingår i en redundansgrupp med en Microsoft-hanterad redundansprincip.
- Det är acceptabelt att ha framtvingade redundansväxlingar av databaser i redundansgruppen utan att ta hänsyn till programmets beroende av andra Azure-tjänster eller komponenter som används av programmet, vilket kan orsaka prestandaförsämring eller otillgänglighet för programmet.
- Det är acceptabelt att ådra sig en okänd mängd dataförlust eftersom den exakta tiden för tvingad redundans inte kan kontrolleras och ignorerar synkroniseringsstatusen för de sekundära databaserna.
- Alla primära och sekundära databaser i redundansgruppen och eventuella geo-replikeringsrelationer har samma tjänstnivå, beräkningsnivå (etablerad eller serverlös) & beräkningsstorlek (DTU:er eller virtuella kärnor). Om servicenivåmålet (SLO) för alla databaser inte matchar uppdateras redundanspolicyn så småningom från Microsoft Managed to Customer Managed by Azure SQL Service.
När Microsoft utlöser en failover läggs en post för åtgärden med namnet Failover i Azure SQL-failover-gruppen till i Azure Monitor-aktivitetsloggen. Posten innehåller namnet på redundansgruppen under Resurs, och Händelse initierad av visar ett bindestreck (-) som anger att övergången till redundans initierades av Microsoft. Den här informationen finns också på sidan aktivitetslogg på den nya primära servern eller instansen i Azure-portalen.
Terminologi och funktioner
redundansgrupp (FOG)
Med en redundansgrupp kan alla användardatabaser i en hanterad instans redundansväxla som en enhet till en annan Azure-region om den primära hanterade instansen blir otillgänglig på grund av ett avbrott i den primära regionen. Eftersom redundansgrupper för SQL Managed Instance innehåller alla användardatabaser i instansen kan endast en redundansgrupp konfigureras på en instans.
Viktig
Namnet på redundansgruppen måste vara globalt unikt inom den
.database.windows.netdomänen.primär
Den hanterade instansen som är värd för de primära databaserna i redundansgruppen.
sekundär
Den hanterade instansen som är värd för de sekundära databaserna i redundansgruppen. Den sekundära kan inte finnas i samma Azure-region som den primära.
Viktig
Om en databas innehåller minnesinterna OLTP-objekt måste den primära och sekundära geo-replikinstansen ha matchande tjänstnivåer, eftersom minnesinterna OLTP-objekt finns i minnet. En lägre tjänstnivå på geo-replikatinstansen kan leda till minnesbrist. Om detta inträffar kan den sekundära repliken misslyckas med att återställa databasen, vilket orsakar otillgänglighet för den sekundära databasen tillsammans med minnesinterna OLTP-objekt på den geo-sekundära. Detta kan i sin tur också leda till att redundans misslyckas. Undvik detta genom att se till att tjänstnivån för den geo-sekundära instansen matchar den primära databasens. Uppgraderingar på tjänstnivå kan vara datastorleksåtgärder och kan ta ett tag att slutföra.
Failover (ingen dataförlust)
Redundans utför fullständig datasynkronisering mellan primära och sekundära databaser innan den sekundära växlar till den primära rollen. Detta garanterar ingen dataförlust. Failover är bara möjlig när det primära systemet är tillgängligt. Failover används i följande scenarier:
- Utför katastrofåterställningstest (DR) i produktion när dataförlust inte är acceptabel
- Flytta arbetsbelastningen till en annan region
- Returnera arbetsbelastningen till den primära regionen efter att avbrottet har åtgärdats (återställning)
Tvingad failover (potentiell dataförlust)
Tvingad failover byter omedelbart ut den sekundära till den primära rollen utan att vänta på att de senaste ändringarna ska spridas från den primära. Den här åtgärden kan leda till potentiell dataförlust. Tvingad växling används som en återställningsmetod vid avbrott när det primära systemet inte är tillgängligt. När avbrotten har åtgärdats återansluter den gamla primära automatiskt och blir en ny sekundär. En failover kan köras för att återgå, vilket återställer replikerna till deras ursprungliga primära och sekundära roller.
respitperiod med dataförlust
Eftersom data replikeras till den sekundära med asynkron replikering kan en tvungen failover av grupper med Microsofts hanterade failoverprinciper leda till dataförlust. Du kan anpassa redundanspolicyn så att den återspeglar programmets tolerans mot dataförlust. Genom att konfigurera
GracePeriodWithDataLossHourskan du styra hur länge Azure SQL-tjänsten väntar innan du påbörjar en tvingad redundansväxling, vilket kan leda till dataförlust.
DNS-zon
Ett unikt ID som genereras automatiskt när en ny SQL Managed Instance skapas. Ett SAN-certifikat (Multi-Domain) för den här instansen etableras för att autentisera klientanslutningarna till alla instanser i samma DNS-zon. De två hanterade instanserna i samma redundansgrupp måste dela DNS-zonen.
Läs-och-skriv-listener för failover-grupp
En DNS CNAME-post som pekar på den aktuella primära servern. Den skapas automatiskt när failover-gruppen skapas och gör att läs- och skrivarbetsbelastningen kan transparent återanslutas till den primära noden när den primära noden ändras efter en failover. När redundansgruppen skapas på en SQL Managed Instance skapas DNS CNAME-posten för lyssnarens URL som
<fog-name>.<zone_id>.database.windows.net.skrivskyddad lyssnare för redundansgrupper
En DNS CNAME-post som pekar på den aktuella sekundära posten. Den skapas automatiskt när redundansgruppen skapas och tillåter att den skrivskyddade SQL-arbetsbelastningen utan avbrott ansluter till den sekundära servern när den sekundära servern ändras efter redundansväxling. När redundansgruppen skapas på en SQL Managed Instance skapas DNS CNAME-posten för lyssnarens URL som
<fog-name>.secondary.<zone_id>.database.windows.net. Som standardinställning inaktiveras övergången av den skrivskyddade lyssnaren eftersom det säkerställer att prestanda för den primära instansen inte påverkas när den sekundära instansen är offline. Men det innebär också att skrivskyddade sessioner inte kan ansluta förrän den sekundära servern har återställts. Om du inte kan tolerera driftstopp för skrivskyddade sessioner och kan använda den primära för både skriv- och lästrafik på bekostnad av den potentiella prestandaförsämringen av den primära, kan du aktivera failover för den skrivskyddade lyssnaren genom att konfigurera egenskapenAllowReadOnlyFailoverToPrimary. I så fall omdirigeras den skrivskyddade trafiken automatiskt till den primära om den sekundära inte är tillgänglig.Not
Egenskapen
AllowReadOnlyFailoverToPrimarygäller endast om Microsofts hanterade redundansprincip är aktiverad och en tvingad redundans har utlösts. I så fall, om egenskapen är inställd på True, kommer den nya primären att hantera både läs- och skriv- samt skrivskyddade sessioner.
Arkitektur för redundanskluster
Redundansgruppen måste konfigureras på den primära instansen och ansluter den till den sekundära instansen i en annan Azure-region. Alla användardatabaser i instansen replikeras till den sekundära instansen. Systemdatabaser som master och msdb replikeras inte.
Följande diagram illustrerar en typisk konfiguration av ett geo-redundant molnprogram med hjälp av hanterad instans och redundansgrupp:
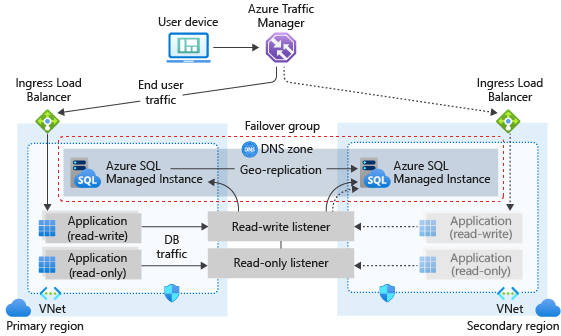
Om ditt program använder SQL Managed Instance som datanivå följer du de allmänna riktlinjer och metodtips som beskrivs i den här artikeln när du utformar för affärskontinuitet.
Skapa den geo-sekundära instansen
För att säkerställa en oavbruten anslutning till den primära SQL Managed Instance efter redundansväxlingen måste både de primära och sekundära instanserna finnas i samma DNS-zon. Det garanterar att samma SAN-certifikat (multi-domain) kan användas för att autentisera klientanslutningar till någon av de två instanserna i redundansgruppen. När ditt program är redo för produktionsdistribution skapar du en sekundär SQL Managed Instance i en annan region och ser till att den delar DNS-zonen med den primära SQL Managed Instance. Du kan göra det genom att ange en valfri parameter när du skapar den. Om du använder PowerShell eller REST-API:et är namnet på den valfria parametern DNSZonePartner. Namnet på motsvarande valfria fält i Azure-portalen är primär hanterad instans.
Viktig
Den första hanterade instansen som skapas i undernätet avgör DNS-zonen för alla efterföljande instanser i samma undernät. Det innebär att två instanser från samma undernät inte kan tillhöra olika DNS-zoner.
Mer information om hur du skapar den sekundära SQL Managed Instance i samma DNS-zon som den primära instansen finns i Konfigurera en redundansgrupp för Azure SQL Managed Instance.
Använda parkopplade regioner
Distribuera båda hanterade instanserna till de parkopplade regionerna och för prestandaskäl. SQL Managed Instance-failovergrupper i parkopplade regioner har bättre prestanda jämfört med regioner som inte är parkopplade.
Azure SQL Managed Instance följer en säker distributionspraxis där azure-kopplade regioner vanligtvis inte distribueras till på samma gång. Det går dock inte att förutsäga vilken region som ska uppgraderas först, så distributionsordningen är inte garanterad. Ibland uppgraderas den primära instansen först och ibland uppgraderas den sekundära instansen först.
I situationer där Azure SQL Managed Instance ingår i en redundansgruppoch instanserna i gruppen inte finns i Azure-kopplade regionerväljer du olika underhållsfönsterscheman för din primära och sekundära databas. Välj till exempel en veckodagsunderhållsperiod för din geo-sekundära databas och en helgunderhållsperiod för din geo-primära databas.
Aktivera och optimera trafikflödet för geo-replikering mellan instanserna
Anslutningen mellan de virtuella nätverkets undernät som är värdar för den primära och sekundära instansen måste upprättas och underhållas för ett obrutet trafikflöde vid geo-replikering. Det finns flera sätt att tillhandahålla anslutning mellan de instanser som du kan välja mellan baserat på din nätverkstopologi och principer:
global peering för virtuella nätverk (VNet-peering) är det rekommenderade sättet att upprätta anslutning mellan två instanser i en redundansgrupp. Det ger en privat anslutning med låg svarstid och hög bandbredd mellan peer-kopplade virtuella nätverk med hjälp av Microsofts staminfrastruktur. Inget offentligt Internet, gatewayer eller ytterligare kryptering krävs i kommunikationen mellan de peerkopplade virtuella nätverken.
Inledande seeding
När du upprättar en redundansgrupp mellan hanterade instanser finns det en inledande seeding-fas innan datareplikeringen startar. Den inledande seedningsfasen är den längsta och dyraste delen av åtgärden. När den första seedingen har slutförts synkroniseras data och endast efterföljande dataändringar replikeras. Den tid det tar för den inledande seedningen att slutföras beror på storleken på data, antalet replikerade databaser, arbetsbelastningsintensiteten på de primära databaserna och hastigheten på länken mellan de virtuella nätverk som är värdar för den primära och sekundära instansen som främst beror på hur anslutningen upprättas. Under normala omständigheter, och när anslutningen upprättas med rekommenderad global peering för virtuella nätverk, är starthastigheten upp till 360 GB i timmen för SQL Managed Instance. Seeding utförs för en batch med användardatabaser parallellt – inte nödvändigtvis för alla databaser samtidigt. Flera batchar kan behövas om det finns många databaser på instansen.
Om länkens hastighet mellan de två instanserna är långsammare än nödvändigt påverkas sannolikt tiden för seedning märkbart. Du kan använda angiven seedinghastighet, antal databaser, total datastorlek och länkhastigheten för att uppskatta hur lång tid den inledande seeding-fasen tar innan datareplikeringen startar. För en enskild databas på 100 GB skulle den inledande startfasen till exempel ta cirka 1,2 timmar om länken kan push-överföra 84 GB per timme och om det inte finns några andra databaser som seedas. Om länken bara kan överföra 10 GB per timme kan det ta cirka 10 timmar att skicka en databas på 100 GB. Om det finns flera databaser att replikera körs seeding parallellt, och när den kombineras med en långsam länkhastighet kan den inledande seeding-fasen ta betydligt längre tid, särskilt om parallell seeding av data från alla databaser överskrider den tillgängliga länkbandbredden.
Viktig
Om en extremt låg hastighetslänk eller upptagen länk gör att den inledande initieringsfasen tar dagar, kan skapandet av en failover-grupp komma att tidsgränsas. Skapandeprocessen avbryts automatiskt efter 6 dagar.
Hantera geo-redundans till en geo-sekundär instans
Redundansgruppen hanterar geo-redundans för alla databaser på den primära hanterade instansen. När en grupp skapas geo-replikeras varje databas i instansen automatiskt till den geo-sekundära instansen. Du kan inte använda failover-grupper för att initiera en partiell failover av en delmängd databaser.
Viktig
Om en databas tas bort på den primära hanterade instansen tas den också bort automatiskt på den geo-sekundära hanterade instansen.
Använda läs- och skrivlyssnaren (primär MI)
För läs- och skrivarbetsbelastningar använder du <fog-name>.zone_id.database.windows.net som servernamn. Anslutningar dirigeras automatiskt till den primära. Det här namnet ändras inte efter växlingen. Geo-failover innebär att DNS-posten uppdateras, så de nya klientanslutningarna dirigeras till den nya primära servern först efter att klientens DNS-cache har uppdaterats. Eftersom den sekundära instansen delar DNS-zonen med den primära kan klientprogrammet återansluta till den med samma SAN-certifikat på serversidan. De befintliga klientanslutningarna måste avslutas och sedan återskapas för att dirigeras till det nya primära systemet. Det går inte att nå både den läs- och skrivbara lyssnaren och den skrivskyddade lyssnaren via den offentlig slutpunkten för den hanterade instansen.
Använd den skrivskyddade lyssnaren (sekundär MI)
Om du har logiskt isolerade skrivskyddade arbetsbelastningar som är toleranta mot fördröjningar i data kan du köra dem på det geo-sekundära systemet. Om du vill ansluta direkt till den geo-sekundära använder du <fog-name>.secondary.<zone_id>.database.windows.net som servernamn.
På nivån Affärskritisk stöder SQL Managed Instance användning av skrivskyddade repliker för att avlasta skrivskyddade frågearbetsbelastningar med hjälp av parametern ApplicationIntent=ReadOnly i anslutningssträngen. När du har konfigurerat en geo-replikerad sekundär kan du använda den här funktionen för att ansluta till antingen en skrivskyddad replik på den primära platsen eller på den geo-replikerade platsen:
- Om du vill ansluta till en skrivskyddad replik på den primära platsen använder du
ApplicationIntent=ReadOnlyoch<fog-name>.<zone_id>.database.windows.net. - Om du vill ansluta till en skrivskyddad replik på den sekundära platsen använder du
ApplicationIntent=ReadOnlyoch<fog-name>.secondary.<zone_id>.database.windows.net.
Det går inte att nå den skriv-och-läköppna lyssnaren och den skrivskyddade lyssnaren via offentlig slutpunkt för hanterad instans.
Potentiell prestandaförsämring efter omkoppling
Ett typiskt Azure-program använder flera Azure-tjänster och består av flera komponenter. Geo-redundans för gruppen utlöses baserat på tillståndet för enbart Azure SQL-komponenterna. Andra Azure-tjänster i den primära regionen kanske inte påverkas av avbrotten och deras komponenter kan fortfarande vara tillgängliga i den regionen. När de primära databaserna växlar till den sekundära regionen kan svarstiden mellan de beroende komponenterna öka. Kontrollera redundansen för alla programmets komponenter i den sekundära regionen och redundansväxla programkomponenter tillsammans med databasen så att programmets prestanda inte påverkas av längre svarstider mellan regioner.
Potentiell dataförlust efter tvingad redundans
Om ett avbrott inträffar i den primära regionen kanske de senaste transaktionerna inte har replikerats till den geo-sekundära och det kan uppstå dataförlust om en tvingad redundans utförs.
DNS-uppdatering
DNS-uppdateringen av läs-och-skrivlyssnare sker omedelbart efter att failover har initierats. Den här åtgärden resulterar inte i dataförlust. Det kan dock ta upp till 5 minuter att byta databasroller under normala förhållanden. Tills den har slutförts är vissa databaser i den nya primära instansen fortfarande skrivskyddade. Om en redundansväxling initieras med PowerShell är åtgärden för att växla den primära replikrollen synkron. Om det initieras med hjälp av Azure-portalen anger användargränssnittet slutförandestatus. Om det initieras med hjälp av REST API använder du Azure Resource Manager-avsökningsmekanismen som standard för att övervaka slutförandet.
Viktig
Använd manuell planerad redundans för att flytta den primära tillbaka till den ursprungliga platsen när det avbrott som orsakade geo-redundansen har åtgärdats.
Spara kostnader med en licensfri DR-replik
Du kan spara på SQL Server-licenskostnader genom att konfigurera att din sekundära hanterade instans endast ska användas för haveriberedskap (DR). Information om hur du konfigurerar detta finns i Konfigurera en licensfri standby-replik för Azure SQL Managed Instance.
Så länge den sekundära instansen inte används för läsarbetsbelastningar ger Microsoft dig ett kostnadsfritt antal virtuella kärnor som matchar den primära instansen. Du debiteras fortfarande för beräkning och lagring som används av den sekundära instansen. Redundansgrupper stöder endast en replik – repliken måste antingen vara läsbar eller endast DR-replik.
Aktivera scenarier som är beroende av objekt från systemdatabaserna
Systemdatabaser inte replikeras till den sekundära instansen i en failover-grupp. Om du vill aktivera scenarier som är beroende av objekt från systemdatabaserna måste du skapa samma objekt på den sekundära instansen och hålla dem synkroniserade med den primära instansen.
Om du till exempel planerar att använda samma inloggningar på den sekundära instansen måste du skapa dem med samma SID.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Mer information finns i Replikering av inloggningar och agentjobb.
Synkronisera instansegenskaper och tillämpningar av kvarhållningsprinciper
Instanser i en redundansgrupp förblir separata Azure-resurser och inga ändringar som görs i konfigurationen av den primära instansen replikeras automatiskt till den sekundära instansen. Se till att utföra alla relevanta ändringar både på den primära och sekundära instansen. Om du till exempel ändrar redundans för lagring av säkerhetskopior eller långsiktig kvarhållningsprincip för säkerhetskopiering på den primära instansen måste du även ändra den på den sekundära instansen.
Skala instanser
Du kan skala upp eller skala ned den primära och sekundära instansen till en annan beräkningsstorlek inom samma tjänstnivå eller till en annan tjänstnivå. När du skalar upp inom samma tjänstnivå rekommenderar vi att du skalar upp den geo-sekundära först och sedan skalar upp den primära. När du skalar ned inom samma tjänstnivå ändrar du ordningen: skala ned den primära först och skala sedan ned den sekundära. När du skalar instansen till en annan tjänstnivå tillämpas den här rekommendationen. Åtgärdssekvensen tillämpas vid skalning av tjänstnivån och virtuella kärnor samt lagring.
Sekvensen rekommenderas specifikt för att undvika problemet där det geo-sekundära systemet som använder en lägre SKU överbelastas och måste nyplanteras under en uppgraderings- eller nedgraderingsprocess.
Viktig
- För instanser i en redundansgrupp stöds inte att ändra tjänstnivån till eller från nivån Nästa generations generell användning. Du måste först ta bort failover-gruppen innan du ändrar någon av replikerna och sedan återskapa failover-gruppen när ändringen träder i kraft.
- Det finns ett känt problem som kan påverka tillgängligheten för den instans som skalas med hjälp av den associerade redundansgruppens lyssnare.
Förhindra förlust av kritiska data
På grund av den långa svarstiden för nätverk i stora områden använder geo-replikering en asynkron replikeringsmekanism. Asynkron replikering gör risken för dataförlust oundviklig om den primära replikeringen misslyckas. För att skydda kritiska transaktioner mot dataförlust kan en programutvecklare anropa den sp_wait_for_database_copy_sync lagrade proceduren omedelbart efter att transaktionen har genomförts. Att anropa sp_wait_for_database_copy_sync blockerar den anropande tråden tills den senaste commiterade transaktionen har överförts och härdats i transaktionsloggen på den sekundära databasen. Det väntar dock inte på att de överförda transaktionerna ska spelas upp igen (upprepas) på den sekundära servern.
sp_wait_for_database_copy_sync är begränsad till en specifik geo-replikeringslänk. Alla användare med anslutningsrättigheter till den primära databasen kan anropa den här proceduren.
För att förhindra dataförlust under användarinitierad, planerad geo-failover ändrar replikeringen automatiskt och tillfälligt till synkron replikering och utför en redundansväxling. Replikeringen återgår sedan till asynkront läge när geo-failover är klar.
Obs
sp_wait_for_database_copy_sync förhindrar dataförlust efter geo-felövergång för specifika transaktioner, men garanterar inte fullständig synkronisering för läsåtkomst. Fördröjningen som orsakas av ett sp_wait_for_database_copy_sync proceduranrop kan vara betydande och beror på storleken på den ännu inte överförda transaktionsloggen på den primära vid tidpunkten för anropet.
Status för failover-grupp
Redundansgruppen rapporterar sin status och beskriver det nuvarande tillståndet för datareplikeringen.
- Seeding – Inledande seeding sker efter att redundansgruppen har skapats tills alla användardatabaser initieras på den sekundära instansen. Överlagningsprocessen kan inte initieras när failover-gruppen är i statusen Seeding, eftersom användardatabaser ännu inte har kopierats till den sekundära instansen.
- Synkronisering – normalstatus för failovergrupp. Det innebär att dataändringar på den primära instansen replikeras asynkront till den sekundära instansen. Den här statusen garanterar inte att data synkroniseras fullständigt varje gång. Det kan finnas dataändringar från den primära som fortfarande ska replikeras till den sekundära på grund av replikeringsprocessens asynkrona karaktär mellan instanser i redundansgruppen. Både automatiska och manuella redundansväxlingar kan initieras medan redundansgruppen har statusen Synkronisering.
- Redundans pågår – den här statusen anger att antingen automatiskt eller manuellt initierad redundans pågår. Inga ändringar i redundansgruppen eller ytterligare överflyttningar kan initieras medan redundansgruppen har den här statusen.
Återställning efter fel
När redundansgrupper konfigureras med en Microsoft-hanterad redundansprincip initieras tvingad redundans till den geo-sekundära servern under ett katastrofscenario enligt den definierade respitperioden. Återställning till den gamla primären måste initieras manuellt.
Funktionskompatibilitet
Säkerhetskopior
En fullständig säkerhetskopia görs i följande scenarier:
- Innan den första seedingen börjar när du skapar en redundansgrupp.
- Efter en redundansväxling.
En fullständig säkerhetskopiering är en process som inte kan hoppas över eller skjutas upp och kan ta en stund att slutföra. Den tid det tar att slutföra beror på storleken på data, antalet databaser och arbetsbelastningsintensiteten på de primära databaserna. En fullständig säkerhetskopia kan märkbart fördröja den inledande seedingen och kan antingen fördröja eller förhindra en redundansåtgärd på en ny instans strax efter en redundansväxling.
Loggåterspelningstjänst
Databaser som migreras till Azure SQL Managed Instance med hjälp av Log Replay Service (LRS) kan inte läggas till i en redundansgrupp förrän snabbsteget har körts. En databas som migreras med LRS är i ett återställningsläge tills övergången, och databaser i återställningsläge kan inte läggas till i en failover-grupp. Försök att skapa en redundansgrupp med en databas i återställningstillstånd fördröjer skapandet av redundansgruppen tills databasåterställningen har slutförts.
Transaktionsreplikering
Användning av transaktionsreplikering med instanser som finns i en redundansgrupp stöds. Men om du konfigurerar replikering innan du lägger till din SQL-hanterade instans i en redundansgrupp pausar replikeringen när du börjar skapa redundansgruppen och replikeringsövervakaren visar statusen Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. Replikeringen återupptas när redundansgruppen har skapats framgångsrikt.
Om en utgivare-nod eller distributör-nod SQL-hanterad instans finns i en redundansgrupp, måste SQL-hanterad instansadministratören rensa alla publikationer på den gamla primära noden och konfigurera om dem på den nya primära noden när en redundansväxling inträffar. Granska transaktionsreplikeringsguiden för aktivitetsstegen som behövs i det här scenariot.
Behörigheter och begränsningar
Granska en lista över behörigheter och begränsningar innan du konfigurerar en redundansgrupp.
Hantera redundansgrupper programmatiskt
Redundansgrupper kan också hanteras programmatiskt med hjälp av Azure PowerShell, Azure CLI och REST API. Granska konfigurera redundansgrupp för att lära dig mer.
Haveriberedskapstest
Det rekommenderade sättet att utföra ett DR-test är att använda manuell planerad omkoppling, enligt följande handledning: Test failover.
Att utföra ett test med tvingad redundansväxling rekommenderas inteeftersom den här åtgärden inte ger skyddsräcken mot dataförlusten. Det är dock möjligt att uppnå dataförlustfri tvingad redundans genom att se till att följande villkor uppfylls innan den framtvingade redundansväxlingen initieras:
- Arbetsbelastningen stoppas på den primära hanterade instansen.
- Alla långvariga transaktioner har slutförts.
- Alla klientanslutningar till den primära hanterade instansen har kopplats från.
- status för redundansgrupper är Synkronisering.
Kontrollera att de två hanterade instanserna har växlade roller och att statusen för redundansklustergruppen har växlat från "Redundans pågår" till "Synkronisering" innan du eventuellt upprättar anslutningar till den nya primära hanterade instansen och startar läs- och skrivarbetsbelastning.
För att utföra en dataförlustfri återställning till de ursprungliga hanterade instansrollerna rekommenderar vi att du använder manuell planerad redundans i stället för tvingad redundansväxling starkt. Om tvingad felåterställning används:
- Följ samma steg som för dataförlustfri övergång.
- Längre körningstid för återställning efter omläggning förväntas om den tvingade återställningen utförs strax efter att den första tvingade redundansväxlingen har slutförts, eftersom den måste vänta tills alla utestående automatiska säkerhetskopieringsåtgärder på den tidigare primära hanterade instansen har slutförts.
- Eventuella utestående automatiska säkerhetskopieringsåtgärder på den hanterade instansen som övergår från den primära till den sekundära rollen påverkar databasens tillgänglighet på den här instansen.
- Använd statusen för redundansgrupper för att avgöra om båda instanserna har ändrat sina roller och är redo att acceptera klientanslutningar.
Relaterat innehåll
- Konfigurera en redundansgrupp
- Använda PowerShell för att lägga till en hanterad instans i en redundansgrupp
- Konfigurera en licensfri standby-replik för Azure SQL Managed Instance
- Översikt över affärskontinuitet med Azure SQL Managed Instance
- Automatiserade säkerhetskopieringar i Azure SQL Managed Instance
- Återställa en databas från en säkerhetskopia i Azure SQL Managed Instance