Hızlı Başlangıç: Azure Machine Learning'de Apache Spark ile Etkileşimli Veri Düzenleme
Etkileşimli Azure Machine Learning not defteri veri düzenlemesini işlemek için Azure Synapse Analytics ile Azure Machine Learning tümleştirmesi Apache Spark çerçevesine kolay erişim sağlar. Bu erişim, Azure Machine Learning Not Defteri etkileşimli veri düzenlemesine olanak tanır.
Bu hızlı başlangıç kılavuzunda Azure Machine Learning sunucusuz Spark işlemi, Azure Data Lake Storage (ADLS) 2. Nesil depolama hesabı ve kullanıcı kimliği geçişi ile etkileşimli veri düzenleme gerçekleştirmeyi öğreneceksiniz.
Önkoşullar
- Azure aboneliği; Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
- Azure Machine Learning çalışma alanı. Çalışma alanı kaynakları oluşturma'ya bakın.
- Azure Data Lake Storage (ADLS) 2. Nesil depolama hesabı. Azure Data Lake Storage (ADLS) 2. Nesil depolama hesabı oluşturma'yı ziyaret edin.
Azure Key Vault'ta Azure depolama hesabı kimlik bilgilerini gizli dizi olarak depolama
Azure depolama hesabı kimlik bilgilerini Azure portal kullanıcı arabirimiyle Azure Key Vault'ta gizli dizi olarak depolamak için:
Azure portalında Azure Key Vault'unuza gidin
Sol panelden Gizli Diziler'i seçin
+ Oluştur/İçeri Aktar'ı seçin
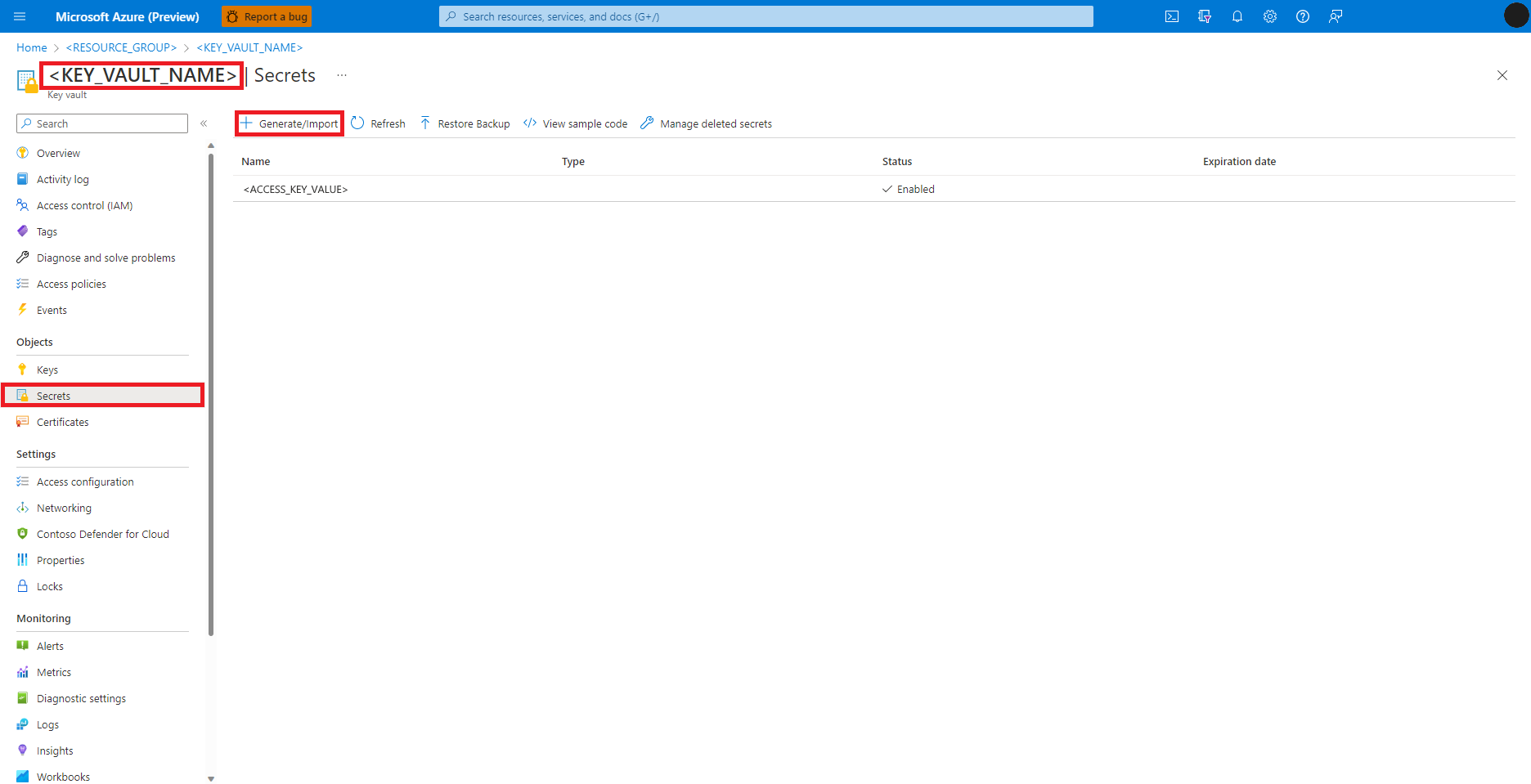
Gizli dizi oluştur ekranında, oluşturmak istediğiniz gizli dizi için bir Ad girin
Bu görüntüde gösterildiği gibi Azure portalında Azure Blob Depolama Hesabı'na gidin:
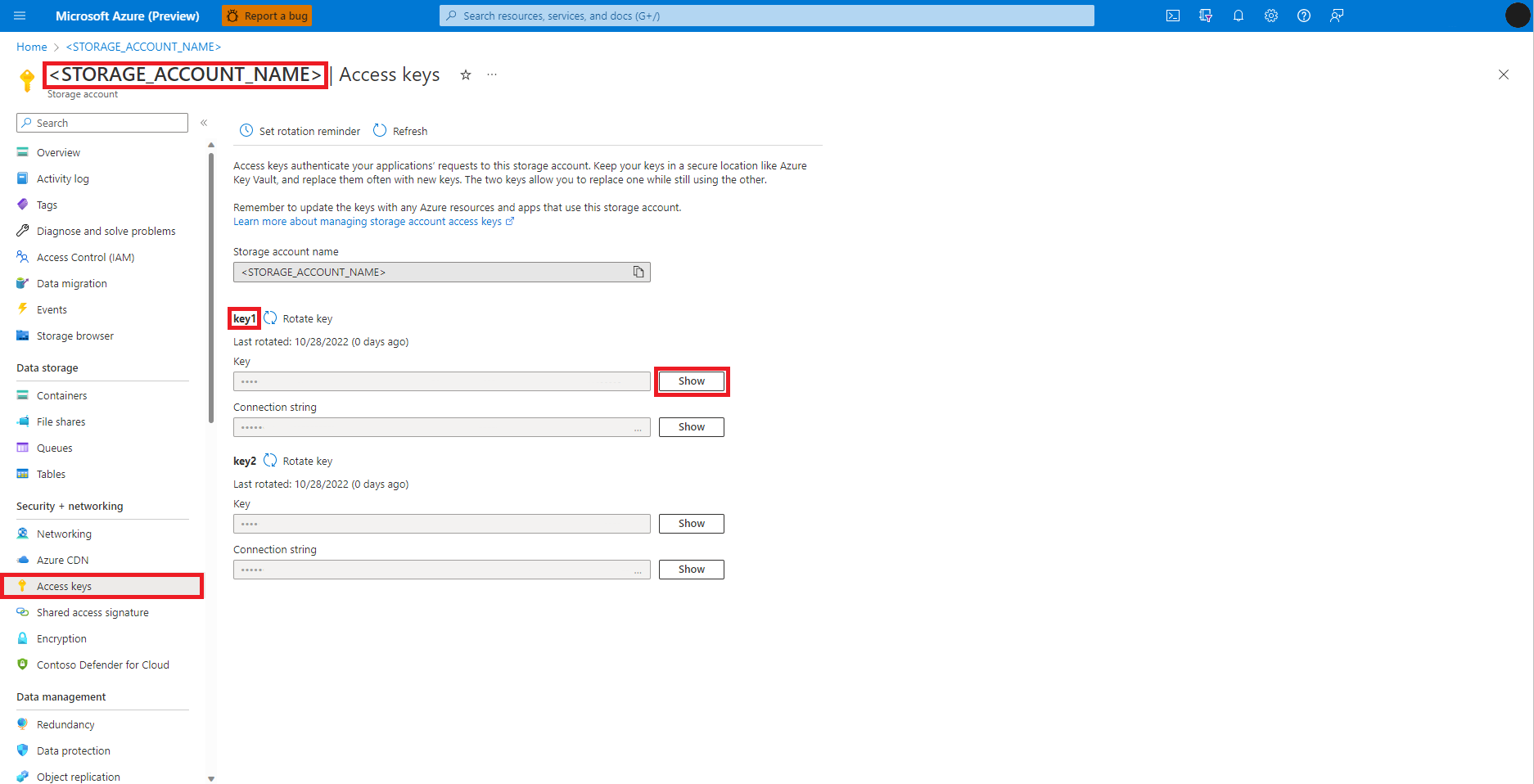
Azure Blob Depolama Hesabı sayfası sol panelinden Erişim anahtarları'nı seçin
Depolama hesabı erişim anahtarını almak için Anahtar 1'in yanındaki Göster'i ve ardından Panoya kopyala'yı seçin
Not
Kopyalamak için uygun seçenekleri belirtin
- Azure Blob depolama kapsayıcısı paylaşılan erişim imzası (SAS) belirteçleri
- Azure Data Lake Storage (ADLS) 2. Nesil depolama hesabı hizmet sorumlusu kimlik bilgileri
- kiracının kimliği:
- istemci kimliği ve
- gizli dizi
bunlar için Azure Key Vault gizli dizilerini oluştururken ilgili kullanıcı arabirimlerinde
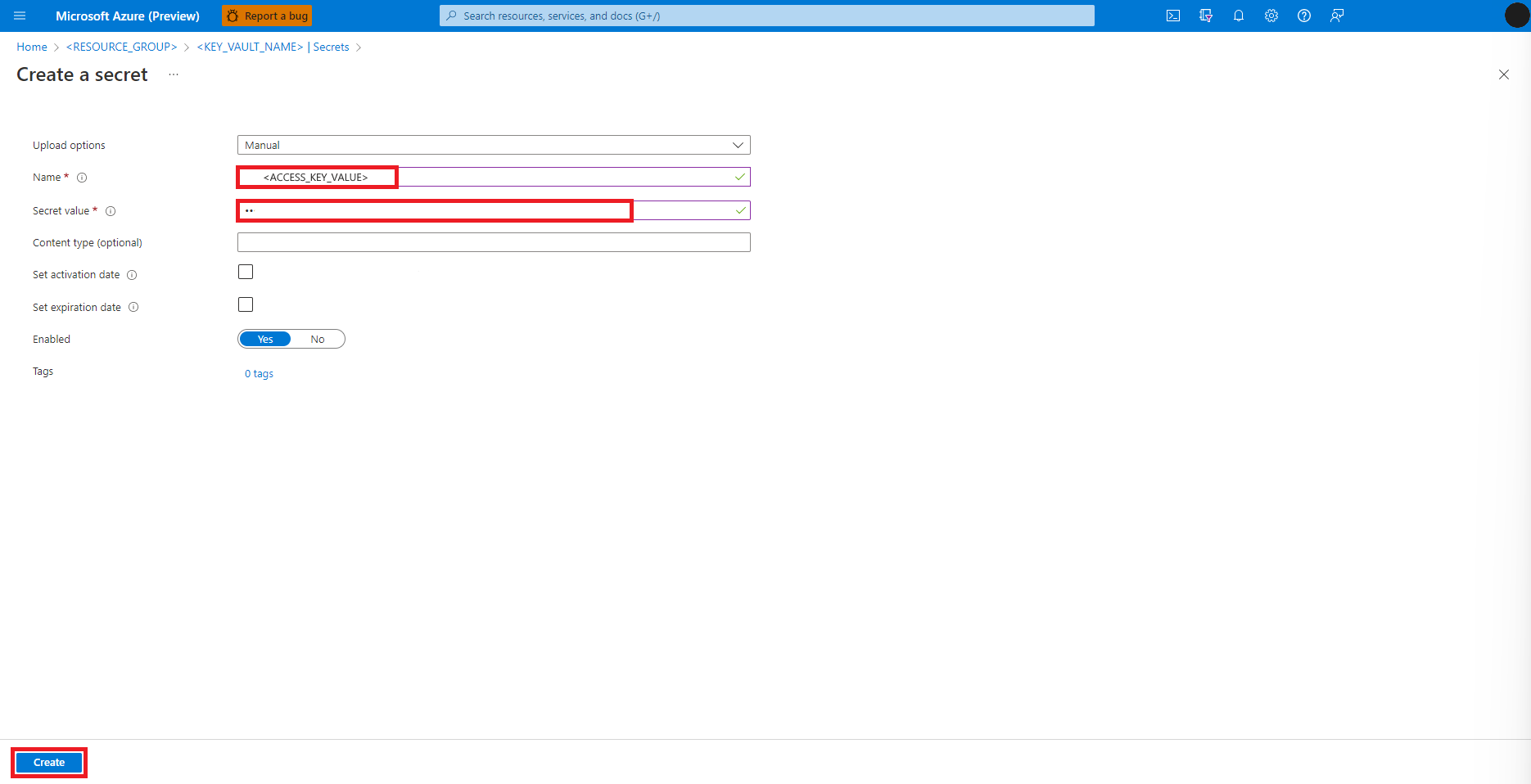
Gizli dizi oluşturma ekranına geri dönün
Gizli dizi değeri metin kutusuna, önceki adımda panoya kopyalanan Azure depolama hesabının erişim anahtarı kimlik bilgilerini girin
Oluştur'u seçin
İpucu
Python için Azure CLI ve Azure Key Vault gizli dizi istemci kitaplığı da Azure Key Vault gizli dizileri oluşturabilir.
Azure depolama hesaplarında rol atamaları ekleme
Etkileşimli veri düzenlemeye başlamadan önce giriş ve çıkış veri yollarının erişilebilir olduğundan emin olmamız gerekir. İlk olarak,
Oturum açmış Not Defterleri oturumunun kullanıcı kimliği
veya
hizmet sorumlusu
Oturum açmış kullanıcının kullanıcı kimliğine Okuyucu ve Depolama Blobu Veri Okuyucusu rolleri atayın. Ancak bazı senaryolarda, düzenlenmiş verileri Azure depolama hesabına geri yazmak isteyebiliriz. Okuyucu ve Depolama Blob Veri Okuyucusu rolleri, kullanıcı kimliğine veya hizmet sorumlusuna salt okunur erişim sağlar. Okuma ve yazma erişimini etkinleştirmek için, kullanıcı kimliğine veya hizmet sorumlusuna Katkıda Bulunan ve Depolama Blob Verileri Katkıda Bulunanı rollerini atayın. Kullanıcı kimliğine uygun rolleri atamak için:
Microsoft Azure portalını açma
Depolama hesapları hizmetini arama ve seçme

Depolama hesapları sayfasında, listeden Azure Data Lake Storage (ADLS) 2. Nesil depolama hesabını seçin. Depolama hesabına Genel Bakış'ın gösterildiği bir sayfa açılır

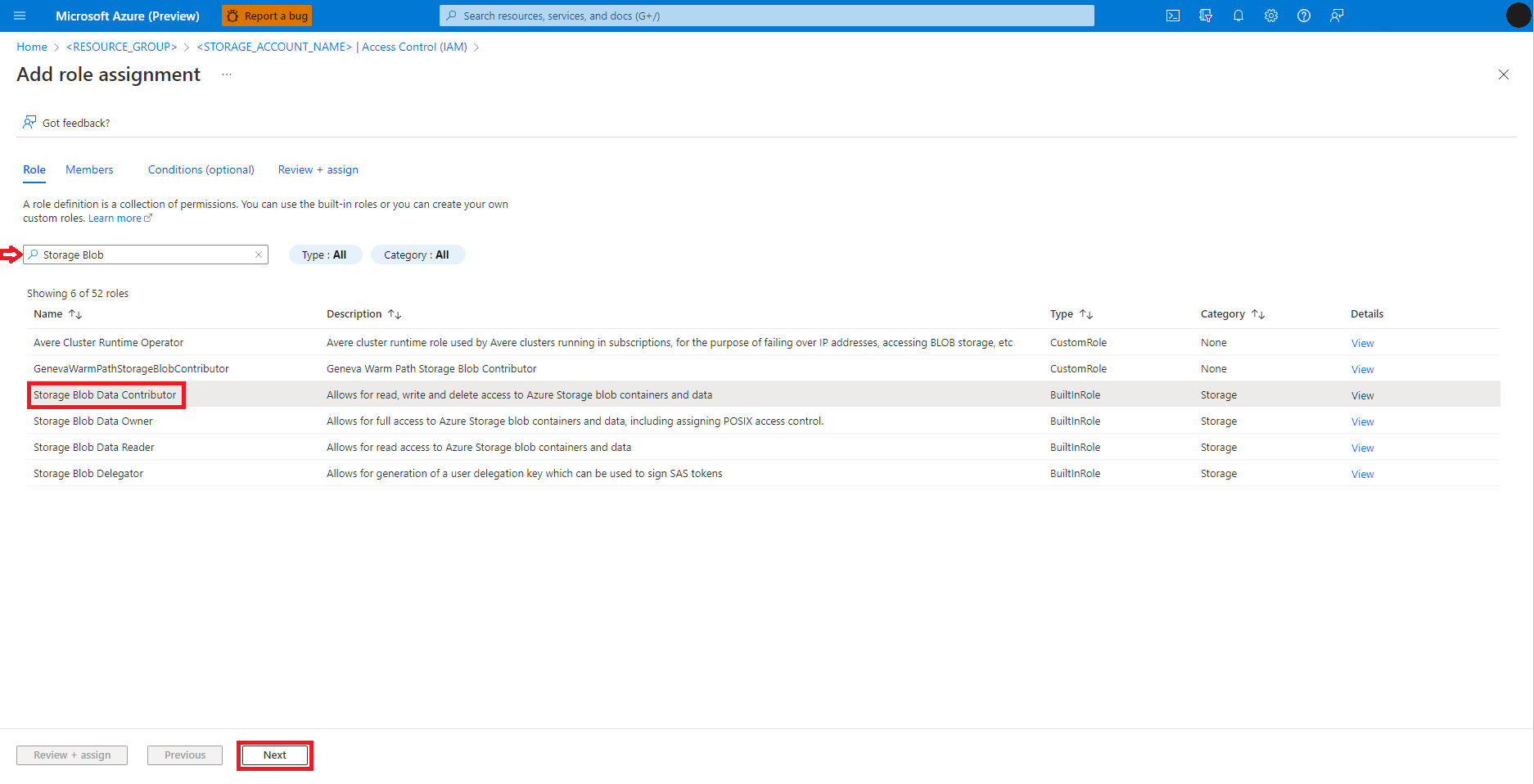
Sol panelden Erişim Denetimi (IAM) seçeneğini belirleyin
Rol ataması ekle'yi seçin

Depolama Blobu Veri Katkıda Bulunanı rolünü bulma ve seçme
İleri'yi seçin
Kullanıcı, grup veya hizmet sorumlusu seçin
+ Üye seç'i seçin
Seç'in altında kullanıcı kimliğini arayın
Listeden kullanıcı kimliğini seçerek Seçili üyeler altında görünür
Uygun kullanıcı kimliğini seçin
İleri'yi seçin

Gözden Geçir + Ata'yı seçin
Katkıda Bulunan rolü ataması için 2-13 arası adımları yineleyin






Kullanıcı kimliğine uygun roller atandıktan sonra Azure depolama hesabındaki veriler erişilebilir hale gelmelidir.
Not
Ekli bir Synapse Spark havuzu Synapse Spark havuzuna işaret ederse, kendisiyle ilişkilendirilmiş yönetilen bir sanal ağa sahip olan bir Azure Synapse çalışma alanında, veri erişimi sağlamak için depolama hesabına yönetilen bir özel uç nokta yapılandırmanız gerekir.
Spark işleri için kaynak erişimini sağlama
Spark işleri, verilere ve diğer kaynaklara erişmek için yönetilen kimlik veya kullanıcı kimliği geçişi kullanabilir. Aşağıdaki tabloda, Azure Machine Learning sunucusuz Spark işlemini ve ekli Synapse Spark havuzunu kullanırken kaynak erişimi için farklı mekanizmalar özetlenmiştir.
| Spark havuzu | Desteklenen kimlikler | Varsayılan kimlik |
|---|---|---|
| Sunucusuz Spark işlem | Çalışma alanına eklenen kullanıcı kimliği, kullanıcı tarafından atanan yönetilen kimlik | Kullanıcı kimliği |
| Ekli Synapse Spark havuzu | Kullanıcı kimliği, ekli Synapse Spark havuzuna eklenen kullanıcı tarafından atanan yönetilen kimlik, ekli Synapse Spark havuzunun sistem tarafından atanan yönetilen kimliği | Ekli Synapse Spark havuzunun sistem tarafından atanan yönetilen kimliği |
CLI veya SDK kodu yönetilen kimliği kullanma seçeneği tanımlıyorsa Azure Machine Learning sunucusuz Spark işlem, çalışma alanına eklenen kullanıcı tarafından atanan yönetilen kimliği kullanır. Azure Machine Learning CLI v2 veya ile ARMClientmevcut bir Azure Machine Learning çalışma alanına kullanıcı tarafından atanan yönetilen kimlik ekleyebilirsiniz.
Sonraki adımlar
- Azure Machine Learning'de Apache Spark
- Azure Machine Learning'de Synapse Spark havuzu ekleme ve yönetme
- Azure Machine Learning'de Apache Spark ile Etkileşimli Veri Düzenleme
- Azure Machine Learning'de Spark işlerini gönderme
- Azure Machine Learning CLI kullanarak Spark işleri için kod örnekleri
- Azure Machine Learning Python SDK'sını kullanarak Spark işleri için kod örnekleri