Azure Machine Learning'de Spark işlerini gönderme
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Azure CLI ml uzantısı v2 (geçerli)Python SDK azure-ai-ml v2 (geçerli)
Azure Machine Learning, tek başına makine öğrenmesi iş gönderimlerini ve birden çok makine öğrenmesi iş akışı adımı içeren makine öğrenmesi işlem hatlarının oluşturulmasını destekler. Azure Machine Learning hem tek başına Spark işi oluşturmayı hem de Azure Machine Learning işlem hatlarının kullanabileceği yeniden kullanılabilir Spark bileşenlerinin oluşturulmasını işler. Bu makalede Spark işlerini göndermeyi aşağıdakilerle öğreneceksiniz:
- Azure Machine Learning stüdyosu kullanıcı arabirimi
- Azure Machine Learning CLI
- Azure Machine Learning SDK’sı
Azure Machine Learning kavramlarında Apache Spark hakkında daha fazla bilgi için bu kaynağı ziyaret edin.
Önkoşullar
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
- Azure aboneliği; Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
- Azure Machine Learning çalışma alanı. Daha fazla bilgi için Çalışma alanı kaynakları oluşturma'ya bakın.
- Azure Machine Learning işlem örneği oluşturma.
- Azure Machine Learning CLI'sını yükleyin.
- (İsteğe bağlı): Azure Machine Learning çalışma alanında ekli bir Synapse Spark havuzu.
Not
- Azure Machine Learning sunucusuz Spark işlemini ve ekli Synapse Spark havuzunu kullanırken kaynak erişimi hakkında daha fazla bilgi için Spark işleri için kaynak erişimi sağlama bölümünü ziyaret edin.
- Azure Machine Learning, tüm kullanıcıların sınırlı bir süre için test gerçekleştirmek için işlem kotasına erişebildiği paylaşılan bir kota havuzu sağlar. Sunucusuz Spark işlemini kullandığınızda, Azure Machine Learning bu paylaşılan kotaya kısa bir süre erişmenizi sağlar.
CLI v2 kullanarak kullanıcı tarafından atanan yönetilen kimliği ekleme
- Çalışma alanına eklenmesi gereken kullanıcı tarafından atanan yönetilen kimliği tanımlayan bir YAML dosyası oluşturun:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - parametresiyle
--file, kullanıcı tarafından atanan yönetilen kimliği eklemek için komutundakiaz ml workspace updateYAML dosyasını kullanın:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Kullanarak kullanıcı tarafından atanan yönetilen kimliği ekleme ARMClient
- Azure Resource Manager API'sini çağıran basit bir komut satırı aracı yükleyin
ARMClient. - Çalışma alanına eklenmesi gereken kullanıcı tarafından atanan yönetilen kimliği tanımlayan bir JSON dosyası oluşturun:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Kullanıcı tarafından atanan yönetilen kimliği çalışma alanına eklemek için PowerShell isteminde veya komut isteminde aşağıdaki komutu yürütebilirsiniz.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Not
- Spark işinin başarıyla yürütülmesini sağlamak için, Veri girişi ve çıkışı için kullanılan Azure depolama hesabında Katkıda Bulunan ve Depolama Blobu Veri Katkıda Bulunanı rollerini Spark işinin kullandığı kimliğe atayın
- Spark işinin ekli synapse Spark havuzu kullanılarak başarıyla yürütülmesini sağlamak için Azure Synapse çalışma alanında Genel Ağ Erişimi etkinleştirilmelidir.
- Kendisiyle ilişkilendirilmiş yönetilen bir sanal ağa sahip bir Azure Synapse çalışma alanında, ekli bir Synapse Spark havuzu Synapse Spark havuzuna işaret ederse, veri erişimini sağlamak için depolama hesabına yönetilen bir özel uç nokta yapılandırmanız gerekir.
- Sunucusuz Spark işlem, Azure Machine Learning yönetilen sanal ağını destekler. Sunucusuz Spark işlemi için yönetilen bir ağ sağlanırsa, veri erişimini sağlamak için depolama hesabına karşılık gelen özel uç noktalar da sağlanmalıdır .
Tek başına Spark işi gönderme
Python betiği parametreleştirmesi için gerekli değişiklikleri yaptıktan sonra, daha büyük hacimli verileri işlemek üzere toplu iş göndermek üzere etkileşimli veri düzenlemesiyle geliştirilmiş bir Python betiğini kullanabilirsiniz. Tek başına Spark işi olarak veri hazırlama toplu işi gönderebilirsiniz.
Spark işi, bağımsız değişkenleri alan bir Python betiği gerektirir. Başlangıçta etkileşimli veri düzenlemesinden geliştirilen Python kodunu değiştirerek bu betiği geliştirebilirsiniz. Burada örnek bir Python betiği gösterilmiştir.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Not
Bu Python kod örneği kullanır pyspark.pandas. Yalnızca Spark çalışma zamanı sürüm 3.2 veya üzeri bunu destekler.
Bu betik, sırasıyla giriş verilerinin ve çıkış klasörünün yolunu geçen iki bağımsız değişken alır:
--titanic_data--wrangled_data
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
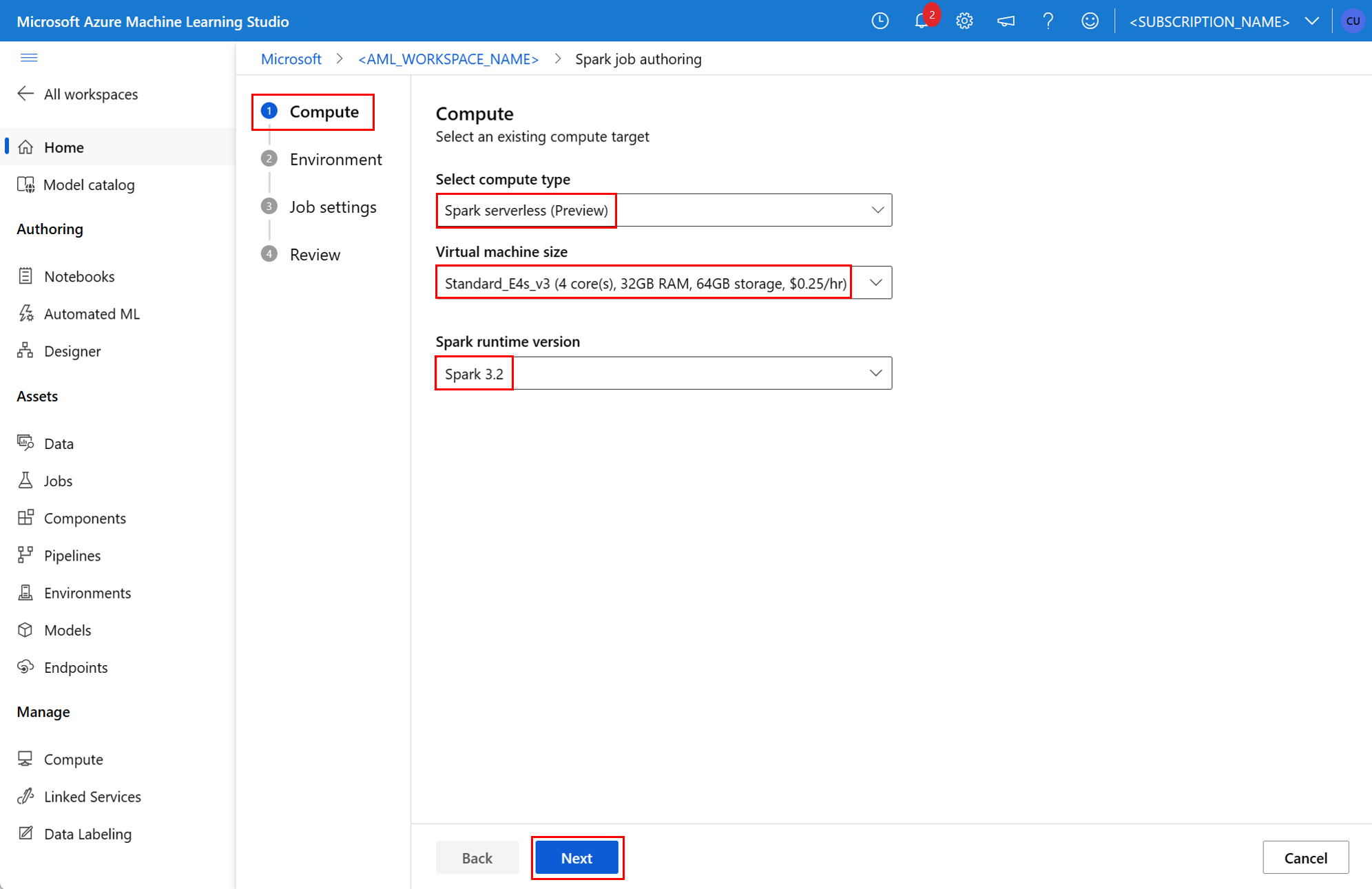
İş oluşturmak için tek başına spark işini yaml belirtim dosyası olarak tanımlayabilirsiniz. Bunu komutunda az ml job create parametresiyle --file kullanabilirsiniz. YAML dosyasında şu özellikleri tanımlayın:
Spark iş belirtimindeki YAML özellikleri
type- olaraksparkayarlayın.code- Bu iş için kaynak kodu ve betikleri içeren klasörün konumunu tanımlar.entry- işin giriş noktasını tanımlar. Bu özelliklerden birini kapsamalıdır:file- İş için giriş noktası olarak hizmet veren Python betiğinin adını tanımlar.class_name- sunucunun iş için giriş noktası olarak sunucu yaptığı sınıfın adını tanımlar.
py_files- işin başarıyla yürütülmesi için içine yerleştirilecekPYTHONPATH, veya.pydosyalarının listesini.zip.eggtanımlar. Bu özellik isteğe bağlıdır.jars- spark sürücüsüne eklenecek dosyaların listesini.jarve işin başarıyla yürütülmesi için yürütücüsüCLASSPATHtanımlar. Bu özellik isteğe bağlıdır.files- başarılı bir iş yürütme için her yürütücüsünün çalışma dizinine kopyalanması gereken dosyaların listesini tanımlar. Bu özellik isteğe bağlıdır.archives- başarılı bir iş yürütme için her yürütücüsünün çalışma dizinine ayıklanması gereken arşivlerin listesini tanımlar. Bu özellik isteğe bağlıdır.conf- bu Spark sürücüsü ve yürütücü özelliklerini tanımlar:spark.driver.cores: Spark sürücüsünün çekirdek sayısı.spark.driver.memory: Spark sürücüsü için gigabayt (GB) cinsinden ayrılmış bellek.spark.executor.cores: Spark yürütücüsünün çekirdek sayısı.spark.executor.memory: Spark yürütücüsü için gigabayt (GB) cinsinden bellek ayırma.spark.dynamicAllocation.enabled- yürütücülerin dinamik olarak veya değer olarakTrueFalseayrılması gerekip gerekmediği.- Yürütücülerin dinamik ayırması etkinleştirildiyse şu özellikleri tanımlayın:
spark.dynamicAllocation.minExecutors- dinamik ayırma için Spark yürütücüsü örneklerinin en az sayısı.spark.dynamicAllocation.maxExecutors- dinamik ayırma için Spark yürütücüsü örneği sayısı üst sınırı.
- Yürütücülerin dinamik ayırması devre dışı bırakılırsa şu özelliği tanımlayın:
spark.executor.instances- Spark yürütücü örneklerinin sayısı.
environment- işi çalıştırmak için bir Azure Machine Learning ortamı .args- iş giriş noktası Python betiğine geçirilmesi gereken komut satırı bağımsız değişkenleri. Bir örnek için burada sağlanan YAML belirtim dosyasını gözden geçirin.resources- bu özellik, Azure Machine Learning sunucusuz Spark işlem tarafından kullanılacak kaynakları tanımlar. Aşağıdaki özellikleri kullanır:instance_type- Spark havuzu için kullanılacak işlem örneği türü. Şu anda aşağıdaki örnek türleri desteklenmektedir:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- Spark çalışma zamanı sürümünü tanımlar. Şu anda aşağıdaki Spark çalışma zamanı sürümleri desteklenmektedir:3.33.4Önemli
Apache Spark için Azure Synapse Runtime: Duyurular
- Apache Spark 3.3 için Azure Synapse Runtime:
- EOLA Duyuru Tarihi: 12 Temmuz 2024
- Destek Sonu Tarihi: 31 Mart 2025. Bu tarihten sonra çalışma zamanı devre dışı bırakılır.
- Sürekli destek ve en iyi performans için Apache Spark 3.4'e geçiş önerilir.
- Apache Spark 3.3 için Azure Synapse Runtime:
Bu örnek bir YAML dosyasıdır:
resources: instance_type: standard_e8s_v3 runtime_version: "3.4"compute- bu özellik, bu örnekte gösterildiği gibi ekli bir Synapse Spark havuzunun adını tanımlar:compute: mysparkpoolinputs- bu özellik Spark işi için girişleri tanımlar. Spark işinin girişleri değişmez değer veya dosya veya klasörde depolanan veriler olabilir.- Değişmez değer bir sayı, boole değeri veya dize olabilir. Burada bazı örnekler gösterilmiştir:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Bir dosya veya klasörde depolanan veriler şu özellikler kullanılarak tanımlanmalıdır:
type- sırasıyla bir dosyada veyauri_folderklasörde bulunan giriş verileri için bu özelliğiuri_file, veya olarak ayarlayın.path- ,abfss://veyawasbs://gibiazureml://giriş verilerinin URI'sini.mode- bu özelliği olarakdirectayarlayın. Bu örnek, olarak adlandırılabilir$${inputs.titanic_data}}bir iş girişinin tanımını gösterir:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Değişmez değer bir sayı, boole değeri veya dize olabilir. Burada bazı örnekler gösterilmiştir:
outputs- bu özellik Spark işi çıkışlarını tanımlar. Spark işinin çıkışları, aşağıdaki üç özellik kullanılarak tanımlanan bir dosyaya veya klasör konumuna yazılabilir:type- Çıkış verilerini sırasıyla bir dosyaya veya klasöre yazmak için bu özelliğiuri_fileveyauri_folderolarak ayarlayabilirsiniz.path- bu özellik ,abfss://veyawasbs://gibiazureml://çıkış konumu URI'sini tanımlar.mode- bu özelliği olarakdirectayarlayın. Bu örnek, olarak başvurabileceğiniz${{outputs.wrangled_data}}bir iş çıktısının tanımını gösterir:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- bu isteğe bağlı özellik, bu işi göndermek için kullanılan kimliği tanımlar. vemanageddeğerlerine sahipuser_identityolabilir. YAML belirtimi bir kimlik tanımlamıyorsa Spark işi varsayılan kimliği kullanır.
Tek başına Spark işi
Bu örnek YAML belirtimi tek başına spark işini gösterir. Azure Machine Learning sunucusuz Spark işlem kullanır:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.4"
Not
Ekli bir Synapse Spark havuzu kullanmak için özelliğini özelliği yerine resources daha önce gösterilen örnek YAML belirtim dosyasında tanımlayıncompute.
Komutun önceki bölümlerinde az ml job create gösterilen YAML dosyalarını parametresiyle --file kullanarak gösterildiği gibi tek başına bir Spark işi oluşturabilirsiniz:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Yukarıdaki komutu şu kaynaktan yürütebilirsiniz:
- Azure Machine Learning işlem örneğinin terminali.
- Azure Machine Learning işlem örneğine bağlı bir Visual Studio Code terminali.
- Azure Machine Learning CLI yüklü yerel bilgisayarınız.
İşlem hattı işinde Spark bileşeni
Spark bileşeni, işlem hattı adımı olarak aynı bileşeni birden çok Azure Machine Learning işlem hattında kullanma esnekliği sunar.
ŞUNLAR IÇIN GEÇERLIDIR: Azure CLI ml uzantısı v2 (geçerli)
Spark bileşeninin YAML söz dizimi, Spark iş belirtiminin YAML söz dizimine benzer. Bu özellikler Spark bileşeni YAML belirtiminde farklı şekilde tanımlanır:
name- Spark bileşeninin adı.version- Spark bileşeninin sürümü.display_name- Kullanıcı arabiriminde ve başka bir yerde görüntülenecek Spark bileşeninin adı.description- Spark bileşeninin açıklaması.inputs- bu özellik Spark iş belirtimi için YAML söz diziminde açıklanan özelliğe benzerinputs, ancak özelliği tanımlamazpath. Bu kod parçacığı Spark bileşeniinputsözelliğinin bir örneğini gösterir:inputs: titanic_data: type: uri_file mode: directoutputs- bu özellik Spark iş belirtimi için YAML söz diziminde açıklanan özelliğe benzeroutputs, ancak özelliği tanımlamazpath. Bu kod parçacığı Spark bileşenioutputsözelliğinin bir örneğini gösterir:outputs: wrangled_data: type: uri_folder mode: direct
Not
Spark bileşeni, veya compute resources özelliklerini tanımlamazidentity. İşlem hattı YAML belirtim dosyası bu özellikleri tanımlar.
Bu YAML belirtim dosyası bir Spark bileşeni örneği sağlar:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Yukarıdaki YAML belirtim dosyasında tanımlanan Spark bileşenini bir Azure Machine Learning işlem hattı işinde kullanabilirsiniz. İşlem hattı işini tanımlayan YAML söz dizimi hakkında daha fazla bilgi edinmek için işlem hattı işi YAML şema kaynağını ziyaret edin. Bu örnekte Spark bileşeni ve Azure Machine Learning sunucusuz Spark işlemi içeren bir işlem hattı işi için YAML belirtim dosyası gösterilmektedir:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.4"
Not
Ekli bir Synapse Spark havuzu kullanmak için özelliği, özellik yerine resources yukarıda gösterilen örnek YAML belirtim dosyasında tanımlayıncompute.
Yukarıda komutunda az ml job create görülen YAML belirtim dosyasını parametresini --file kullanarak, gösterildiği gibi bir işlem hattı işi oluşturmak için kullanabilirsiniz:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Yukarıdaki komutu şu kaynaktan yürütebilirsiniz:
- Azure Machine Learning işlem örneğinin terminali.
- Azure Machine Learning işlem örneğine bağlı Visual Studio Code terminali.
- Azure Machine Learning CLI yüklü yerel bilgisayarınız.
Spark işlerinin sorunlarını giderme
Spark işinin sorunlarını gidermek için bu iş için oluşturulan günlüklere Azure Machine Learning stüdyosu'de erişebilirsiniz. Spark işinin günlüklerini görüntülemek için:
- Azure Machine Learning stüdyosu kullanıcı arabiriminin sol panelinden İşler'e gidin
- Tüm işler sekmesini seçin
- İş için Görünen ad değerini seçin
- İş ayrıntıları sayfasında Çıkış + günlükler sekmesini seçin
- Dosya gezgininde logs klasörünü genişletin ve ardından azureml klasörünü genişletin
- Sürücü ve kitaplık yöneticisi klasörlerinin içindeki Spark iş günlüklerine erişme
Not
Bir not defteri oturumunda etkileşimli veri düzenleme sırasında oluşturulan Spark işlerinin sorunlarını gidermek için not defteri kullanıcı arabiriminin sağ üst köşesindeki İş ayrıntıları'nı seçin. Etkileşimli bir not defteri oturumundan Spark işleri, deneme adı not defteri çalıştırmaları altında oluşturulur.