Öğretici: R kullanarak uçuş gecikmesini tahmin etme
Bu öğretici, Microsoft Fabric'te Synapse Veri Bilimi iş akışının uçtan uca bir örneğini sunar. Bir uçağın 30 dakikadan fazla geç gelip gelmeyeceğini tahmin etmek için nycflights13 verilerini ve R'yi kullanır. Ardından tahmin sonuçlarını kullanarak etkileşimli bir Power BI panosu oluşturur.
Bu öğreticide aşağıdakilerin nasıl yapılacağını öğreneceksiniz:
- Verileri işlemek ve makine öğrenmesi modelini eğitmek için tidymodels paketlerini (tarifler, ayrıştırma, rsample, iş akışları) kullanma
- Çıkış verilerini bir lakehouse'a delta tablosu olarak yazma
- Göl evindeki verilere doğrudan erişmek için Power BI görsel raporu oluşturma
Önkoşullar
Microsoft Fabric aboneliği alın. Alternatif olarak, ücretsiz bir Microsoft Fabric deneme sürümüne kaydolun.
Synapse Veri Bilimi deneyimine geçmek için giriş sayfanızın sol tarafındaki deneyim değiştiriciyi kullanın.

Not defterini açın veya oluşturun. Nasıl yapılacağını öğrenmek için bkz . Microsoft Fabric not defterlerini kullanma.
Birincil dili değiştirmek için dil seçeneğini SparkR (R) olarak ayarlayın.
Not defterinizi bir göle ekleyin. Sol tarafta Ekle'yi seçerek mevcut bir göl evi ekleyin veya bir göl evi oluşturun.
Paketleri yükleme
Bu öğreticideki kodu kullanmak için nycflights13 paketini yükleyin.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Verileri keşfetme
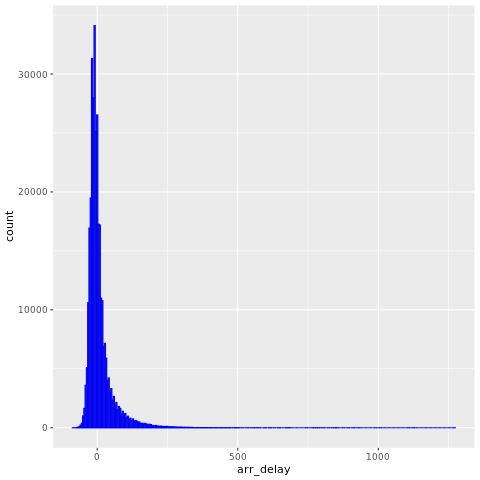
Veriler, nycflights13 2013'te New York city yakınına gelen 325.819 uçuş hakkında bilgi edinmiştir. İlk olarak, uçuş gecikmelerinin dağılımını görüntüleyin. Bu grafikte, varış gecikmelerinin dağılımının doğru eğilmiş olduğu gösterilmektedir. Yüksek değerlerde uzun bir kuyruğu vardır.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Verileri yükleyin ve değişkenlerde birkaç değişiklik yapın:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Modeli oluşturmadan önce, hem ön işleme hem de modelleme için önemli olan birkaç belirli değişkeni göz önünde bulundurun.
Değişken arr_delay bir faktör değişkenidir. Lojistik regresyon modeli eğitimi için sonuç değişkeninin bir faktör değişkeni olması önemlidir.
glimpse(flight_data)
Bu veri kümesindeki uçuşların yaklaşık %16'sı 30 dakikadan fazla geç geldi.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
Özelliğin dest 104 uçuş noktası vardır.
unique(flight_data$dest)
16 farklı taşıyıcı vardır.
unique(flight_data$carrier)
Verileri bölme
Tek veri kümesini iki kümeye bölün: eğitim kümesi ve test kümesi. Özgün veri kümesindeki satırların çoğunu (rastgele seçilen bir alt küme olarak) eğitim veri kümesinde tutun. Modeli sığdırmak için eğitim veri kümesini ve model performansını ölçmek için test veri kümesini kullanın.
rsample Verileri bölme hakkında bilgi içeren bir nesne oluşturmak için paketini kullanın. Ardından, eğitim ve test kümelerine yönelik DataFrame'ler oluşturmak için iki işlev daha rsample kullanın:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Yemek tarifi ve roller oluşturma
Basit bir lojistik regresyon modeli için bir tarif oluşturun. Modeli eğitmeden önce, yeni tahminciler oluşturmak ve modelin gerektirdiği ön işlemeyi gerçekleştirmek için bir tarif kullanın.
update_role() işlevini kullanarak tarifler ve değerlerinin değişken olduğunu flight time_hour ve adlı IDözel bir role sahip olduğunu bilmesini sağlayın. Bir rol herhangi bir karakter değerine sahip olabilir. Formül, tahmin aracı olarak eğitim kümesindeki dışındaki arr_delaytüm değişkenleri içerir. Tarif bu iki kimlik değişkenini tutar ancak bunları sonuç veya tahmin aracı olarak kullanmaz.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Geçerli değişken ve rol kümesini görüntülemek için işlevini kullanın summary() :
summary(flights_rec)
Özellik oluşturma
Modelinizi geliştirmek için bazı özellik mühendisliği yapın. Uçuş tarihi, geç varış olasılığı üzerinde makul bir etkiye sahip olabilir.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Model için önemi olabilecek tarihten türetilmiş model terimlerinin eklenmesine yardımcı olabilir. Aşağıdaki anlamlı özellikleri tek bir tarih değişkeninden türetin:
- Haftanın günü
- Month
- Tarihin bir tatil gününe karşılık olup olmadığı
Tarifinize üç adımı ekleyin:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Bir modeli tarifle sığdırma
Uçuş verilerini modellemek için lojistik regresyonu kullanın. İlk olarak, paketiyle parsnip bir model belirtimi oluşturun:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
workflows Modelinizi () tarifinizle parsnipflights_rec(lr_mod) paketlemek için paketini kullanın:
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Modeli eğitme
Bu işlev tarifi hazırlayabilir ve modeli sonuçta elde edilen tahmincilerden eğitebilir:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
yardımcı işlevlerini xtract_fit_parsnip() kullanın ve extract_recipe() iş akışından model veya tarif nesnelerini ayıklayın. Bu örnekte, uygun model nesnesini çekin ve ardından işlevi kullanarak broom::tidy() model katsayılarının düzenli bir şekilde düzeltilmiş bir kısmını elde edin:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Sonuçları tahmin et
Tek bir çağrı, predict() görünmeyen test verileriyle tahminler yapmak için eğitilen iş akışını (flights_fit) kullanır. predict() yöntemi, tarifi yeni verilere uygular ve ardından sonuçları uygun modele geçirir.
predict(flights_fit, test_data)
Tahmin edilen sınıfı döndürmek için çıkışını predict() alın: late yerine on_time. Bununla birlikte, her bir uçuş için tahmin edilen sınıf olasılıkları için test verileriyle birlikte modelle birlikte kullanarak augment() bunları birlikte kaydedin:
flights_aug <-
augment(flights_fit, test_data)
Verileri gözden geçirin:
glimpse(flights_aug)
Modeli değerlendirme
Artık tahmin edilen sınıf olasılıklarıyla bir sorun var. İlk birkaç satırda model beş zamanında uçuşu doğru tahmin etti (değerleri .pred_on_time ).p > 0.50 Ancak tahmin etmek için toplam 81.455 satır var.
Modelin geç varışları ne kadar iyi tahmin ettiğini, sonuç değişkeninizin arr_delaygerçek durumuyla karşılaştırıldığında değerini belirten bir ölçüme ihtiyacımız var.
Ölçüm olarak Eğri Alıcısı Çalışma Özelliğinin Altındaki Alanı (AUC-ROC) kullanın. Paketten ve roc_auc()ile roc_curve() hesaplayınyardstick:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Power BI raporu oluşturma
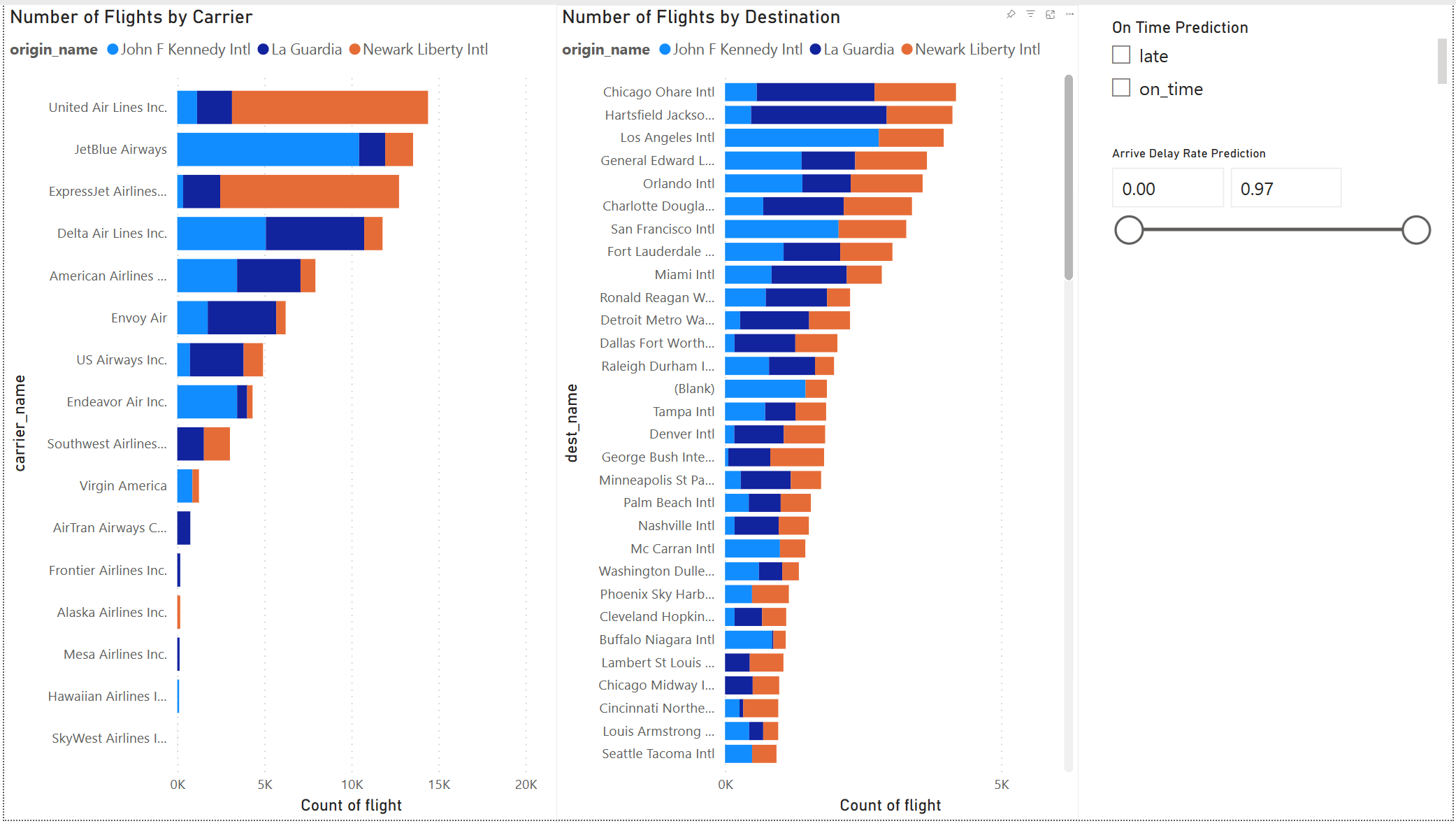
Model sonucu iyi görünüyor. Etkileşimli bir Power BI panosu oluşturmak için uçuş gecikmesi tahmin sonuçlarını kullanın. Pano, taşıyıcıya göre uçuş sayısını ve hedefe göre uçuş sayısını gösterir. Pano, gecikme tahmini sonuçlarına göre filtreleyebilir.
Tahmin sonucu veri kümesine taşıyıcı adını ve havaalanı adını ekleyin:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Verileri gözden geçirin:
glimpse(flights_clean)
Verileri Spark DataFrame'e dönüştürün:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Verileri lakehouse'unuzda bir delta tablosuna yazın:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Anlamsal model oluşturmak için delta tablosunu kullanın.
Sol tarafta OneLake veri hub'ı seçin
Not defterinize eklediğiniz göl evi seçin
Aç'ı seçin
Yeni anlamsal model'i seçin
Yeni semantik modeliniz için nycflight13'i ve ardından Onayla'yı seçin
Anlam modeliniz oluşturulur. Yeni rapor seç
Raporunuzu oluşturmak için Veri ve Görselleştirmeler bölmelerindeki alanları seçin veya rapor tuvaline sürükleyin
Bu bölümün başında gösterilen raporu oluşturmak için şu görselleştirmeleri ve verileri kullanın:
 Yığılmış çubuk grafik:
Yığılmış çubuk grafik: - Y ekseni: carrier_name
- X ekseni: uçuş. Toplama için Sayı'ya tıklayın
- Gösterge: origin_name
- Yığılmış çubuk grafik:
- Y ekseni: dest_name
- X ekseni: uçuş. Toplama için Sayı'ya tıklayın
- Gösterge: origin_name
 Dilimleyici:
Dilimleyici: - Alan: _pred_class
- Dilimleyici:
- Alan: _pred_late