Tidyverse kullanma
Tidyverse , veri bilimciler tarafından günlük veri analizlerinde yaygın olarak kullanılan bir R paketleri koleksiyonudur. Veri içeri aktarma (), veri görselleştirme (readrggplot2), veri işleme (dplyr, tidyr), işlevsel programlama (purrr) ve model oluşturma (tidymodels) gibi paketler içerir. içindeki tidyverse paketler sorunsuz bir şekilde birlikte çalışacak ve tutarlı bir tasarım ilkeleri kümesini izleyecek şekilde tasarlanmıştır.
Microsoft Fabric, en son kararlı sürümünü her çalışma zamanı sürümüyle tidyverse dağıtır. Tanıdık R paketlerinizi içeri aktarıp kullanmaya başlayın.
Önkoşullar
Microsoft Fabric aboneliği alın. Alternatif olarak, ücretsiz bir Microsoft Fabric deneme sürümüne kaydolun.
Synapse Veri Bilimi deneyimine geçmek için giriş sayfanızın sol tarafındaki deneyim değiştiriciyi kullanın.

Not defterini açın veya oluşturun. Nasıl yapılacağını öğrenmek için bkz . Microsoft Fabric not defterlerini kullanma.
Birincil dili değiştirmek için dil seçeneğini SparkR (R) olarak ayarlayın.
Not defterinizi bir göle ekleyin. Sol tarafta Ekle'yi seçerek mevcut bir göl evi ekleyin veya bir göl evi oluşturun.
Yük tidyverse
# load tidyverse
library(tidyverse)
Veri içeri aktarma
readr CSV, TSV ve sabit genişlikli dosyalar gibi dikdörtgen veri dosyalarını okumak için araçlar sağlayan bir R paketidir. readr , sırasıyla CSV ve TSV dosyalarını okumak için işlevler read_csv() sağlama ve read_tsv() gibi dikdörtgen veri dosyalarını okumak için hızlı ve kolay bir yol sağlar.
İlk olarak bir R data.frame oluşturalım, kullanarak readr::write_csv() lakehouse'a yazalım ve ile readr::read_csv()yeniden okuyalım.
Not
kullanarak readrLakehouse dosyalarına erişmek için Dosya API'sinin yolunu kullanmanız gerekir. Lakehouse gezgininde, erişmek istediğiniz dosyaya veya klasöre sağ tıklayın ve bağlam menüsünden Dosya API'sinin yolunu kopyalayın.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Ardından, Dosya API'sinin yolunu kullanarak verileri lakehouse'a yazalım.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Lakehouse'dan verileri okuyun.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Veri düzenleme
tidyr karmaşık verilerle çalışmaya yönelik araçlar sağlayan bir R paketidir. içindeki tidyr ana işlevler, verileri düzenli bir biçimde yeniden şekillendirmenize yardımcı olmak için tasarlanmıştır. Düzenli veriler, her değişkenin bir sütun olduğu ve her gözlemin bir satır olduğu belirli bir yapıya sahiptir ve bu da R ve diğer araçlardaki verilerle çalışmayı kolaylaştırır.
Örneğin, gather() içindeki tidyr işlevi geniş verileri uzun verilere dönüştürmek için kullanılabilir. Bir örnek aşağıda verilmiştir:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
İşlevsel programlama
purrr , işlevler ve vektörlerle çalışmak için eksiksiz ve tutarlı bir araç kümesi sağlayarak R'nin işlevsel programlama araç setini geliştiren bir R paketidir. Başlamak purrr için en iyi yer, birçok for döngüsünü hem daha kısa hem de daha kolay okunan bir kodla değiştirmenize olanak sağlayan işlev ailesidir map() . Aşağıda, bir listenin her öğesine işlev uygulamak için kullanma map() örneği verilmiştir:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Verileri işleme
dplyr adlara göre değişkenleri seçme, değerlere göre servis taleplerini seçme, birden çok değeri tek bir özete düşürme ve satırların sırasını değiştirme gibi en yaygın veri işleme sorunlarını çözmenize yardımcı olan tutarlı bir fiil kümesi sağlayan bir R paketidir. Aşağıda bazı örnekler verilmiştir:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Veri görselleştirme
ggplot2 , Grafiklerin Dil Bilgisi temelinde bildirim temelli olarak grafik oluşturmaya yönelik bir R paketidir. Verileri sağlarsınız, değişkenleri estetikle eşlemeyi, hangi grafik temel öğelerini kullanacağınızı söylersiniz ggplot2 ve ayrıntılarla ilgilenir. Burada bazı örnekler verilmiştir:
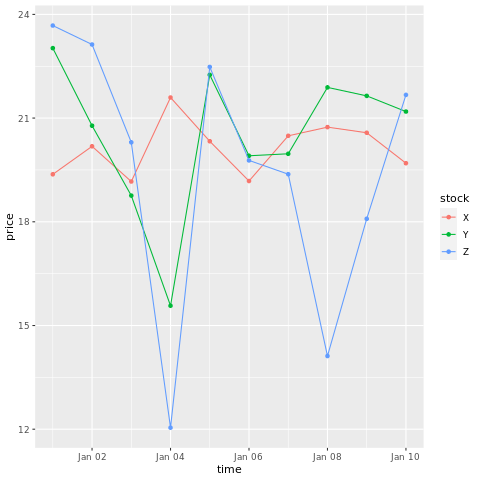
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
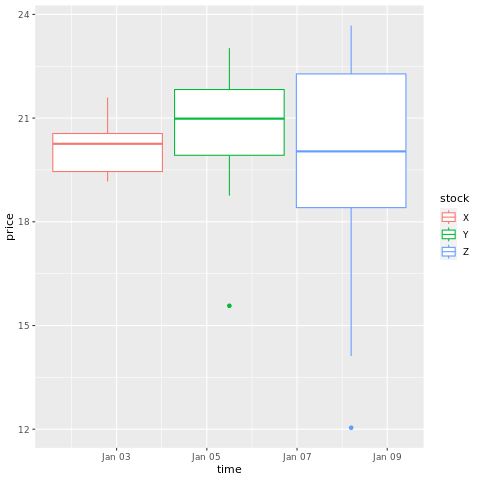
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Model oluşturma
Çerçeve tidymodels , ilkeleri kullanarak tidyverse modellemeye ve makine öğrenmesine yönelik bir paket koleksiyonudur. Eğitme/test veri kümesi örneği bölme, model belirtimirecipes, veri ön işleme, iş akışları tune modelleme, parsnip hiper parametre ayarlama, workflows model değerlendirmesibroom, yardstick model çıkışlarını iletme ve dials ayarlama parametrelerini yönetme gibi rsample çok çeşitli model oluşturma görevleri için çekirdek paketlerin listesini kapsar. Tidymodels web sitesini ziyaret ederek paketler hakkında daha fazla bilgi edinebilirsiniz. Aşağıda, ağırlığına (wt) göre bir arabanın galon (mpg) başına mil sayısını tahmin etmek için doğrusal regresyon modeli oluşturma örneği verilmiştir:
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
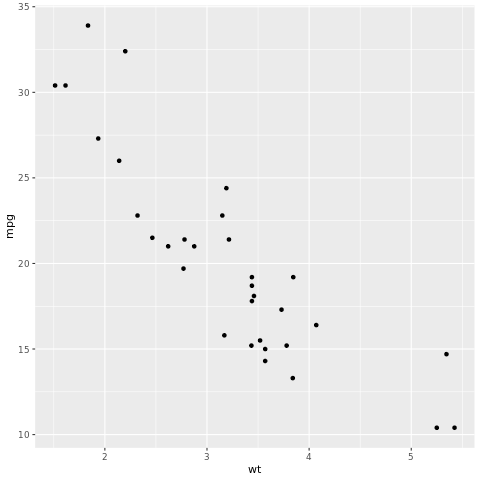
Dağılım grafiğinden ilişki yaklaşık olarak doğrusal görünür ve varyans sabit görünür. Şimdi doğrusal regresyon kullanarak bunu modellemeyi deneyelim.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Test veri kümesinde tahmin yapmak için doğrusal regresyon modelini uygulayın.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
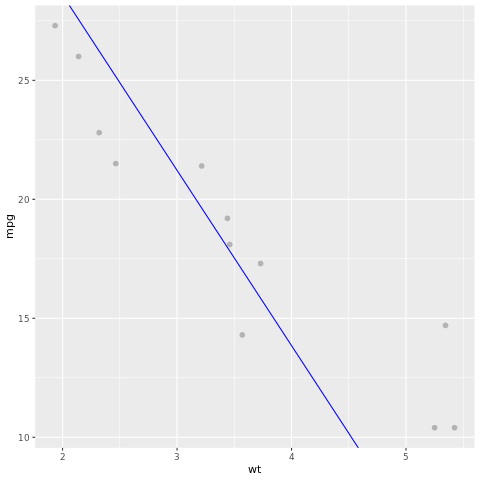
Şimdi model sonucuna göz atalım. Modeli çizgi grafik olarak, test noktası gerçeği verilerini de aynı grafikte puan olarak çizebiliriz. Model iyi görünüyor.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")