多租用戶解決方案中 AI 和 ML 的結構方法
越來越多的多租用戶解決方案是以人工智慧(AI)和機器學習(ML)為基礎建置的。 多租用戶的 AI/ML 解決方案可提供相似的機器學習(ML)型功能給任意數量的租用戶。 租用戶通常無法看到或共用其他租用戶的資料,但在某些情況下,租用戶可能會使用與其他租用戶相同的模型。
多租用戶 AI/ML 結構需要考慮資料和模型的需求,以及訓練模型和進行模型推斷所需的計算資源。 考慮多租用戶 AI/ML 模型如何部署、分佈和協調非常重要,並且要確保您的解決方案準確、可靠且可調整。
隨著生成式 AI 技術的興起,不論是大型還是小型語言模型,建立有效的營運做法和策略來管理這些模型於生產環境中變得至關重要。這可以透過採用機器學習作業(MLOps)和 GenAIOps(亦稱為 LLMOps)來實現。
重要考量與需求
在處理 AI 和 ML 時,務必分別考慮訓練和推斷的需求。 訓練的目的是以一組資料為基礎建置預測模型。 當您在應用程式中使用模型進行預測時,就會進行推斷。 這些程序各自有不同的需求。 在多租用戶解決方案中,您應該考慮您的租用戶模型會對各個程序造成什麼影響。 透過考慮這些需求,您可以確保您的解決方案能提供準確的結果、在高負載下表現良好、具成本效益,並且能夠支援未來的成長規模。
租用戶隔離
確保租用戶不會獲得未經授權或不必要的存取權,進而接觸到其他租用戶的資料或模型。 對模型的敏感度應與訓練它們的原始資料相當。 確保您的租用戶了解他們的資料如何用於訓練模型,以及使用其他租用戶資料訓練的模型可能如何用於推斷他們的工作負載。
在多租用戶解決方案中,處理 ML 模型有三種常見的方法:租用戶專屬模型、共用模型和調整過的共用模型。
租用戶專屬模型
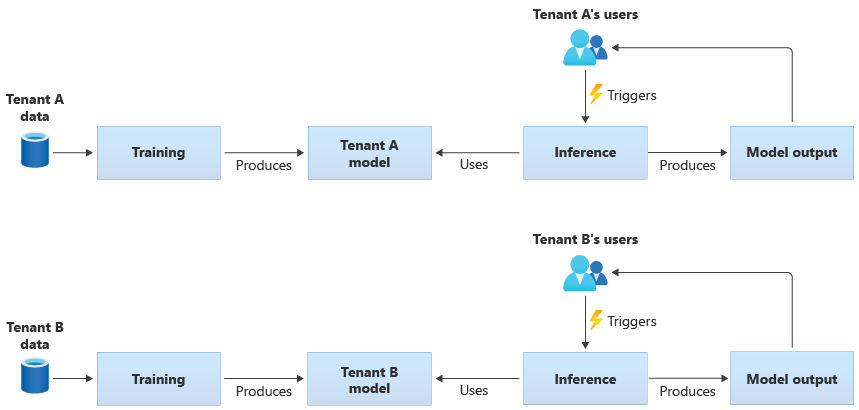
租用戶專屬模型只會使用單一租用戶資料進行訓練,然後只會套用於該租用戶。 租用戶專屬模型適用於以下情況:當租用戶的資料很敏感,或從一個租用戶提供的資料中學到的知識,不那麼適合套用到其他租用戶時。 下圖說明如何為兩個租用戶建置一個使用租用戶專屬模型的解決方案:
共用模型
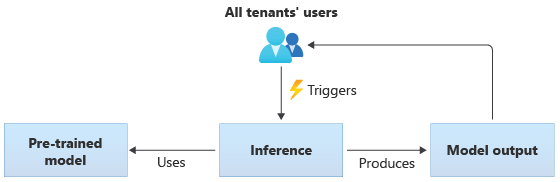
在使用共用模型的解決方案中,所有租用戶都根據相同的共用模型進行推斷。 共用模型可能是您從社群來源獲得的預先訓練模型。 下圖說明如何讓所有租用戶使用單一的預先訓練模型進行推斷:
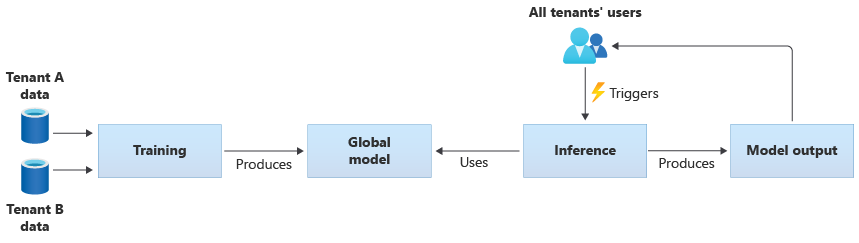
您也可以透過使用所有租用戶提供的資料來訓練自己的共用模型。 下圖說明單一的共用模型,該模型是根據所有租用戶的資料進行訓練的:
重要
如果您根據租用戶的資料訓練共用模型,請確保您的租用戶了解並同意其資料的使用方式。 確保從租用戶的資料中移除身分識別資訊。
考慮如果某個租用戶反對將其資料用來訓練模型,且該模型將套用到其他租用戶時,應採取什麼措施。 例如,您是否能夠將特定租用戶的資料排除在訓練資料集之外?
調整過的共用模型
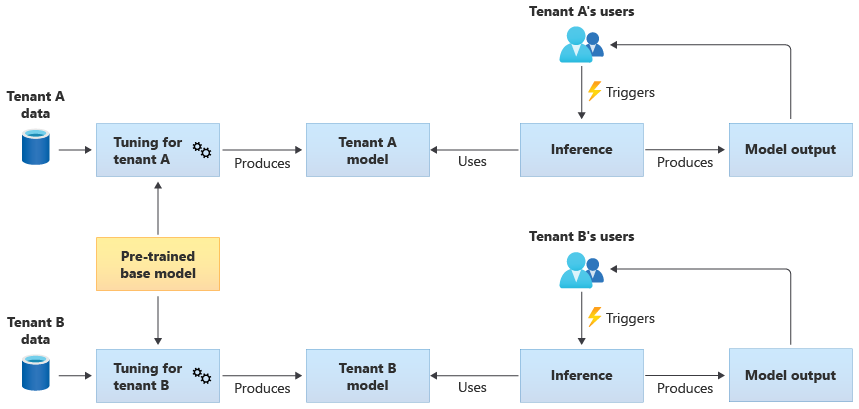
您也可以選擇獲取一個預先訓練的基礎模型,然後進一步微調模型,以使其能夠根據每個租用戶的資料適合他們使用。 下圖將說明這個方法:
延展性
考慮您的解決方案成長對 AI 和 ML 元件的使用方式會產生什麼影響。 成長可以指租用戶數量增加、每個租用戶儲存的資料量增加、使用者數量增加,以及對您解決方案請求量的增加。
訓練:有幾個因素會影響訓練模型所需的資源。 這些因素包括您需要訓練的模型數量、用於訓練模型的資料量,以及訓練或重新訓練模型的頻率。 如果您建立租用戶專屬模型,隨著租用戶數量的增加,所需的計算資源和儲存空間也可能會增長。 如果您建立共用模型並根據所有租用戶的資料進行訓練,那麼所需的訓練資源不太可能會與租用戶數量的增長同速擴展。 然而,訓練資料總量的增加會影響資源的消耗,無論是對共用模型還是租用戶專屬模型的訓練。
推斷:進行推斷所需的資源通常與存取模型進行推斷的請求數量成正比。 隨著租用戶數量的增加,請求數量也很可能會增加。
一個不錯的通用做法是使用能夠適當擴大規模的 Azure 服務。 由於 AI/ML 工作負載傾向於使用容器,因此 AI/ML 工作負載常會選擇使用 Azure Kubernetes Service (AKS) 和 Azure Container Instances (ACI)。 通常 AKS 會是一個不錯的選擇,可以實現高擴展性,並根據需求動態擴展計算資源。 對於小型工作負載,ACI 會是一個設定簡單的計算平台,儘管它的擴展性不如 AKS。
效能
考慮您解決方案中 AI/ML 元件的效能需求,包括訓練和推斷階段。 確認每個程序的延遲和效能需求十分重要,如此您可以根據需要進行衡量和改進。
訓練:訓練通常會以批次處理方式執行,這代表它可能不像工作負載的其他部分那樣對效能敏感。 然而,您需要確保提供足夠的資源來有效率地進行模型訓練,包括在擴展時也是如此。
推斷:推斷是一個對延遲敏感的程序,通常需要快速甚至即時的回應。 即使您不需要即時進行推斷,也要確保監控解決方案的效能,並使用適當的服務來最佳化您的工作負載。
考慮使用 Azure 的高效能計算能力來處理您的 AI 和 ML 工作負載。 Azure 提供多種不同類型的虛擬機器和其他硬體執行個體。 思考您的解決方案是否可以從使用 CPU、GPU、FPGA 或其他硬體加速環境中受益。 Azure 也提供使用 NVIDIA GPU 進行即時推斷的功能,包括 NVIDIA Triton Inference Servers。 對於優先順序低的計算需求,考慮使用 AKS 現成節點集區。 若要進一步了解如何在多租用戶解決方案中最佳化計算服務,請參閱多租用戶解決方案中的結構方法。
模型訓練通常需要與資料存放區進行大量互動,因此思考您的資料策略以及資料層提供的效能也很重要。 若想進一步了解多租用戶和資料服務,請參閱多租用戶解決方案中儲存與資料的結構方法。
考慮對您的解決方案效能進行分析。 例如,Azure Machine Learning 提供了分析功能,您可以在開發和測試解決方案時使用這些功能。
實作複雜度
在建置使用 AI 和 ML 的解決方案時,您可以選擇使用預建元件,也可以自行建置自訂元件。 您需要做出兩個重要決策。 第一個是您要用於 AI 和 ML 的平台或服務。 第二個是您是否使用預先訓練模型,還是建置自己的自訂模型。
平台:有許多 Azure 服務可以用於您的 AI 和 ML 工作負載。 例如,Azure AI 服務和 Azure OpenAI 服務會提供 API 來對預建模型進行推斷,而 Microsoft 負責管理底層資源。 Azure AI 服務可讓您快速部署新解決方案,但它對訓練和推斷的控制較少,且可能不適合所有類型的工作負載。 相對而言,Azure Machine Learning 是一個平台,可讓您建置、訓練和使用自己的 ML 模型。 Azure Machine Learning 具有控制性和靈活性,但也增加了設計和實施的複雜性。 查看 Microsoft 的機器學習產品和技術,以便在選擇方法時做出明智的決策。
模型:即使您不想使用像 Azure AI 服務提供的完整模型,您仍然可以透過使用預先訓練模型來加速您的開發過程。 如果預先訓練模型不完全符合您的需求,可以考慮透過套用名為轉移學習或微調的技術來擴展預先訓練模型。 轉移學習可讓您擴展現有模型,並將其套用到不同領域。 例如,如果您要建置一個多租用戶的音樂建議服務,可以考慮根據預先訓練的音樂建議模型進行擴展,並使用轉移學習來訓練模型以符合特定使用者的音樂偏好。
使用預建 ML 平台 (如 Azure AI 服務或 Azure OpenAI 服務),或使用預先訓練模型,您可以大幅降低初期的研究和開發成本。 使用預建平台可以節省數月的研究時間,並避免需要聘請高水準的資料科學家來訓練、設計和最佳化模型。
成本最佳化
通常,AI 和 ML 工作負載的成本大部分來自於進行模型訓練和推斷所需的計算資源。 查看「多租用戶解決方案中的計算架構方法」,了解如何根據您的需求最佳化計算工作負載的成本。
在規劃您的 AI 和 ML 成本時,請思考以下需求:
- 確定訓練所需的計算 SKU。 例如,參閱如何使用 Azure Machine Learning 進行這項工作的指導。
- 確定推斷所需的計算 SKU。 有關估算推斷成本的範例,請參閱 Azure Machine Learning 指南。
- 監控您的使用情況。 透過觀察計算資源的使用情況,您可以確定是否應該部署不同的 SKU 來減少或增加資源容量,或者隨著需求的變化來擴展計算資源。 請參閱 Azure Machine Learning 監控工具。
- 最佳化您的計算叢集環境。 當您使用計算叢集時,請監控叢集使用情況或設定自動規模化以縮減計算節點。
- 共用您的計算資源。 考慮是否可以透過在多個租用戶之間共用計算資源來最佳化成本。
- 考慮您的預算。 了解您是否有固定預算,並相應地監控您的消耗情況。 您可以設定預算以防止超支,並根據租用戶的優先順序分配配額。
要考慮的方法和模式
Azure 提供了一套服務來支援 AI 和 ML 工作負載。 在多租用戶解決方案中,常見的架構方法有幾種:使用預建的 AI/ML 解決方案、利用 Azure Machine Learning 建置自訂的 AI/ML 結構,以及使用其中一個 Azure 分析平台。
使用預建的 AI/ML 服務
在可行的情況下,嘗試使用預建的 AI/ML 服務會是一個好做法。 例如,您的組織可能剛開始探索 AI/ML,並希望迅速整合有用的服務。 或者,您可能有一些基本需求,而這些需求不需要訓練和開發自訂 ML 模型。 預建的 ML 服務可讓您在不需要建置和訓練自己的模型的情況下進行推斷。
Azure 提供了多種服務,涵蓋不同領域的 AI 和 ML 技術,包括語言理解、語音辨識、知識處理、文件和表單辨識,以及電腦視覺。 Azure 的預建 AI/ML 服務包括 Azure AI 服務、Azure OpenAI 服務、Azure AI 搜尋服務,和 Azure AI 文件智慧服務。 每項服務都提供了簡單的整合介面,以及一系列預先訓練和經過測試的模型。 它們作為受控服務,提供服務層級的協議,且需要的設定或持續管理較少。 您不需要開發或測試自己的模型即可使用這些服務。
許多受控 ML 服務不需要模型訓練或資料,因此通常不會存在租用戶資料隔離問題。 但當您在多租用戶解決方案中使用「AI 搜尋服務」時,請參閱「多租用戶 SaaS 應用程式和 Azure AI 搜尋服務的設計模式」。
考慮您解決方案中元件的擴展需求。 例如,許多 Azure AI 服務中的 API 都支援每秒最大請求數量。 如果您部署單一的「AI 服務」資源以供多個租用戶共用,則隨著租用戶數量的增加,您可能需要擴展到多個資源。
注意
一些受控服務可讓您使用自己的資料進行訓練,包括自訂視覺服務、Face API、文件智慧服務自訂模型,以及一些支援自訂和微調的 OpenAI 模型。 在使用這些服務時,請務必考慮租用戶資料的隔離需求。
自訂 AI/ML 結構
如果您的解決方案需要自訂模型,或您在受控 ML 服務未涵蓋的領域工作,那麼請考慮建置自己的 AI/ML 結構。 Azure Machine Learning 提供了一套功能來協調 ML 模型的訓練和部署。 Azure Machine Learning 支援許多開放原始碼的機器學習庫,包括 PyTorch、Tensorflow、Scikit 和 Keras。 您可以持續監控模型的效能指標,偵測資料漂移,和觸發重新訓練以提升模型效能。 在 ML 模型的整個生命週期中,Azure Machine Learning 提供內建的追蹤和溯源功能,以對所有 ML 成果實現審計和治理。
在多租用戶解決方案中,考慮租用戶在訓練和推斷階段的隔離需求非常重要。 您還需要確定模型訓練和部署過程。 Azure Machine Learning 提供了訓練模型的管道,並可將其部署到環境中以供推斷使用。 在多租用戶環境中,考慮模型是否應部署到共用計算資源,或者每個租用戶是否應擁有專用資源。 根據您的隔離模型和租用戶部署程序,設計模型部署管道。
當您使用開放原始碼的模型時,可能需要透過轉移學習或微調來重新訓練這些模型。 考慮如何管理每個租用戶的不同模型和訓練資料,以及模型版本。
以圖展示了使用 Azure Machine Learning 架構的範例。 該範例使用了租用戶專用模型的隔離方法。
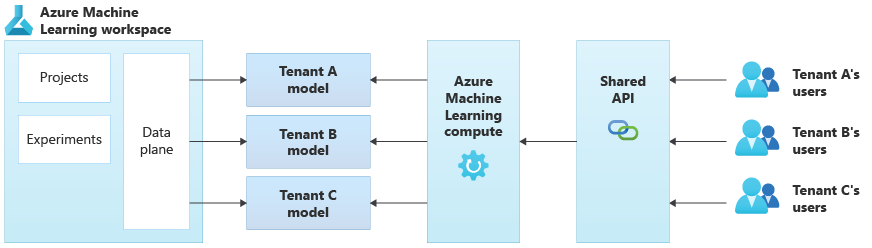
整合式 AI/ML 解決方案
Azure 提供了幾個強大的分析平台,可以用於多種用途。 這些平台包括 Azure Synapse Analytics、Databricks 和 Apache Spark。
當您需要將 ML 功能延伸到非常多的租用戶,並且需要大規模的計算和協調時,可以考慮將這些平台用於 AI/ML。 當您需要適用於解決方案其他部分的廣泛分析平臺時,您也可以考慮將這些平台用於 AI/ML,例如數據分析,並透過 Microsoft power BI 與報告整合。 您可以部署一個涵蓋所有分析和 AI/ML 需求的單一平台。 在多租用戶解決方案中實施資料平台時,請參閱多租用戶解決方案中的儲存和資料結構方法。
ML 作業模型
在採用 AI 和機器學習,包括生成式 AI 做法時,最好持續改進和評估您的組織在管理這些技術的能力。 引入 MLOps 和 GenAIOps 可客觀地提供一個架構,以持續擴展您組織中的 AI 和 ML 做法。 請參閱「MLOps 成熟度模型」和「LLMOps 成熟度模型」文件以取得進一步指引。
應避免的反模式
- 未考慮隔離需求。 請務必仔細思考如何在訓練和推斷階段,隔離租用戶的資料和模型。 未能做到這一點可能會違反法律或合約要求。 如果資料差異很大,讓模型使用多個租用戶的資料進行訓練也可能會降低模型的準確性。
- 相鄰干擾。 思考您的訓練或推斷過程是否可能受到「相鄰干擾」問題的影響。 例如,如果您有幾個大型租用戶和一個小型租用戶,請確保大型租用戶的模型訓練不會無意中佔用所有計算資源,從而使小型租用戶的資源不足。 使用資源治理和監控來降低其他租用戶活動對某個租用戶計算工作負載的影響風險。
參與者
本文由 Microsoft 維護。 原始投稿人如下。
主要作者:
- Kevin Ashley | Senior Customer Engineer、FastTrack for Azure
其他投稿人:
- Paul Burpo | 主任客戶工程師,FastTrack for Azure
- John Downs | 主任軟體工程師
- Daniel Scott-Raynsford | 合作夥伴技術策略師
- Arsen Vladimirskiy | 主任客戶工程師,FastTrack for Azure
- Vic Perdana | ISV 夥伴解決方案架構師
下一步
- 請參閱「多租用戶解決方案中的計算結構」方法。
- 若要深入了解如何設計 Azure Machine Learning 管線以支援多租用戶,請參閱「多租用戶方式的 ML 管線解決方案」。