觸發機器學習管線
適用於:  Python SDK azureml v1 (部分機器翻譯)
Python SDK azureml v1 (部分機器翻譯)
在本文中,您將瞭解如何以程式設計方式排程要在 Azure 上執行的管線。 您可根據已耗用時間或檔案系統變更來建立排程。 以時間為基礎的排程可用來處理例行的工作,例如監視資料漂移。 以變更為基礎的排程可用來回應異常或無法預測的變更,例如上傳的新資料或正在編輯的舊資料。 瞭解如何建立排程之後,您將瞭解如何擷取和停用排程。 最後,您將瞭解如何使用其他 Azure 服務、Azure 邏輯應用程式和 Azure Data Factory 來執行管線。 Azure 邏輯應用程式可讓您執行更複雜的觸發邏輯或行為。 Azure Data Factory 管線可讓您呼叫機器學習管線,以做為大型資料協調流程管線的一部分。
必要條件
Azure 訂用帳戶。 如果您沒有 Azure 訂用帳戶,請建立免費帳戶。
已安裝適用於 Python 的 Azure Machine Learning SDK 的 Python 環境。 如需詳細資訊,請參閱使用 Azure Machine Learning 建立和管理可重複使用的環境,以進行定型和部署。
具有已發佈管線的機器學習工作區。 您可使用在使用 Azure Machine Learning SDK 建立和執行機器學習管線中所建置的管線。
使用適用於 Python 的 Azure Machine Learning SDK 來觸發管線
如要排程管線,您需要工作區的參考、已發佈管線的識別碼,以及您想要在其中建立排程的實驗名稱。 您可使用下列程式碼來取得這些值:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
建立排程
如要定期執行管線,您需建立排程。 Schedule 會關聯管線、實驗和觸發程序。 觸發程序可以是描述各工作等候時間的 ScheduleRecurrence,或是指定監看變更所在目錄的資料存放區路徑。 無論是何種情況,您都需要管線識別碼,以及要在其中建立排程的實驗名稱。
在您的 Python 檔案頂端,匯入 Schedule 和 ScheduleRecurrence 類別:
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
建立以時間為基礎的排程
此 ScheduleRecurrence 建構函式的必要 frequency 引數必須為下列其中一個字串:「Minute」、「Hour」、「Day」、「Week」或「Month」。 此外亦需要整數 interval 引數,以指定排程開始之間所應經過的 frequency 單位數。 選擇性引數可讓您更明確地瞭解開始時間,如 ScheduleRecurrence SDK 文件中所述。
建立 Schedule,每隔 15 分鐘開始工作一次:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
建立以變更為基礎的排程
檔案變更所觸發的管線,可能比以時間為基礎的排程更有效率。 當您想要在檔案變更之前執行某個動作,或將新檔案新增至資料目錄時,可前置處理該檔案。 您可以監視資料存放區的任何變更,或資料存放區中特定目錄內的變更。 若您監視特定目錄,該目錄內的子目錄變更「不會」觸發工作。
注意
變更型排程僅支援監視 Azure Blob 儲存體。
如要建立檔案回應 Schedule,您必須在 Schedule.create 呼叫中設定 datastore 參數。 如要監視資料夾,請設定 path_on_datastore 引數。
polling_interval 引數可讓您指定資料存放區變更的檢查頻率 (以分鐘為單位)。
若管線是使用 DataPath PipelineParameter 所建構,您可藉由設定 data_path_parameter_name 引數,將該變數設定為已變更檔案的名稱。
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
建立排程時的選擇性引數
除了先前討論的引數之外,您還可將 status 引數設為 "Disabled",以建立非使用中的排程。 最後,continue_on_step_failure 可讓您傳遞將要覆寫管線預設失敗行為的布林值。
檢視已排程管線
在網頁瀏覽器中,瀏覽至 Azure Machine Learning。 在瀏覽面板的 [端點] 區段中,選擇 [管線端點]。 這會帶您前往工作區中發佈的管線清單。
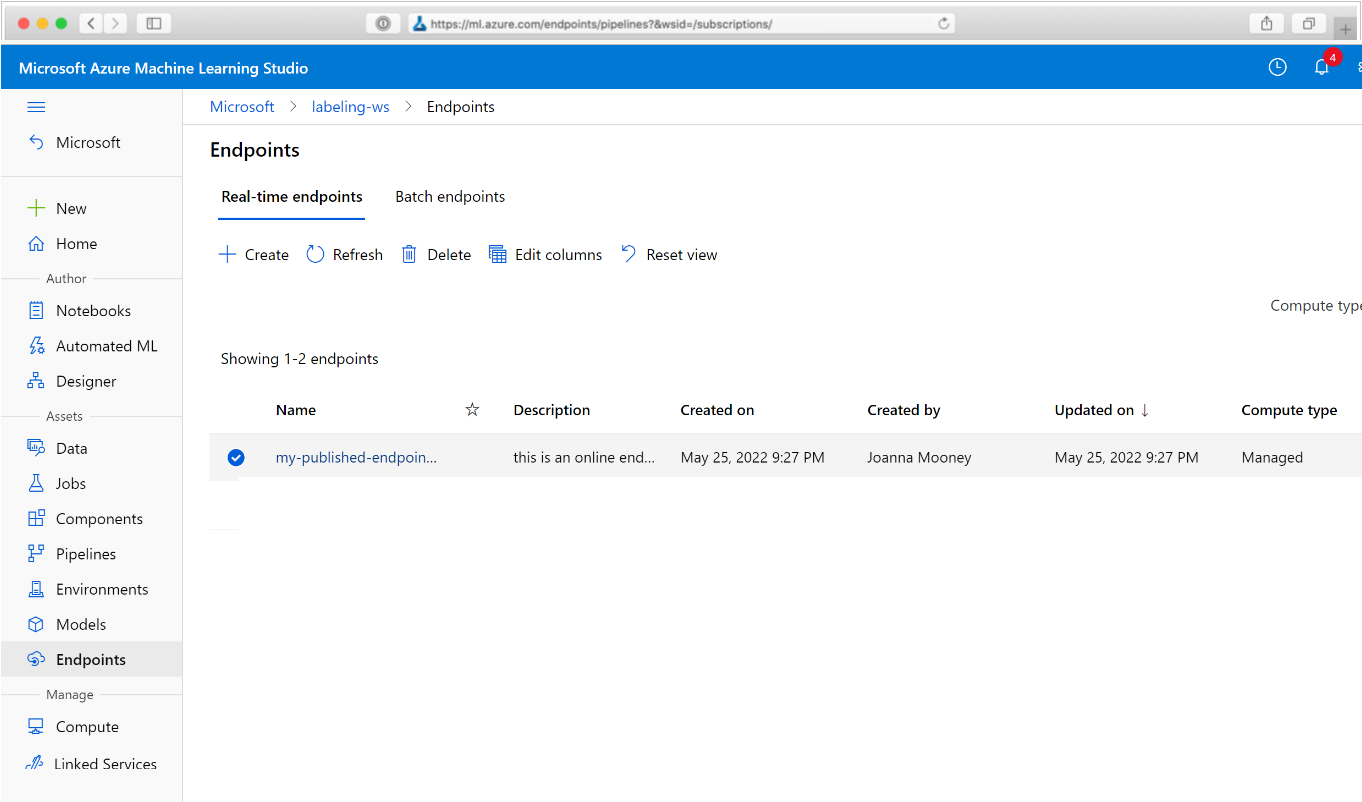
您可在此頁面查看工作區中所有管線的摘要資訊:名稱、描述、狀態等等。 在管線中按一下以向下鑽研。 產生的頁面上會提供關於管線的其他詳細資訊,您可向下鑽研至個別的工作。
停用管線
若您有已發佈但未排程的 Pipeline,則可使用下列程式來將其停用:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
若已排程管線,則您必須先取消排程。 從入口網站或藉由執行下列程式,擷取排程的識別碼:
ss = Schedule.list(ws)
for s in ss:
print(s)
在您取得想停用的 schedule_id 後,請執行:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
若您稍後再次執行 Schedule.list(ws),則應會取得空白的清單。
針對複雜觸發程序使用 Azure Logic Apps
您可以使用 Azure 邏輯應用程式,建立更複雜的觸發程序規則或行為。
如要使用 Azure 邏輯應用程式來觸發機器學習管線,您將需要已發佈機器學習管線的 REST 端點。 建立並發佈您的管線. 接著使用管線識別碼,找出 PublishedPipeline 的 REST 端點:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
在 Azure 中建立邏輯應用程式
現在請建立 Azure 邏輯應用程式執行個體。 佈建邏輯應用程式之後,請使用以下步驟來設定管線的觸發程序:
建立系統指派的受控識別,以授與應用程式您的 Azure Machine Learning 工作區存取權。
瀏覽至 [邏輯應用程式設計檢視],然後選取 [空白邏輯應用程式] 範本。
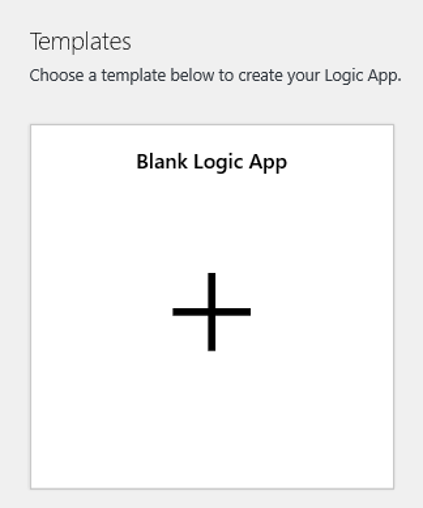
在設計工具中,搜尋 [blob]。 選取 [新增或修改 blob 時 (僅屬性)] 觸發程序,並將此觸發程序新增至邏輯應用程式。
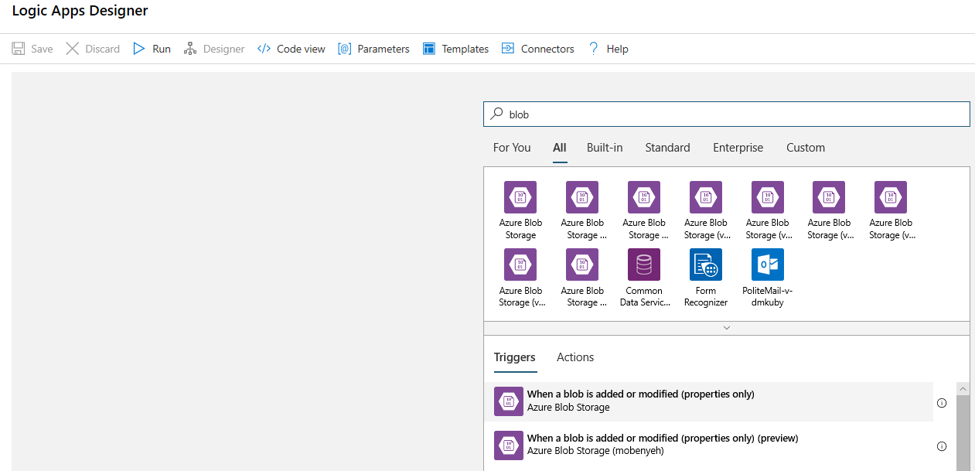
填入您想要監視的 Blob 儲存體帳戶連線資訊,以執行 blob 新增或修改作業。 選取要監視的容器。
選擇要輪詢適用更新的 [間隔] 與 [頻率]。
注意
此觸發程序會監視選取的容器,但不會監視子資料夾。
新增在偵測到新的或已修改的 blob 時所要執行的 HTTP 動作。 選取 [+ 新增步驟],然後搜尋並選取 [HTTP] 動作。
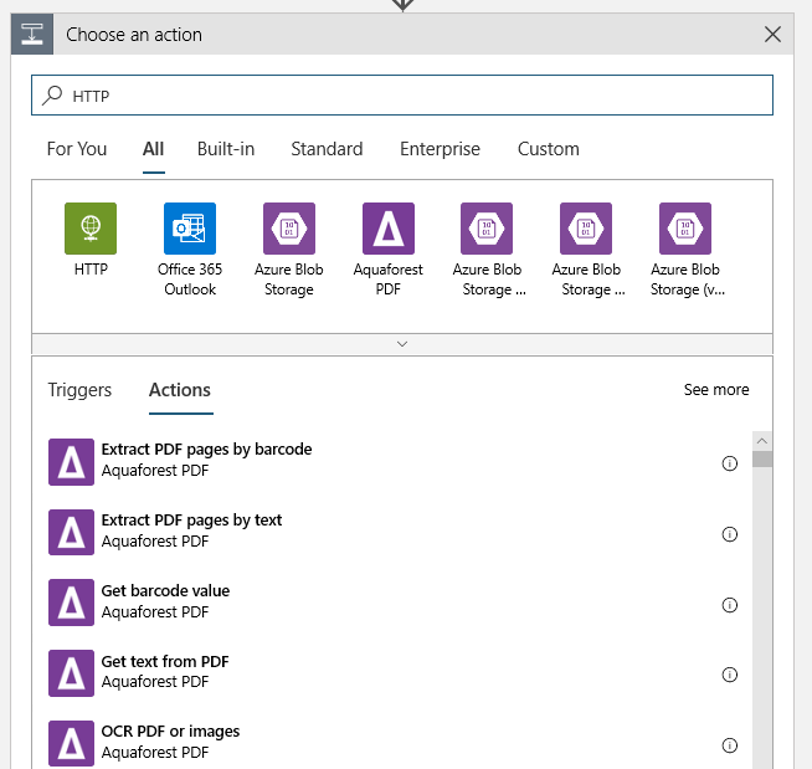
使用下列設定以設定您的動作:
| 設定 | 值 |
|---|---|
| HTTP 動作 | POST |
| URI | 在必要條件中所提及的已發佈管線端點 |
| 驗證模式 | 受控識別 |
設定您的排程,以設定您可能擁有的任何 DataPath PipelineParameters 值:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }使用您依照必要條件所新增至工作區的
DataStoreName。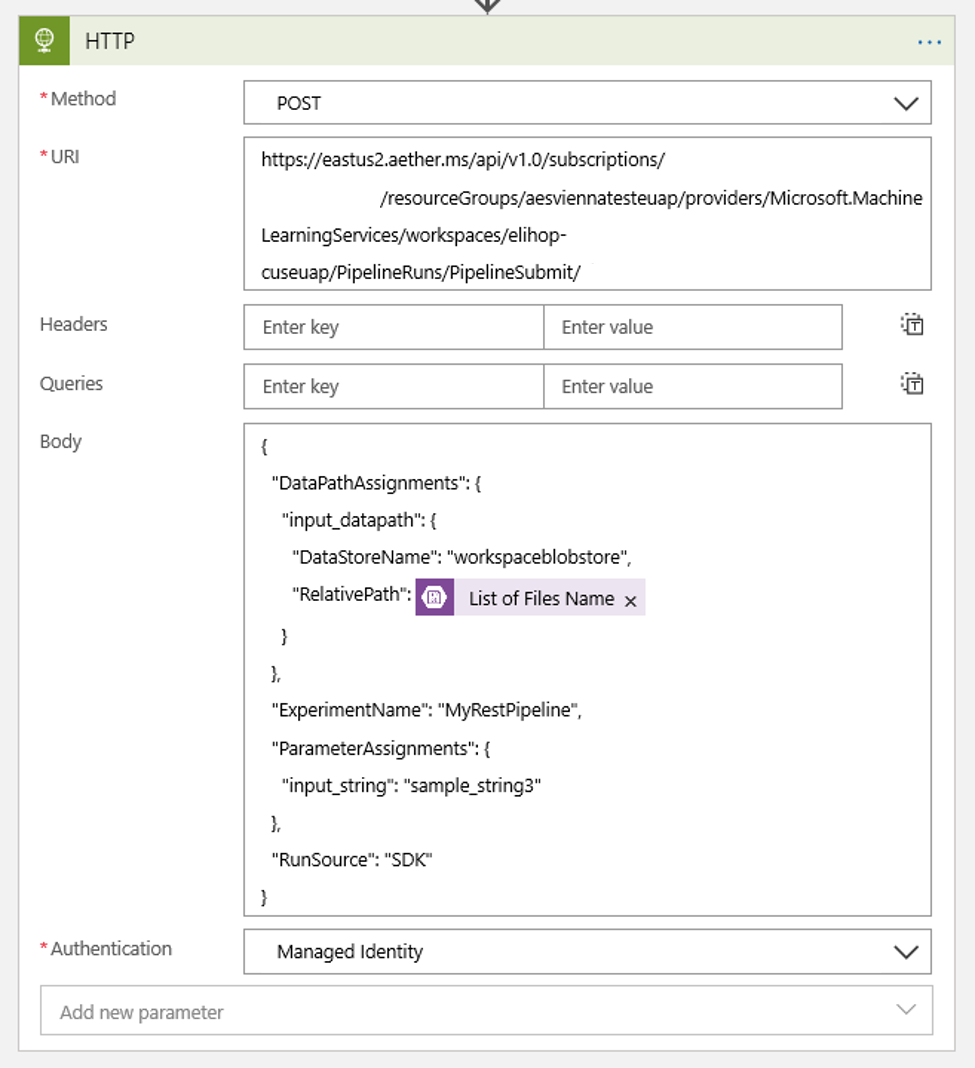
選取 [儲存],您的排程現已就緒。
重要
若您使用 Azure 角色型存取控制 (Azure RBAC) 來管理管線的存取權,請為管線案例設定權限 (訓練或評分)。
從 Azure Data Factory 管線呼叫機器學習管線
在 Azure Data Factory 管線中,「機器學習執行管線」活動會執行 Azure Machine Learning 管線。 您可以在「機器學習」類別下的 Data Factory 製作頁面找到此活動:
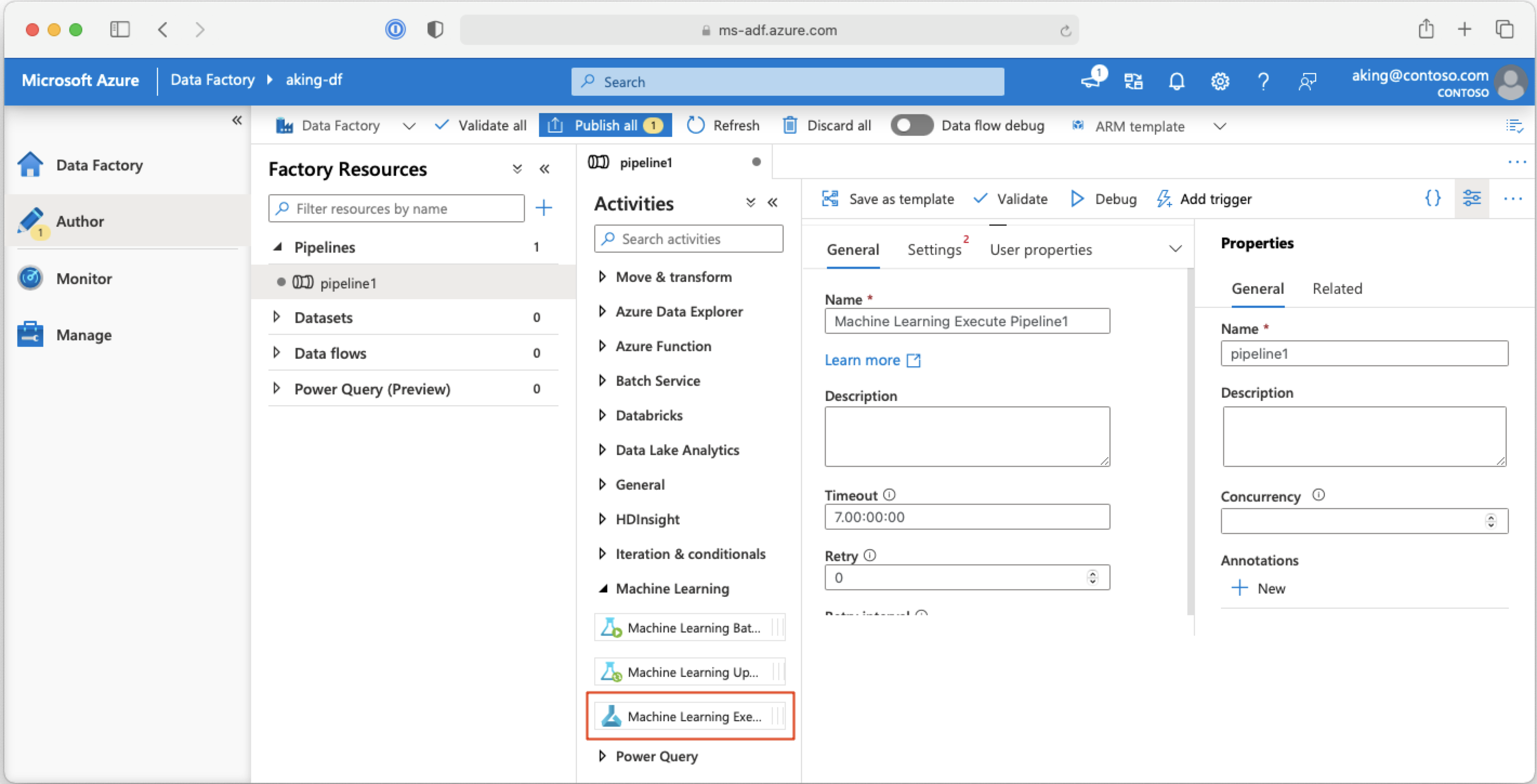
下一步
在本文中,您已使用適用於 Python 的 Azure Machine Learning SDK,運用兩種不同的方式來排程管線。 系統會根據經過的時鐘時間重複一次排程。 若在指定的 Datastore 或該存放區的目錄中修改檔案,則會執行另一個排程工作。 您已了解如何使用入口網站來檢查管線和個別工作。 您已瞭解如何停用排程,以讓管線停止執行。 最後,您已建立 Azure 邏輯應用程式來觸發管線。
如需詳細資訊,請參閱