教學課程:使用推送 API 優化編製索引
Azure AI 搜尋支援將數據匯入搜尋索引的兩種基本方法:以程式設計方式將數據推送至索引,或藉由指向支持的數據源的 Azure AI 搜尋服務索引器來提取數據。
本教學課程介紹如何使用推送模型來提升資料編製索引的效率,方法是批次處理要求並使用指數輪詢重試策略。 您可以下載並執行範例應用程式。 本文會說明應用程式的重要層面,以及為資料編製索引時所應考量的因素。
本教學課程將使用 C# 和 Azure SDK for .NET 的 Azure.Search.Documents library 執行下列工作:
- 建立索引
- 測試各種批次大小,以判斷最有效率的大小
- 非同步編製批次的索引
- 使用多個執行緒來增加索引編製速度
- 使用指數輪詢重試策略來重試失敗的文件
必要條件
本教學課程需要下列服務和工具。
Azure 訂用帳戶。 如果您沒有帳戶,您可以建立免費帳戶。
Visual Studio 的任何版本。 範例程式碼和指示已在免費的 Community 版本上經過測試。
下載檔案
本教學課程的原始碼位於 Azure-Samples/azure-search-dotnet-scale GitHub 存放庫中的 optimize-data-indexing/v11 資料夾中。
主要考量
接下來會列出影響編製索引速度的因素。 若要深入瞭解,請參閱 編製大型數據集的索引。
- 服務層級和分割區/復本數目:新增分割區或升級您的階層會增加索引編製速度。
- 索引架構複雜度:新增欄位和欄位屬性會降低索引編製速度。 越小的索引編製速度越快。
- 批次大小:最佳批次大小會根據您的索引架構和數據集而有所不同。
- 線程/背景工作角色數目:單一線程不會充分利用索引編製速度。
- 重試策略:指數輪詢重試策略是最佳編製索引的最佳做法。
- 網路數據傳送速率:資料傳送速率可以是限制因素。 從您的 Azure 環境內為資料編製索引可增加資料傳送速度。
步驟 1:建立 Azure AI 搜尋服務
若要完成本教學課程,您需要 Azure AI 搜尋服務,您可以在 Azure 入口網站 中建立,或在您的目前訂用帳戶下尋找現有的服務。 建議您使用打算在生產環境中使用的相同層級,以便精確地測試索引編製速度並予以最佳化。
取得 Azure AI 搜尋的管理金鑰和 URL
本教學課程使用金鑰式驗證。 複製管理員 API 金鑰,並貼上至 appsettings.json 檔案中。
登入 Azure 入口網站。 從您的搜尋服務 [概觀 ] 頁面取得端點 URL。 範例端點看起來會像是
https://mydemo.search.windows.net。在 [設定]> [金鑰] 中,取得服務上完整權限的管理金鑰。 可互換的管理金鑰有兩個,可在您需要變換金鑰時提供商務持續性。 您可以在新增、修改及刪除物件的要求上使用主要或次要金鑰。
步驟 2:設定您的環境
啟動 Visual Studio 並開啟 OptimizeDataIndexing.sln。
在 方案總管 中,開啟 appsettings.json 以提供服務的連線資訊。
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
步驟 3:探索程式碼
在更新 appsettings.json 後,OptimizeDataIndexing.sln 中的範例程式應該便準備好開始建置並執行。
此程式碼衍生自快速入門:使用 Azure SDK 進行全文檢索搜尋的 C# 區段。 您可以在該文章中找到如何使用 .NET SDK 的基本概念詳細資訊。
這個簡單的 C#/.NET 主控台應用程式會執行下列工作:
- 根據 C#
Hotel類別的資料結構建立新的索引(也會參考Address類別) - 測試各種批次大小,以判斷最有效率的大小
- 以非同步方式為資料編製索引
- 使用多個執行緒來增加索引編製速度
- 使用指數輪詢重試策略來重試失敗的項目
執行程式之前,請花一分鐘研讀此範例的程式碼及索引定義。 相關程式碼位於幾個檔案中:
- Hotel.cs和Address.cs包含定義索引的架構
- DataGenerator.cs 包含一個簡單的類別,可讓您輕鬆地建立大量飯店資料
- ExponentialBackoff.cs 包含可將索引編製程序最佳化的程式碼,如下文所述
- Program.cs 包含的函式可建立和刪除 Azure AI 搜尋服務索引、為資料的批次編製索引,以及測試不同的批次大小
建立索引
此範例程式會使用 Azure SDK for .NET 來定義並建立 Azure AI 搜尋服務索引。 它會利用 FieldBuilder 類別從 C# 資料模型類別產生索引結構。
數據模型是由 Hotel 類別所定義,其中也包含 類別的 Address 參考。 FieldBuilder 會向下鑽研多個類別定義,以針對索引產生複雜的資料結構。 中繼資料標記可用來定義每個欄位的屬性,例如,其是否可搜尋或可排序。
下列來自 Hotel.cs 檔案的程式碼片段示範如何指定單一欄位 (以及對另一個資料模型類別的參考)。
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
在 Program.cs 檔案中,使用 FieldBuilder.Build(typeof(Hotel)) 方法所產生的名稱和欄位集合來定義索引,然後以如下方式來建立:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
產生資料
DataGenerator.cs 檔案中會實作簡單的類別,以產生用於測試的資料。 此類別的唯一目的是要讓您輕鬆地產生具有唯一識別碼的大量文件以供編製索引。
若要取得有唯一識別碼的 100,000 家飯店清單,請執行下列幾行程式碼:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
此範例中有兩種飯店大小可供進行測試:small (小型) 和 large (大型)。
索引的結構描述會影響索引編製速度。 因此,在完成本教學課程之後,請轉換此類別以產生最符合所需索引結構描述的資料。
步驟 4:測試批次大小
Azure AI 搜尋服務支援使用下列 API 來將單一或多個文件載入至索引:
批次中編製檔的索引可大幅改善索引編製效能。 這些批次最多可以是 1,000 份檔,或每個批次最多 16 MB。
為您的資料決定最佳批次大小是將索引編製速度最佳化的關鍵要素。 影響最佳批次大小的兩個主要因素如下:
- 索引的結構描述
- 資料的大小
由於最佳批次大小取決於索引和資料,因此最好的方法是測試不同批次大小,以判斷在您所處的情況下,能達到最快索引編製速度的大小。
下列函式示範用來測試批次大小的簡單方法。
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
由於並非所有文件的大小都相同 (但此範例中確實是如此),因此我們必須估計要傳送到搜尋服務的資料大小。 您可以使用下列函式來執行此動作,此函式會先將對象轉換成 json,然後以位元組為單位來判斷其大小。 這項技術可讓我們根據 MB/s 的索引編製速度,來判斷哪些批次大小最有效率。
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
此函式需要 SearchClient,以及您想要針對每個批次大小進行測試的嘗試次數。 由於每個批次的編製索引時間可能會有所變化,因此預設會嘗試每個批次三次,讓結果在統計上更具統計意義。
await TestBatchSizesAsync(searchClient, numTries: 3);
當您執行函式時,您應該會在控制台中看到輸出,如下列範例所示:
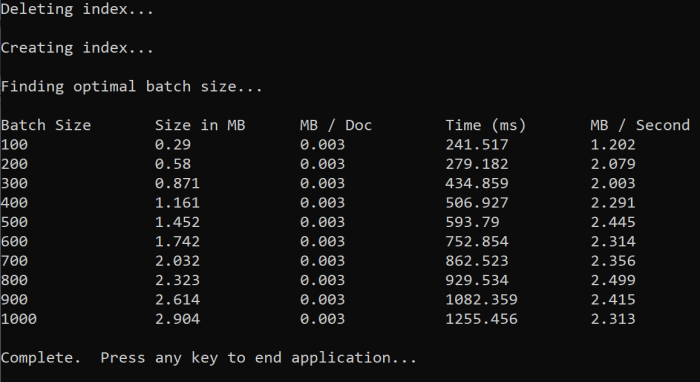
請找出最有效率的批次大小,然後在本教學課程的下一個步驟中使用該批次大小。 您可能會在不同的批次大小中看到 MB/s 峰值。
步驟 5:為數據編製索引
現在您已識別出您想要使用的批次大小,下一個步驟是開始編製數據的索引。 為了有效率地為資料編製索引,此範例會:
- 使用多個線程/背景工作角色
- 實作指數輪詢重試策略
取消批注第 41 到 49 行,然後重新執行程式。 在此次執行中,範例會產生並傳送批次的文件,如果您執行程式碼而不變更參數,則最多為 100,000 個。
使用多個執行緒/背景工作
為了充分利用 Azure AI 搜尋服務的索引編製速度,請使用多個執行緒將批次索引要求同時傳送給服務。
在上述重要考量中,有好幾個會影響最佳的執行緒數目。 您可以修改此範例,並使用不同的執行緒計數進行測試,以判斷您所處情況的最佳執行緒計數。 不過,只要您有數個同時執行的執行緒,應該就能利用絕大多數的效率增益。
當您增加點擊搜尋服務的要求時,您可能會遇到 HTTP 狀態碼,指出要求並未完全成功。 在索引編製期間,兩個常見的 HTTP 狀態碼如下:
- 503 服務無法使用:此錯誤表示系統負載過重,目前無法處理您的要求。
- 207 多重狀態:此錯誤表示某些檔成功,但至少一個失敗。
實作指數輪詢重試策略
如果發生失敗,系統應該就會使用指數輪詢重試策略來重試要求。
Azure AI 搜尋服務的 .NET SDK 會自動重試 503 和其他失敗的要求,但您應實作自己的邏輯才能重試 207。 您可以在重試策略中使用 Polly 等開放原始碼工具。
在此範例中,我們會實行自己的指數輪詢重試策略。 我們一開始會先定義一些變數,包括失敗要求的 maxRetryAttempts 和初始 delay:
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
索引作業的結果會儲存在 IndexDocumentResult result 變數中。 這個變數很重要,因為它可讓您檢查批次中是否有任何文件失敗,如下列範例所示。 如果有部份失敗,則會根據失敗的文件識別碼來建立新批次。
RequestFailedException 例外狀況也應該被攔截下來,因為其表示要求徹底失敗,也應該予以重試。
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
從這裡,將指數輪詢程式代碼包裝成函式,以便輕鬆呼叫。
接著建立另一個函式來管理作用中的執行緒。 為求簡化,這裡並未包含該函式,但您可以在 ExponentialBackoff.cs 中找到。 您可以使用下列命令來呼叫該函數,其中 hotels 是我們想要上傳的資料、1000 是批次大小,而 8 則是並行執行緒的數目:
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
當您執行函式時,應該會看到輸出:
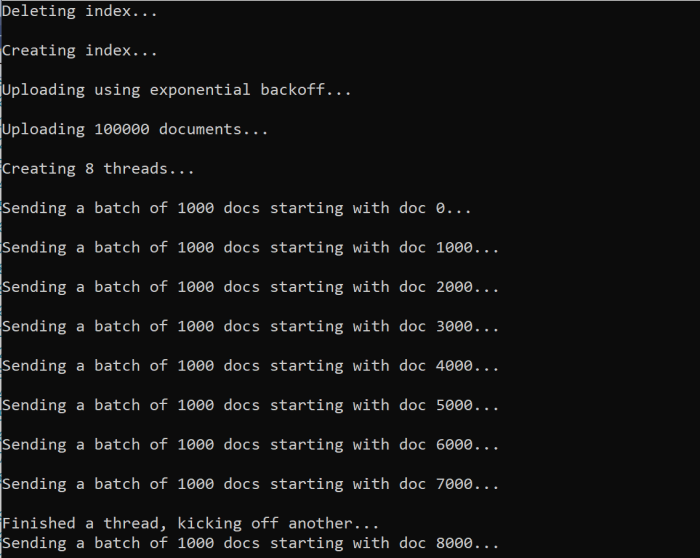
當一批文件失敗時,系統會顯示錯誤以指出失敗以及批次正在重試:
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
函式執行完成後,您就可以確認所有文件都已新增至索引中。
步驟 6:探索索引
您可以在程式以程式設計方式執行之後,或使用 Azure 入口網站 中的搜尋總管,來探索填入的搜尋索引。
程式設計方式
有兩個主要選項可用來檢查索引中的文件數目:文件計數 API 和取得索引統計資料 API。 這兩種途徑都需要一些額外時間來處理,因此如果一開始傳回的文件數目低於您原本的預期,請不必緊張。
文件計數
文件計數操作可在搜尋索引中抓取文件數目的計數:
long indexDocCount = await searchClient.GetDocumentCountAsync();
取得索引統計資料
取得索引統計資料操作會傳回目前索引的文件計數,以及儲存體使用量。 索引統計數據需要比檔計數更長的時間才能更新。
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure 入口網站
在 Azure 入口網站 中,從左側瀏覽窗格中尋找 [索引] 清單中的優化索引編製索引。

文件計數和儲存體大小的根據是取得索引統計資料 API,而且可能需要花幾分鐘的時間才會更新。
重設並重新執行
在開發的早期實驗階段中,若要設計反覆項目,最實用的方法是從 Azure AI 搜尋服務中刪除物件,並讓您的程式碼重建這些物件。 資源名稱是唯一的。 刪除物件可讓您使用相同的名稱加以重新建立。
本教學課程的範例程式碼會檢查是否有現有的索引,並將其刪除,以便您重新執行程式碼。
您也可以使用 Azure 入口網站 來刪除索引。
清除資源
如果您使用自己的訂用帳戶,當專案結束時,建議您移除不再需要的資源。 資源若繼續執行,將需付費。 您可以個別刪除資源,或刪除資源群組以刪除整組資源。
您可以使用左側瀏覽窗格中的 [所有資源] 或 [資源群組] 連結,在 Azure 入口網站 中找到和管理資源。
後續步驟
若要深入了解如何編製大量資料的索引,請嘗試下列教學課程。