Kopieren und Transformieren von Daten in Azure Synapse Analytics mithilfe von Azure Data Factory oder Synapse-Pipelines
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie Daten mithilfe der Kopieraktivität in Azure Data Factory oder Synapse-Pipelines aus und in Azure Synapse Analytics kopieren sowie Daten mithilfe von Datenfluss in Azure Data Lake Storage Gen2 transformieren. Informationen zu Azure Data Factory finden Sie im Einführungsartikel.
Unterstützte Funktionen
Dieser Connector von Azure Synapse Analytics wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR | Verwalteter privater Endpunkt |
|---|---|---|
| Kopieraktivität (Quelle/Senke) | ① ② | ✓ |
| Zuordnungsdatenfluss (Quelle/Senke) | ① | ✓ |
| Lookup-Aktivität | ① ② | ✓ |
| GetMetadata-Aktivität | ① ② | ✓ |
| Skriptaktivität | ① ② | ✓ |
| Aktivität „Gespeicherte Prozedur“ | ① ② | ✓ |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Für die Kopieraktivität unterstützt dieser Connector von Azure Synapse Analytics folgende Funktionen:
- Kopieren Sie Daten mittels SQL-Authentifizierung und Authentifizierung mit Microsoft Entra-Anwendungstoken mit einem Dienstprinzipal oder verwalteten Identitäten für Azure-Ressourcen.
- Als Quelle das Abrufen von Daten mithilfe einer SQL-Abfrage oder gespeicherten Prozedur Sie können auch das parallele Kopieren aus einer Azure Synapse Analytics-Quelle nutzen. Weitere Informationen hierzu finden Sie im Abschnitt Paralleles Kopieren aus Azure Synapse Analytics.
- Als Senke das Laden von Daten mithilfe einer COPY-Anweisung oder PolyBase oder BULK INSERT. Wir empfehlen die COPY-Anweisung oder PolyBase für eine bessere Kopierleistung. Der Connector unterstützt auch das automatische Erstellen einer Zieltabelle mit „DISTRIBUTION = ROUND_ROBIN“ auf Basis des Quellschemas, wenn keine vorhanden ist.
Wichtig
Wenn Sie Daten mithilfe einer Azure Integration Runtime kopieren, konfigurieren Sie eine Firewallregel auf Serverebene, damit Azure-Dienste Zugriff auf den logischen SQL-Server erhalten. Wenn Sie Daten mithilfe einer selbstgehosteten Integration Runtime kopieren, konfigurieren Sie die Firewall, um den entsprechenden IP-Adressbereich zuzulassen. Dieser Bereich schließt die IP-Adresse des Computers ein, der für die Verbindung mit Azure Synapse Analytics verwendet wird.
Erste Schritte
Tipp
Das beste Ergebnis erzielen Sie, indem Sie Daten mithilfe von PolyBase oder der COPY-Anweisung in Azure Synapse Analytics laden. Details finden Sie in den Abschnitten Verwenden von PolyBase zum Laden von Daten in Azure Synapse Analytics und Verwenden der COPY-Anweisung zum Laden von Daten in Azure Synapse Analytics (Vorschau). Eine exemplarische Vorgehensweise mit einem Anwendungsfall finden Sie unter Laden von 1 TB in Azure Synapse Analytics in weniger als 15 Minuten mit Azure Data Factory.
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines mit Azure Synapse Analytics verknüpften Dienstes
Führen Sie die folgenden Schritte aus, um einen mit Azure Synapse Analytics verknüpften Dienst in der Azure-Portal-Benutzeroberfläche zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus und klicken Sie dann auf „Neu“:
Suchen Sie nach „Synapse“, und wählen Sie den Azure Synapse Analytics-Connector aus.
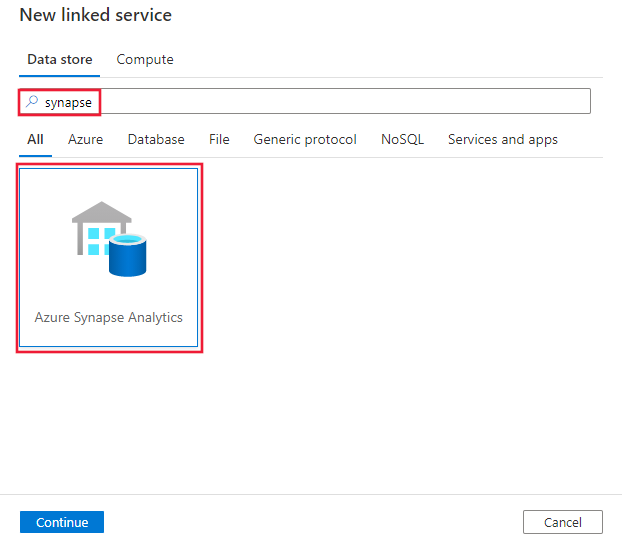
Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
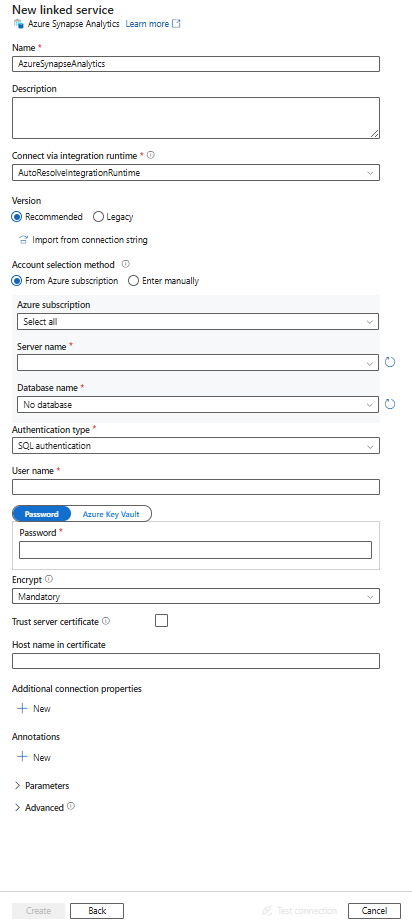
Details zur Connector-Konfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften für das Definieren von Data Factory- und Synapse-Pipelineentitäten speziell für den Connector von Azure Synapse Analytics.
Eigenschaften des verknüpften Diensts
Die empfohlene Version des Azure Synapse Analytics-Connectors unterstützt TLS 1.3. Lesen Sie diesen Abschnitt, um für Ihre Version des Azure Synapse Analytics-Connectors ein Upgrade von der Legacy-Version durchzuführen. Einzelheiten zur Eigenschaft finden Sie in den entsprechenden Abschnitten.
Tipp
Beim Erstellen eines verknüpften Diensts für einen serverlosen SQL-Pool in Azure Synapse über das Azure-Portal:
- Wählen Sie unter Kontoauswahlmethode die Option Manuell eingeben aus.
- Fügen Sie den vollqualifizierten Domänennamen des serverlosen Endpunkts ein. Diesen finden Sie im Azure-Portal auf der Übersichtsseite für Ihren Synapse-Arbeitsbereich in den Eigenschaften unter Serverloser SQL-Endpunkt. Beispiel:
myserver-ondemand.sql-azuresynapse.net. - Geben Sie unter Datenbankname den Datenbanknamen im serverlosen SQL-Pool an.
Tipp
Wenn ein Fehler mit dem Fehlercode „UserErrorFailedToConnectToSqlServer“ auftritt und eine Meldung wie „Das Sitzungslimit für die Datenbank ist XXX und wurde erreicht“ angezeigt wird, fügen Sie Pooling=false zu Ihrer Verbindungszeichenfolge hinzu, und versuchen Sie es erneut.
Empfohlene Version
Diese generischen Eigenschaften werden für einen verknüpften Dienst von Azure Synapse Analytics unterstützt, wenn Sie die empfohlene Version anwenden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die „type“-Eigenschaft muss auf AzureSqlDW festgelegt sein. | Ja |
| server | Name oder Netzwerkadresse der SQL Server-Instanz, mit der Sie eine Verbindung herstellen möchten | Ja |
| database | Der Name der Datenbank. | Ja |
| authenticationType | Der Typ, der für die Authentifizierung verwendet wird. Die zulässigen Werte lauten: SQL (Standard), ServicePrincipal, SystemAssignedManagedIdentity und UserAssignedManagedIdentity. Einzelheiten zu bestimmten Eigenschaften und Voraussetzungen finden Sie im entsprechenden Authentifizierungsabschnitt. | Ja |
| encrypt | Geben Sie an, ob die TLS-Verschlüsselung für alle Daten erforderlich ist, die zwischen dem Client und dem Server gesendet werden. Optionen: obligatorisch (für TRUE, Standard)/optional (für FALSE)/streng | No |
| trustServerCertificate | Geben Sie an, ob der Kanal verschlüsselt wird, während die Zertifikatskette zum Überprüfen der Vertrauensstellung umgangen wird. | No |
| hostNameInCertificate | Hostname, der beim Validieren des Serverzertifikats für die Verbindung verwendet werden soll. Falls nicht angegeben, wird der Servername für die Zertifikatvalidierung verwendet | No |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | No |
Weitere Verbindungseigenschaften finden Sie in der folgenden Tabelle:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| applicationIntent | Workloadtyp der Anwendung beim Herstellen einer Verbindung mit einem Server. Zulässige Werte sind ReadOnly und ReadWrite. |
No |
| connectTimeout | Dauer (in Sekunden), die auf eine Verbindung mit dem Server gewartet wird, bevor der Versuch abgebrochen wird und ein Fehler generiert wird | No |
| connectRetryCount | Anzahl der Neuverbindungsversuche, nachdem ein Leerlaufverbindungsfehler erkannt wurde. Der Wert sollte eine ganze Zahl zwischen 0 und 255 sein. | No |
| connectRetryInterval | Dauer (in Sekunden) zwischen jedem Neuverbindungsversuch, nachdem ein Leerlaufverbindungsfehler erkannt wurde. Der Wert sollte eine ganze Zahl zwischen 1 und 60 sein. | No |
| loadBalanceTimeout | Mindestdauer (in Sekunden), die eine Verbindung im Verbindungspool verbleiben soll, bevor die Verbindung abgebrochen wird. | No |
| commandTimeout | Standardwartezeit (in Sekunden), die gewartet werden soll, bis der Versuch einer Befehlsausführung beendet und ein Fehler generiert wird | No |
| integratedSecurity | Die zulässigen Werte lauten true oder false. Geben Sie beim Wert false an, ob „userName“ und „password“ in der Verbindung angegeben werden. Geben Sie beim Wert true an, ob die aktuellen Anmeldeinformationen für das Windows-Konto für die Authentifizierung verwendet werden. |
No |
| failoverPartner | Name oder Adresse des Partnerservers, mit dem eine Verbindung hergestellt werden soll, wenn der primäre Server ausgefallen ist | No |
| maxPoolSize | Im Verbindungspool zulässige Höchstanzahl der Verbindungen für die angegebene Verbindung | No |
| minPoolSize | Im Verbindungspool zulässige Mindestanzahl der Verbindungen für die angegebene Verbindung. | No |
| multipleActiveResultSets | Die zulässigen Werte lauten true oder false. Wenn Sie true angeben, kann eine Anwendung mehrere aktive Resultsets (MARS) verwalten. Wenn Sie false angeben, muss die Anwendung alle Resultsets aus einem Batch verarbeiten oder abbrechen, bevor andere Batches über diese Verbindung ausgeführt werden können. |
No |
| multiSubnetFailover | Die zulässigen Werte lauten true oder false. Wenn Ihre Anwendung eine Verbindung mit einer AlwaysOn-Verfügbarkeitsgruppe in unterschiedlichen Subnetzen herstellt, ermöglicht das Festlegen dieser Eigenschaft auf true eine schnellere Erkennung des derzeit aktiven Servers und eine schnellere Verbindung mit dem Server. |
No |
| packetSize | Größe der Netzwerkpakete (in Byte), die bei der Kommunikation mit einer Instanz des Servers verwendet werden | No |
| pooling | Die zulässigen Werte lauten true oder false. Wenn Sie true angeben, wird die Verbindung gepoolt. Wenn Sie false angeben, wird die Verbindung bei jeder Anforderung der Verbindung explizit geöffnet. |
No |
SQL-Authentifizierung
Um die SQL-Standardauthentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| userName | Benutzername, der zum Herstellen einer Verbindung mit dem Server verwendet wird. | Ja |
| Kennwort | Das Kennwort für den Benutzernamen. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern. Alternativ können Sie auf ein in Azure Key Vault gespeichertes Geheimnis verweisen. | Ja |
Beispiel: Verwenden der SQL-Authentifizierung
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Kennwort in Azure Key Vault
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dienstprinzipalauthentifizierung
Um die Dienstprinzipal-Authentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| servicePrincipalId | Geben Sie die Client-ID der Anwendung an. | Ja |
| servicePrincipalCredential | Die Anmeldeinformationen für den Dienstprinzipal. Geben Sie den Schlüssel der Anwendung an. Markieren Sie dieses Feld als einen SecureString, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Ja |
| tenant | Geben Sie die Mandanteninformationen (Domänenname oder Mandanten-ID) für Ihre Anwendung an. Diese können Sie abrufen, indem Sie den Mauszeiger über den rechten oberen Bereich im Azure-Portal bewegen. | Ja |
| azureCloudType | Geben Sie für die Dienstprinzipalauthentifizierung die Art der Azure-Cloudumgebung an, bei der Ihre Microsoft Entra-Anwendung registriert ist. Zulässige Werte sind AzurePublic, AzureChina, AzureUsGovernment und AzureGermany. Standardmäßig wird die Cloudumgebung der Data Factory oder der Synapse-Pipeline verwendet. |
No |
Sie müssen auch die folgenden Schritte ausführen:
Erstellen Sie eine Microsoft Entra-Anwendung im Azure-Portal. Notieren Sie sich den Anwendungsnamen und die folgenden Werte zum Definieren des verknüpften Diensts:
- Anwendungs-ID
- Anwendungsschlüssel
- Mandanten-ID
Stellen Sie einen Microsoft Entra-Administrator für Ihren Server im Azure-Portal bereit, sofern dies noch nicht geschehen ist. Der Microsoft Entra-Administrator kann ein Microsoft Entra-Benutzer oder eine Microsoft Entra-Gruppe sein. Wenn Sie der Gruppe mit der verwalteten Identität eine Administratorrolle zuweisen, überspringen Sie die Schritte 3 und 4. Der Administrator hat vollen Zugriff auf die Datenbank.
Erstellen Sie eigenständige Datenbankbenutzer für den Dienstprinzipal. Stellen Sie eine Verbindung mit dem Data Warehouse her, aus dem bzw. in das Sie Daten mithilfe von Tools wie SSMS kopieren möchten. Verwenden Sie dazu eine Microsoft Entra-Identität, die mindestens die Berechtigung „ALTER ANY USER“ aufweist. Führen Sie folgenden T-SQL-Code aus:
CREATE USER [your_application_name] FROM EXTERNAL PROVIDER;Gewähren Sie dem Dienstprinzipal die notwendigen Berechtigungen, wie bei SQL- oder anderen Benutzern üblich. Führen Sie den folgenden Code aus, oder machen Sie sich mit weiteren Optionen vertraut. Wenn Sie PolyBase zum Laden der Daten verwenden möchten, machen Sie sich mit der benötigten Datenbankberechtigung vertraut.
EXEC sp_addrolemember db_owner, [your application name];Konfigurieren Sie einen mit Azure Synapse Analytics verknüpften Dienst in einem Azure Data Factory- oder Synapse-Arbeitsbereich.
Beispiel eines verknüpften Diensts mit Dienstprinzipalauthentifizierung
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
So verwenden Sie verwaltete Identitäten für die Azure-Ressourcenauthentifizierung
Ein Data Factory- oder Synapse-Arbeitsbereich kann einer verwalteten Identität für Azure-Ressourcen zugeordnet werden, die die Ressource darstellt. Sie können diese verwaltete Identität für die Authentifizierung von Azure Synapse Analytics verwenden. Die angegebene Ressource kann mithilfe dieser Identität auf Daten in Ihrem Data Warehouse zugreifen und diese kopieren.
Um die vom System zugewiesene verwaltete Identitätsauthentifizierung zu verwenden, geben Sie die generischen Eigenschaften an, die im vorherigen Abschnitt beschrieben sind, und führen Sie diese Schritte aus.
Stellen Sie einen Microsoft Entra-Administrator für Ihren Server im Azure-Portal bereit, sofern dies noch nicht geschehen ist. Der Microsoft Entra-Administrator kann ein Microsoft Entra-Benutzer oder eine Microsoft Entra-Gruppe sein. Wenn Sie der Gruppe mit der verwalteten Identität eine Administratorrolle zuweisen, überspringen Sie die Schritte 3 und 4. Der Administrator hat vollen Zugriff auf die Datenbank.
Erstellen Sie Benutzer der eigenständigen Datenbank für die systemseitig zugewiesene verwaltete Identität. Stellen Sie eine Verbindung mit dem Data Warehouse her, aus dem bzw. in das Sie Daten mithilfe von Tools wie SSMS kopieren möchten. Verwenden Sie dazu eine Microsoft Entra-Identität, die mindestens die Berechtigung „ALTER ANY USER“ aufweist. Führen Sie den folgenden T-SQL-Befehl aus.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Gewähren Sie der systemseitig zugewiesenen verwalteten Identität erforderliche Berechtigungen, wie Sie es normalerweise für SQL- und andere Benutzer tun. Führen Sie den folgenden Code aus, oder machen Sie sich mit weiteren Optionen vertraut. Wenn Sie PolyBase zum Laden der Daten verwenden möchten, machen Sie sich mit der benötigten Datenbankberechtigung vertraut.
EXEC sp_addrolemember db_owner, [your_resource_name];Konfigurieren eines verknüpften Azure Synapse Analytics-Diensts.
Beispiel:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Ein Data Factory- oder Synapse-Arbeitsbereich kann einer verwalteten Identität für Azure-Ressourcen zugeordnet werden, die die Ressource darstellt. Sie können diese verwaltete Identität für die Authentifizierung von Azure Synapse Analytics verwenden. Die angegebene Ressource kann mithilfe dieser Identität auf Daten in Ihrem Data Warehouse zugreifen und diese kopieren.
Um die vom Benutzer zugewiesene verwaltete Identitätsauthentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Anmeldeinformationen | Geben Sie die benutzerseitig zugewiesene verwaltete Identität als Anmeldeinformationsobjekt an. | Ja |
Sie müssen auch die folgenden Schritte ausführen:
Stellen Sie einen Microsoft Entra-Administrator für Ihren Server im Azure-Portal bereit, sofern dies noch nicht geschehen ist. Der Microsoft Entra-Administrator kann ein Microsoft Entra-Benutzer oder eine Microsoft Entra-Gruppe sein. Wenn Sie der Gruppe mit der verwalteten Identität eine Administratorrolle zuweisen, überspringen Sie die Schritte 3 und 4. Der Administrator hat vollen Zugriff auf die Datenbank.
Erstellen Sie Benutzer der eigenständigen Datenbank für die benutzerseitig zugewiesene verwaltete Identität. Stellen Sie eine Verbindung mit dem Data Warehouse her, aus dem bzw. in das Sie Daten mithilfe von Tools wie SSMS kopieren möchten. Verwenden Sie dazu eine Microsoft Entra-Identität, die mindestens die Berechtigung „ALTER ANY USER“ aufweist. Führen Sie den folgenden T-SQL-Befehl aus.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Erstellen Sie mindestens eine benutzerseitig zugewiesene verwaltete Identität, und gewähren Sie dieser Identität die erforderlichen Berechtigungen, wie Sie es normalerweise für SQL- und andere Benutzer tun. Führen Sie den folgenden Code aus, oder machen Sie sich mit weiteren Optionen vertraut. Wenn Sie PolyBase zum Laden der Daten verwenden möchten, machen Sie sich mit der benötigten Datenbankberechtigung vertraut.
EXEC sp_addrolemember db_owner, [your_resource_name];Weisen Sie Ihrer Data Factory eine oder mehrere benutzerseitig zugewiesene verwaltete Identitäten zu, und erstellen Sie Anmeldeinformationen für jede benutzerseitig zugewiesene verwaltete Identität.
Konfigurieren eines verknüpften Azure Synapse Analytics-Diensts.
Beispiel
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Legacy-Version
Diese generischen Eigenschaften werden für einen verknüpften Dienst von Azure Synapse Analytics unterstützt, wenn Sie die Legacy-Version anwenden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die „type“-Eigenschaft muss auf AzureSqlDW festgelegt sein. | Ja |
| connectionString | Geben Sie Informationen, die zur Verbindung mit der Instanz von Azure Synapse Analytics erforderlich sind, für die Eigenschaft connectionString ein. Markieren Sie dieses Feld als „SecureString“, um es sicher zu speichern. Sie können auch das Kennwort/den Dienstprinzipalschlüssel in Azure Key Vault ablegen und bei Verwendung der SQL-Authentifizierung die password-Konfiguration aus der Verbindungszeichenfolge pullen. Weitere Einzelheiten finden Sie im Artikel Speichern von Anmeldeinformationen in Azure Key Vault. |
Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (sofern sich Ihr Datenspeicher in einem privaten Netzwerk befindet). Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | No |
Informationen zu verschiedenen Authentifizierungstypen finden Sie in den folgenden Abschnitten zu bestimmten Eigenschaften und Voraussetzungen:
- SQL-Authentifizierung für die Legacy-Version
- Dienstprinzipalauthentifizierung für die Legacy-Version
- Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität für die Legacyversion
- Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität für die Legacyversion
SQL-Authentifizierung für die Legacy-Version
Um die SQL-Authentifizierung zu verwenden, geben Sie die generischen Eigenschaften an, die im vorherigen Abschnitt beschrieben werden.
Dienstprinzipalauthentifizierung für die Legacy-Version
Um die Dienstprinzipal-Authentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| servicePrincipalId | Geben Sie die Client-ID der Anwendung an. | Ja |
| servicePrincipalKey | Geben Sie den Schlüssel der Anwendung an. Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Ja |
| tenant | Geben Sie die Mandanteninformationen, wie Domänenname oder Mandanten-ID, für Ihre Anwendung an. Diese können Sie abrufen, indem Sie im Azure-Portal mit der Maus auf den Bereich oben rechts zeigen. | Ja |
| azureCloudType | Geben Sie für die Dienstprinzipalauthentifizierung die Art der Azure-Cloudumgebung an, bei der Ihre Microsoft Entra-Anwendung registriert ist. Zulässige Werte sind AzurePublic, AzureChina, AzureUsGovernment und AzureGermany. Standardmäßig wird die Cloudumgebung der Data Factory oder der Synapse-Pipeline verwendet. |
No |
Außerdem müssen Sie die Schritte im Abschnitt Dienstprinzipalauthentifizierung ausführen, um die entsprechende Berechtigung zu erteilen.
Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität für die Legacyversion
Um die Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität zu verwenden, führen Sie den gleichen Schritt für die empfohlene Version im Abschnitt Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität aus.
Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität für die Legacyversion
Um die Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität zu verwenden, führen Sie den gleichen Schritt für die empfohlene Version im Abschnitt Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität aus.
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets.
Die folgenden Eigenschaften werden beim Dataset von Azure Synapse Analytics unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf AzureSqlDWTable festgelegt sein. | Ja |
| schema | Name des Schemas. | Quelle: Nein, Senke: Ja |
| table | Name der Tabelle/Ansicht. | Quelle: Nein, Senke: Ja |
| tableName | Name der Tabelle/Ansicht mit Schema. Diese Eigenschaft wird aus Gründen der Abwärtskompatibilität weiterhin unterstützt. Verwenden Sie für eine neue Workload schema und table. |
Quelle: Nein, Senke: Ja |
Beispiel für Dataseteigenschaften
{
"name": "AzureSQLDWDataset",
"properties":
{
"type": "AzureSqlDWTable",
"linkedServiceName": {
"referenceName": "<Azure Synapse Analytics linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Quelle und Senke von Azure Synapse Analytics unterstützt werden.
Azure Synapse Analytics als Quelle
Tipp
Weitere Informationen zum effizienten Laden von Daten aus Azure Synapse Analytics mittels Datenpartitionierung finden Sie unter Paralleles Kopieren aus Azure Synapse Analytics.
Legen Sie zum Kopieren von Daten aus Azure Synapse Analytics die Eigenschaft type der Quelle der Kopieraktivität auf SqlDWSource fest. Die folgenden Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf SqlDWSource festgelegt sein. | Ja |
| sqlReaderQuery | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. Beispiel: select * from MyTable. |
Nein |
| sqlReaderStoredProcedureName | Name der gespeicherten Prozedur, die Daten aus der Quelltabelle liest. Die letzte SQL-Anweisung muss eine SELECT-Anweisung in der gespeicherten Prozedur sein. | Nein |
| storedProcedureParameters | Parameter für die gespeicherte Prozedur. Zulässige Werte sind Namen oder Name-Wert-Paare. Die Namen und die Groß-/Kleinschreibung von Parametern müssen denen der Parameter der gespeicherten Prozedur entsprechen. |
Nein |
| isolationLevel | Gibt das Sperrverhalten für Transaktionen für die SQL-Quelle an. Zulässige Werte sind: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Ohne Angabe wird die Standardisolationsstufe der Datenbank verwendet. Weitere Informationen finden Sie unter system.data.isolationlevel. | Nein |
| partitionOptions | Hiermit werden die Datenpartitionierungsoptionen angegeben, mit denen Daten aus Azure Synapse Analytics geladen werden. Zulässige Werte sind: None (Standardwert), PhysicalPartitionsOfTable und DynamicRange. Wenn eine Partitionsoption aktiviert ist (d. h. nicht None), wird der Grad an Parallelität zum gleichzeitigen Laden von Daten aus einer Azure Synapse Analytics-Instanz durch die Einstellung parallelCopies für die Kopieraktivität gesteuert. |
Nein |
| partitionSettings | Geben Sie die Gruppe der Einstellungen für die Datenpartitionierung an. Verwenden Sie diese Option, wenn die Partitionsoption nicht None lautet. |
Nein |
Unter partitionSettings: |
||
| partitionColumnName | Geben Sie den Namen der Quellspalte als „integer“ oder „date/datetime“ (int, smallint, bigint, date, smalldatetime, datetime, datetime2 oder datetimeoffset) an, der von der Bereichspartitionierung für das parallele Kopieren verwendet wird. Ohne Angabe wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet.Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?DfDynamicRangePartitionCondition in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank. |
Nein |
| partitionUpperBound | Der maximale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank. |
Nein |
| partitionLowerBound | Der minimale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank. |
Nein |
Beachten Sie Folgendes:
- Wenn Sie zum Abrufen von Daten eine gespeicherte Prozedur in der Quelle verwenden und die gespeicherte Prozedur beim Übergeben eines anderen Parameterwerts ein anderes Schema zurückgibt, kommt es möglicherweise beim Importieren eines Schemas über die Benutzeroberfläche oder beim Kopieren von Daten in eine SQL-Datenbank zu einem Fehler oder einem unerwarteten Ergebnis.
Beispiel: Verwenden von SQL-Abfragen
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Beispiel: Verwenden von gespeicherten Prozeduren
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Gespeicherte Beispielprozedur:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Azure Synapse Analytics als Senke
Azure Data Factory und Synapse-Pipelines unterstützen drei Möglichkeiten zum Laden von Daten in Azure Synapse Analytics.
- Verwenden der COPY-Anweisung zum Laden von Daten in Azure Synapse Analytics
- Verwenden von PolyBase
- Verwenden von BULK INSERT
Über die COPY-Anweisung oder PolyBase können Sie Daten am schnellsten laden und am besten skalieren.
Legen Sie zum Kopieren von Daten in Azure Synapse Analytics den Senkentyp in der Kopieraktivität auf SqlDWSink fest. Die folgenden Eigenschaften werden im Abschnitt sink der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Senke der Kopieraktivität muss auf SqlDWSink festgelegt sein. | Ja |
| allowPolyBase | Gibt an, ob PolyBase zum Laden von Daten in Azure Synapse Analytics verwendet werden soll. allowCopyCommand und allowPolyBase können nicht beide auf „true“ festgelegt sein. Einschränkungen und Einzelheiten finden Sie im Abschnitt Verwenden von PolyBase zum Laden von Daten in Azure Synapse Analytics. Zulässige Werte sind true und false (Standard). |
Nein. Beim Verwenden von PolyBase anwenden. |
| polyBaseSettings | Eine Gruppe von Eigenschaften, die angegeben werden können, wenn die Eigenschaft allowPolybase auf true festgelegt ist. |
Nein. Beim Verwenden von PolyBase anwenden. |
| allowCopyCommand | Gibt an, ob die COPY-Anweisung zum Laden von Daten in Azure Synapse Analytics verwendet werden soll. allowCopyCommand und allowPolyBase können nicht beide auf „true“ festgelegt sein. Einschränkungen und Einzelheiten finden Sie im Abschnitt Verwenden der COPY-Anweisung zum Laden von Daten in Azure Synapse Analytics. Zulässige Werte sind true und false (Standard). |
Nein. Beim Verwenden von COPY anwenden. |
| copyCommandSettings | Eine Gruppe von Eigenschaften, die angegeben werden können, wenn die Eigenschaft allowCopyCommand auf TRUE festgelegt ist. |
Nein. Beim Verwenden von COPY anwenden. |
| writeBatchSize | Anzahl der Zeilen, die in die SQL-Tabelle pro Batch eingefügt werden sollen. Zulässiger Wert: integer (Anzahl der Zeilen) Standardmäßig bestimmt der Dienst die geeignete Batchgröße dynamisch auf der Grundlage der Zeilengröße. |
Nein. Beim Verwenden von BULK INSERT anwenden. |
| writeBatchTimeout | Die Wartezeit für den Abschluss der Insert- und Upsert-Vorgänge und die gespeicherte Prozedur, bevor ein Timeout auftritt. Zulässige Werte werden für den Zeitraum verwendet. Beispiel: „00:30:00“ für 30 Minuten. Wenn kein Wert festgelegt ist, wird für das Timeout der Standardwert „00:30:00“ verwendet. |
Nein Beim Verwenden von BULK INSERT anwenden. |
| preCopyScript | Geben Sie eine SQL-Abfrage an, die bei jeder Ausführung von der Kopieraktivität ausgeführt werden soll, bevor Daten in Azure Synapse Analytics geschrieben werden. Sie können diese Eigenschaft nutzen, um vorab geladene Daten zu bereinigen. | Nein |
| tableOption | Gibt an, ob die Senkentabelle auf Basis des Quellschemas automatisch erstellt werden soll, wenn sie nicht vorhanden ist. Zulässige Werte: none (Standard), autoCreate. |
Nein |
| disableMetricsCollection | Der Dienst sammelt Metriken wie Azure Synapse Analytics-DWUs für die Leistungsoptimierung von Kopiervorgängen und Empfehlungen, wodurch zusätzlicher Zugriff auf die Masterdatenbank ermöglicht wird. Wenn Sie sich wegen dieses Verhaltens Gedanken machen, geben Sie true an, um es zu deaktivieren. |
Nein (Standard = false) |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Ohne |
| WriteBehavior | Geben Sie das Schreibverhalten für die Kopieraktivität an, um Daten in Azure Synapse Analytics zu laden. Die zulässigen Werte sind Insert und Upsert. Standardmäßig verwendet der Dienst „Insert“, um Daten zu laden. |
Nein |
| upsertSettings | Geben Sie die Gruppe der Einstellungen für das Schreibverhalten an. Wenden Sie dies an, wenn die WriteBehavior-Option Upsert ist. |
Nein |
Unter upsertSettings: |
||
| keys | Geben Sie die Spaltennamen für die eindeutige Zeilenidentifikation an. Es kann entweder ein einzelner Schlüssel oder eine Reihe von Schlüsseln verwendet werden. Bei fehlender Angabe wird der Primärschlüssel verwendet. | Nein |
| interimSchemaName | Geben Sie das Zwischenschema zum Erstellen einer Zwischentabelle an. Hinweis: Benutzer*innen müssen über die Berechtigung zum Erstellen und Löschen einer Tabelle verfügen. Standardmäßig verwendet die Zwischentabelle das gleiche Schema wie die Senkentabelle. | Nein |
Beispiel 1: Azure Synapse Analytics-Senke
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true,
"polyBaseSettings":
{
"rejectType": "percentage",
"rejectValue": 10.0,
"rejectSampleValue": 100,
"useTypeDefault": true
}
}
Beispiel 2: Upsert-Daten
"sink": {
"type": "SqlDWSink",
"writeBehavior": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
],
"interimSchemaName": "<interim schema name>"
},
}
Paralleles Kopieren aus Azure Synapse Analytics
Der Azure Synapse Analytics-Connector in der Kopieraktivität verfügt über eine integrierte Datenpartitionierung zum parallelen Kopieren von Daten. Die Datenpartitionierungsoptionen befinden sich auf der Registerkarte Quelle der Kopieraktivität.
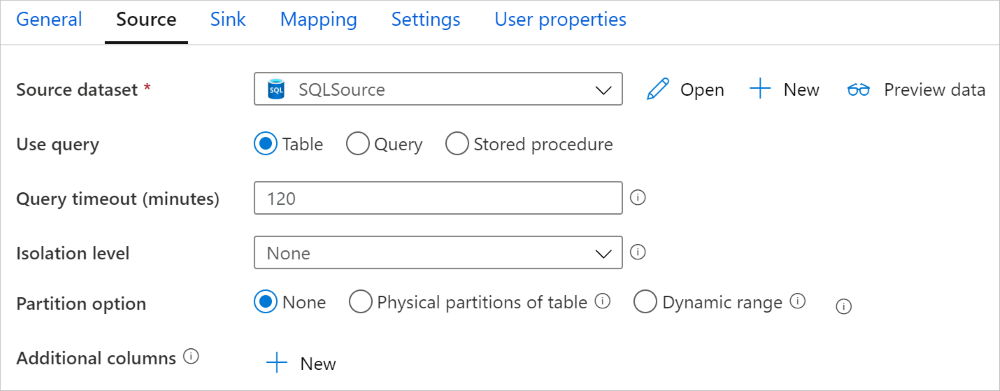
Wenn Sie partitioniertes Kopieren aktivieren, führt die Kopieraktivität parallele Abfragen für Ihre Azure Synapse Analytics-Quelle aus, um Daten anhand von Partitionen zu laden. Der Parallelitätsgrad wird über die Einstellung parallelCopies der Kopieraktivität gesteuert. Wenn Sie z. B. parallelCopies auf vier festlegen, generiert der Dienst vier Abfragen gleichzeitig und führt diese gemäß den angegebenen Partitionsoptionen und -einstellungen aus. Jede dieser Abfragen ruft einen Teil der Daten von Ihrer Azure Synapse Analytics-Instanz ab.
Es wird empfohlen, das parallele Kopieren mit Datenpartitionierung zu aktivieren. Das gilt insbesondere, wenn Sie große Datenmengen aus Ihrer Azure Synapse Analytics-Instanz laden. Im Anschluss finden Sie empfohlene Konfigurationen für verschiedene Szenarien. Beim Kopieren von Daten in einen dateibasierten Datenspeicher wird empfohlen, mehrere Dateien in einen Ordner zu schreiben (nur den Ordnernamen anzugeben). In diesem Fall ist die Leistung besser als beim Schreiben in eine einzelne Datei.
| Szenario | Empfohlene Einstellungen |
|---|---|
| Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen | Partitionsoption: Physische Partitionen der Tabelle. Während der Ausführung erkennt der Dienst automatisch die physischen Partitionen und kopiert Daten nach Partitionen. Um zu überprüfen, ob Ihre Tabelle eine physische Partition besitzt oder nicht, können Sie auf diese Abfrage verweisen. |
| Vollständiges Laden aus einer großen Tabelle ohne physische Partitionen, aber mit einer integer- oder datetime-Spalte für die Datenpartitionierung. | Partitionsoptionen: Dynamische Bereichspartitionierung Partitionsspalte (optional): Geben Sie die Spalte für die Datenpartitionierung an. Ohne Angabe wird der Index oder die Primärschlüsselspalte verwendet. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle; alle Zeilen in der Tabelle werden partitioniert und kopiert. Wenn nicht angegeben, werden die Werte für die Kopieraktivität automatisch erkannt. Wenn Ihre Partitionsspalte "ID" beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20 und die obere Grenze auf 80 und die Parallelkopie auf 4 setzen, ruft der Dienst Daten nach 4 Partitionen ab - IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage ohne physische Partitionen, aber mit einer integer- oder date/datetime-Spalte für die Datenpartitionierung. | Partitionsoptionen: Dynamische Bereichspartitionierung Abfrage: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte für die Datenpartitionierung an. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle; alle Zeilen im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Wenn Ihre Partitionsspalte „ID“ beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20, die obere Grenze auf 80 und die Parallelkopie auf 4 festlegen, ruft der Dienst Daten nach 4 Partitionen ab – IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. Hier finden Sie weitere Beispiele für verschiedene Szenarien: 1. Abfrage der gesamten Tabelle: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Abfrage aus einer Tabelle mit Spaltenauswahl und zusätzlichen Where-Klausel-Filtern: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Abfragen mit Unterabfragen: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Abfrage mit Partition in Unterabfrage: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Bewährte Methoden zum Laden von Daten mit Partitionierungsoption:
- Wählen Sie eine aussagekräftige Spalte als Partitionsspalte (wie Primärschlüssel oder eindeutiger Schlüssel), um Datenabweichungen zu vermeiden.
- Wenn die Tabelle eine integrierte Partition aufweist, verwenden Sie die Partitionsoption „Physikalische Partitionen der Tabelle“, um eine bessere Leistung zu erzielen.
- Wenn Sie Azure Integration Runtime zum Kopieren von Daten verwenden, können Sie größere „Datenintegrationseinheiten (Data Integration Units, DIU)“ festlegen (> 4), um mehr Computingressourcen zu nutzen. Prüfen Sie dort die anwendbaren Szenarien.
- „Grad der Kopierparallelität“ steuert die Partitionsnummern. Ein zu großer Wert schadet manchmal der Leistung. Deshalb wird empfohlen, diesen Wert wie folgt festzulegen: (DIU oder Anzahl der selbstgehosteten IR-Knoten) × (2 bis 4).
- Beachten Sie, dass Azure Synapse Analytics gleichzeitig maximal 32 Abfragen ausführen kann. Wenn Sie den „Grad der Kopierparallelität“ auf einen zu hohen Wert festlegen, kann dies zu einem Drosselungsproblem im Zusammenhang mit Azure Synapse Analytics führen.
Beispiel: Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen
"source": {
"type": "SqlDWSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Beispiel: Abfrage mit dynamischer Bereichspartition
"source": {
"type": "SqlDWSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Beispielabfrage zur Überprüfung der physischen Partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Wenn die Tabelle eine physische Partition besitzt, würde „HasPartition“ als „Yes“ (Ja) angezeigt werden.
Verwenden der COPY-Anweisung zum Laden von Daten in Azure Synapse Analytics
Die Verwendung der COPY-Anweisung ist eine einfache und flexible Möglichkeit, Daten mit hohem Durchsatz in Azure Synapse Analytics zu laden. Weitere Informationen finden Sie unter Massenladen von Daten mit der COPY-Anweisung.
- Wenn sich Ihre Quelldaten in Azure Blob oder Azure Data Lake Storage Gen2 befinden und das Format kompatibel mit der COPY-Anweisung ist, können Sie über die Kopieraktivität die COPY-Anweisung direkt aufrufen, damit Azure Synapse Analytics die Daten aus der Quelle abrufen kann. Details finden Sie unter Direktes Kopieren mithilfe der COPY-Anweisung .
- Wenn der Speicher und das Format der Quelldaten von der COPY-Anweisung ursprünglich nicht unterstützt werden, können Sie stattdessen das Feature Gestaffeltes Kopieren mithilfe der COPY-Anweisung verwenden. Das gestaffelte Kopieren bietet auch einen höheren Durchsatz. Es konvertiert die Daten automatisch in ein mit der COPY-Anweisung kompatibles Format, speichert die Daten in Azure Blob Storage und ruft dann die COPY-Anweisung auf, um die Daten in Azure Synapse Analytics zu laden.
Tipp
Bei Verwendung der COPY-Anweisung mit Azure Integration Runtime sind die effektiven Datenintegrationseinheiten (DIUs) immer auf 2 festgelegt. Die Optimierung der DIU wirkt sich nicht auf die Leistung aus, da das Laden von Daten aus dem Speicher durch die Azure Synapse-Engine erfolgt.
Direktes Kopieren mithilfe der COPY-Anweisung
Die COPY-Anweisung von Azure Synapse Analytics unterstützt direkt Azure Blob und Azure Data Lake Storage Gen2. Wenn Ihre Daten die in diesem Abschnitt beschriebenen Kriterien erfüllen, können Sie mithilfe der COPY-Anweisung direkt aus dem Quelldatenspeicher in Azure Synapse Analytics kopieren. Andernfalls können Sie das gestaffelte Kopieren mithilfe der COPY-Anweisung verwenden. Der Dienst überprüft die Einstellungen und gibt bei der Ausführung der Copy-Aktivität einen Fehler aus, wenn die Kriterien nicht erfüllt werden.
Der mit der Quelle verknüpfte Dienst und das Format verfügen über die folgenden Typen und Authentifizierungsmethoden:
Unterstützter Quelldatenspeichertyp Unterstütztes Format Unterstützter Quellauthentifizierungstyp Azure-Blob Text mit Trennzeichen Kontoschlüsselauthentifizierung, SAS-Authentifizierung (Shared Access Signature), Dienstprinzipalauthentifizierung (mit ServicePrincipalKey), Authentifizierung mit systemseitig zugewiesener verwalteter Identität Parquet Kontoschlüsselauthentifizierung, SAS-Authentifizierung (Shared Access Signature) ORC Kontoschlüsselauthentifizierung, SAS-Authentifizierung (Shared Access Signature) Azure Data Lake Storage Gen2 Text mit Trennzeichen
Parquet
ORCKontoschlüsselauthentifizierung, Dienstprinzipalauthentifizierung (mit ServicePrincipalKey), SAS-Authentifizierung (Shared Access Signature), Authentifizierung mit systemseitig zugewiesener verwalteter Identität Wichtig
- Wenn Sie die Authentifizierung per verwalteter Identität für den mit dem Speicher verknüpften Dienst verwenden, machen Sie sich jeweils mit den erforderlichen Konfigurationen für Azure Blob und Azure Data Lake Storage Gen2 vertraut.
- Wenn Ihre Azure Storage-Instanz mit einem VNET-Dienstendpunkt konfiguriert ist, müssen Sie die Authentifizierung per verwalteter Identität mit für das Speicherkonto aktivierter Option „Vertrauenswürdigen Microsoft-Diensten den Zugriff auf dieses Speicherkonto erlauben“ verwenden. Informationen hierzu finden Sie unter Auswirkungen der Verwendung von VNET-Dienstendpunkten mit Azure Storage.
Die Formateinstellungen lauten folgendermaßen:
- Bei Parquet:
compressionkann auf Keine Komprimierung, Snappy oderGZipfestgelegt werden. - Bei ORC: kann
compressionauf Keine Komprimierung,zliboder Snappy festgelegt sein. - Bei Text mit Trennzeichen:
rowDelimiterist explizit festgelegt auf einzelnes Zeichen oder \r\n. Der Standardwert wird nicht unterstützt.nullValuewird als Standardwert übernommen oder ist auf leere Zeichenfolge („“) festgelegt.encodingNamewird als Standardwert übernommen oder ist auf utf-8 oder utf-16 festgelegt.escapeCharmussquoteCharentsprechen und darf nicht leer sein.skipLineCountwird als Standardwert übernommen oder ist auf 0 festgelegt.compressionkann auf keine Komprimierung oderGZipfestgelegt werden.
- Bei Parquet:
Wenn es sich bei der Quelle um einen Ordner handelt, muss
recursivebeim Kopiervorgang auf „TRUE“ festgelegt sein, undwildcardFilenamemuss*oder*.*sein.wildcardFolderPath,wildcardFilename(anders als*oder*.*),modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscoveryundadditionalColumnswerden nicht angegeben.
Die folgenden Einstellungen der COPY-Anweisung werden unter allowCopyCommand in der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| defaultValues | Gibt die Standardwerte für die einzelnen Zielspalten in Azure Synapse Analytics an. Die Standardwerte in der Eigenschaft überschreiben die in Data Warehouse festgelegte DEFAULT-Einschränkung, und die Identitätsspalte darf keinen Standardwert haben. | Nein |
| additionalOptions | Zusätzliche Optionen, die direkt in der WITH-Klausel in der COPY-Anweisung an eine COPY-Anweisung in Azure Synapse Analytics übergeben werden. Geben Sie den Wert so an, wie er gemäß den Anforderungen der COPY-Anweisung erforderlich ist. | Nein |
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Gestaffeltes Kopieren mithilfe der COPY-Anweisung
Wenn Ihre Quelldaten nicht nativ mit der COPY-Anweisung kompatibel sind, können Sie die Daten über eine zwischengeschaltete Azure Blob- oder Azure Data Lake Storage Gen2-Instanz mit Staging kopieren (es kann nicht Azure Storage Premium sein). In diesem Fall konvertiert der Dienst die Daten automatisch, damit das Datenformat den Anforderungen der COPY-Anweisung entspricht. Dann ruft er die COPY-Anweisung zum Laden von Daten in Azure Synapse Analytics auf. Abschließend werden Sie die temporären Daten im Speicher bereinigt. Ausführliche Informationen zum Kopieren von Daten mithilfe von Staging finden Sie unter Gestaffeltes Kopieren.
Um dieses Feature verwenden zu können, erstellen Sie einen mit Azure Blob Storage verknüpften Dienst oder einen mit Azure Data Lake Storage Gen2 verknüpften Dienst mit Authentifizierung per Kontoschlüssel oder systemverwalteter Identität, der auf das Azure Storage-Konto als Zwischenspeicher verweist.
Wichtig
- Wenn Sie die Authentifizierung per verwalteter Identität für den verknüpften Stagingdienst verwenden, machen Sie sich jeweils mit den erforderlichen Konfigurationen für Azure Blob und Azure Data Lake Storage Gen2 vertraut. Zudem müssen Sie Ihrer verwalteten Identität des Azure Synapse Analytics-Arbeitsbereichs in Ihrem Staging-Azure Blob Storage- oder Azure Data Lake Storage Gen2-Konto Berechtigungen erteilen. Informationen dazu, wie Sie diese Berechtigung zuweisen, finden Sie unter: Erteilen von Berechtigungen für die verwaltete Identität eines Arbeitsbereichs.
- Wenn Ihre Azure Storage-Staginginstanz mit einem VNET-Dienstendpunkt konfiguriert ist, müssen Sie die Authentifizierung per verwalteter Identität mit für das Speicherkonto aktivierter Option „Vertrauenswürdigen Microsoft-Diensten den Zugriff auf dieses Speicherkonto erlauben“ verwenden. Informationen hierzu finden Sie unter Auswirkungen der Verwendung von VNET-Dienstendpunkten mit Azure Storage.
Wichtig
Wenn Ihre Azure Storage-Staginginstanz mit verwaltetem privatem Endpunkt konfiguriert und die Speicherfirewall aktiviert ist, müssen Sie die Authentifizierung per verwalteter Identität verwenden und dem Speicherblob-Datenleser Berechtigungen für die Synapse SQL Server-Instanz gewähren, um sicherzustellen, dass er während des Ladens mit der COPY-Anweisung auf die bereitgestellten Dateien zugreifen kann.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Verwenden von PolyBase zum Laden von Daten in Azure Synapse Analytics
Mit PolyBase lassen sich große Datenmengen effizient und mit hohem Durchsatz in Azure Synapse Analytics laden. Wenn Sie PolyBase anstelle des standardmäßigen BULKINSERT-Mechanismus verwenden, wird der Durchsatz erheblich gesteigert.
- Wenn sich Ihre Quelldaten in Azure Blob oder Azure Data Lake Storage Gen2 befinden und das Format PolyBase-kompatibel ist, können Sie PolyBase mit der Kopieraktivität direkt aufrufen, damit Azure Synapse Analytics die Daten aus der Quelle abrufen kann. Details finden Sie unter Direktes Kopieren mithilfe von PolyBase .
- Wenn der Speicher und das Format der Quelldaten von PolyBase ursprünglich nicht unterstützt werden, können Sie stattdessen das Feature Gestaffeltes Kopieren mit PolyBase verwenden. Das gestaffelte Kopieren bietet auch einen höheren Durchsatz. Es konvertiert die Daten automatisch in ein mit PolyBase kompatibles Format, speichert die Daten in Azure Blob Storage und ruft dann PolyBase auf, um die Daten in Azure Synapse Analytics zu laden.
Tipp
Weitere Informationen finden Sie unter Bewährte Methoden für die Verwendung von PolyBase. Bei Verwendung von PolyBase mit Azure Integration Runtime sind die effektiven Datenintegrationseinheiten (DIUs) für direkten oder gestaffelten Speicher in Synapse immer auf 2 festgelegt. Die Optimierung der DIU wirkt sich nicht auf die Leistung aus, da das Laden von Daten aus dem Speicher durch die Synapse-Engine erfolgt.
Die folgenden PolyBase-Eigenschaften werden unter polyBaseSettings in der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| rejectValue | Gibt die Anzahl oder den Prozentsatz von Zeilen an, die abgelehnt werden können, bevor für die Abfrage ein Fehler auftritt. Weitere Informationen zu den PolyBase-Ablehnungsoptionen finden Sie im Abschnitt „Argumente“ in CREATE EXTERNAL TABLE (Transact-SQL). Zulässige Werte sind „0“ (Standard), „1“, „2“ usw. |
Nein |
| rejectType | Gibt an, ob die rejectValue-Option als Literalwert oder Prozentsatz angegeben ist. Zulässige Werte sind Value (Standard) und Percentage. |
Nein |
| rejectSampleValue | Gibt die Anzahl von Zeilen an, die abgerufen werden, bevor PolyBase den Prozentsatz der abgelehnten Zeilen neu berechnet. Zulässige Werte sind „1“, „2“ usw. |
Ja, wenn für rejectType der Wert percentage festgelegt ist. |
| useTypeDefault | Gibt an, wie fehlende Werte in durch Trennzeichen getrennten Textdateien behandelt werden sollen, wenn PolyBase Daten aus der Textdatei abruft. Weitere Informationen zu dieser Eigenschaft finden Sie im Abschnitt zu Argumenten im Thema CREATE EXTERNAL FILE FORMAT (Transact-SQL)verwenden können. Zulässige Werte sind true und false (Standard). |
Nein |
Direktes Kopieren mithilfe von PolyBase
Azure Synapse Analytics PolyBase unterstützt direkt Azure Blob und Azure Data Lake Storage Gen2. Wenn Ihre Daten die in diesem Abschnitt beschriebenen Kriterien erfüllen, können Sie mithilfe von PolyBase direkt aus dem Quelldatenspeicher in Azure Synapse Analytics kopieren. Andernfalls können Sie das gestaffelte Kopieren mit PolyBase verwenden.
Tipp
Weitere Informationen zum effizienten Kopieren von Daten in Azure Synapse Analytics finden Sie unter Bei Verwendung von Data Lake Store mit Azure Synapse Analytics können mit Azure Data Factory noch einfacher Erkenntnisse aus Daten gewonnen werden.
Falls die Anforderungen nicht erfüllt werden, überprüft der Dienst die Einstellungen und greift bei der Datenverschiebung automatisch auf den BULKINSERT-Mechanismus zurück.
Der mit der Quelle verknüpfte Dienst verfügt über die folgenden Typen und Authentifizierungsmethoden:
Unterstützter Quelldatenspeichertyp Unterstützter Quellauthentifizierungstyp Azure-Blob Kontoschlüsselauthentifizierung, Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität Azure Data Lake Storage Gen2 Kontoschlüsselauthentifizierung, Authentifizierung mit einer systemseitig zugewiesenen verwalteten Identität Wichtig
- Wenn Sie die Authentifizierung per verwalteter Identität für den mit dem Speicher verknüpften Dienst verwenden, machen Sie sich jeweils mit den erforderlichen Konfigurationen für Azure Blob und Azure Data Lake Storage Gen2 vertraut.
- Wenn Ihre Azure Storage-Instanz mit einem VNET-Dienstendpunkt konfiguriert ist, müssen Sie die Authentifizierung per verwalteter Identität mit für das Speicherkonto aktivierter Option „Vertrauenswürdigen Microsoft-Diensten den Zugriff auf dieses Speicherkonto erlauben“ verwenden. Informationen hierzu finden Sie unter Auswirkungen der Verwendung von VNET-Dienstendpunkten mit Azure Storage.
Das Quelldatenformat lautet Parquet, ORC oder Durch Trennzeichen getrennter Text – mit den folgenden Konfigurationen:
- Der Ordnerpfad enthält keinen Platzhalterfilter.
- Der Dateiname wurde entweder nicht angegeben oder verweist auf eine einzelne Datei. Wenn Sie in der Kopieraktivität einen Platzhalter-Dateinamen angeben, kann dies nur
*oder*.*sein. rowDelimiterentspricht Standard, \n, \r\n oder \r.nullValuewird als Standardwert übernommen oder ist auf eine leere Zeichenfolge („“) festgelegt, undtreatEmptyAsNullwird als Standardwert übernommen oder ist auf „true“ festgelegt.encodingNamewird als Standardwert übernommen oder ist auf utf-8 festgelegt.quoteChar,escapeCharundskipLineCountwurden nicht angegeben. PolyBase unterstützt das Überspringen der Kopfzeile, dies kann alsfirstRowAsHeaderkonfiguriert werden.compressionkann auf keine Komprimierung,GZipoder Deflate (Verkleinern) festgelegt werden.
Wenn es sich bei der Quelle um einen Ordner handelt, muss
recursivein der Kopieraktivität auf „true“ festgelegt werden.wildcardFolderPath,wildcardFilename,modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscoveryundadditionalColumnswerden nicht angegeben.
Hinweis
Wenn es sich bei der Quelle um einen Ordner handelt, beachten Sie, dass PolyBase Dateien aus dem Ordner und seinen Unterordnern und keine Daten aus Dateien abruft, bei denen der Dateiname mit einem Unterstrich (_) oder einem Punkt (.) beginnt, wie hier dokumentiert – LOCATION-Argument.
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
}
}
]
Gestaffeltes Kopieren mit PolyBase
Wenn Ihre Quelldaten nicht nativ mit PolyBase kompatibel sind, können Sie die Daten über eine zwischengeschaltete Azure Blob- oder Azure Data Lake Storage Gen2-Instanz mit Staging kopieren (es kann nicht Azure Storage Premium sein). In diesem Fall konvertiert der Dienst die Daten automatisch, damit das Datenformat den Anforderungen von PolyBase entspricht. Anschließend wird PolyBase aufgerufen, um die Daten in Azure Synapse Analytics zu laden. Abschließend werden Sie die temporären Daten im Speicher bereinigt. Ausführliche Informationen zum Kopieren von Daten mithilfe von Staging finden Sie unter Gestaffeltes Kopieren.
Um dieses Feature verwenden zu können, erstellen Sie einen mit Azure Blob Storage verknüpften Dienst oder einen mit Azure Data Lake Storage Gen2 verknüpften Dienst mit Authentifizierung per Kontoschlüssel oder verwalteter Identität, der auf das Azure Storage-Konto als Zwischenspeicher verweist.
Wichtig
- Wenn Sie die Authentifizierung per verwalteter Identität für den verknüpften Stagingdienst verwenden, machen Sie sich jeweils mit den erforderlichen Konfigurationen für Azure Blob und Azure Data Lake Storage Gen2 vertraut. Zudem müssen Sie Ihrer verwalteten Identität des Azure Synapse Analytics-Arbeitsbereichs in Ihrem Staging-Azure Blob Storage- oder Azure Data Lake Storage Gen2-Konto Berechtigungen erteilen. Informationen dazu, wie Sie diese Berechtigung zuweisen, finden Sie unter: Erteilen von Berechtigungen für die verwaltete Identität eines Arbeitsbereichs.
- Wenn Ihre Azure Storage-Staginginstanz mit einem VNET-Dienstendpunkt konfiguriert ist, müssen Sie die Authentifizierung per verwalteter Identität mit für das Speicherkonto aktivierter Option „Vertrauenswürdigen Microsoft-Diensten den Zugriff auf dieses Speicherkonto erlauben“ verwenden. Informationen hierzu finden Sie unter Auswirkungen der Verwendung von VNET-Dienstendpunkten mit Azure Storage.
Wichtig
Wenn Ihre Azure Storage-Staginginstanz mit verwaltetem privatem Endpunkt konfiguriert und die Speicherfirewall aktiviert ist, müssen Sie die Authentifizierung per verwalteter Identität verwenden und dem Speicherblob-Datenleser Berechtigungen für die Synapse-SQL Server-Instanz gewähren, um sicherzustellen, dass er während des Ladens mit PolyBase auf die bereitgestellten Dateien zugreifen kann.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Bewährte Methoden für die Verwendung von PolyBase
Die folgenden Abschnitte enthalten bewährte Methoden zusätzlich zu den in Bewährte Methoden für Azure Synapse Analytics aufgeführten Methoden.
Erforderliche Datenbankberechtigungen
Um PolyBase verwenden zu können, muss der Benutzer, der die Daten in Azure Synapse Analytics lädt, über die Berechtigung „CONTROL“ für die Zieldatenbank verfügen. Sie können dies beispielsweise erreichen, indem Sie diesen Benutzer als Mitglied der Rolle db_owner hinzufügen. Informationen hierzu finden Sie in der Übersicht über Azure Synapse Analytics.
Beschränkungen hinsichtlich Zeilengröße und Datentyp
In PolyBase sind Ladevorgänge auf Zeilen beschränkt, die kleiner als 1 MB sind. Die Anwendung kann nicht für das Laden von VARCHR(MAX), NVARCHAR(MAX) oder VARBINARY(MAX) genutzt werden. Weitere Informationen finden Sie unter Kapazitätsgrenzen in Azure Synapse Analytics.
Wenn die Quelldaten Zeilen enthalten, die größer als 1 MB sind, empfiehlt es sich, die Quelltabellen vertikal in mehrere kleine Tabellen zu teilen. Stellen Sie sicher, dass die längste Zeile den Grenzwert nicht überschreitet. Die kleineren Tabellen können dann mit PolyBase geladen und in Azure Synapse Analytics zusammengeführt werden.
Alternativ können Sie für Daten mit breiten Spalten dieser Art eine andere Anwendung als PolyBase nutzen, um die Daten zu laden. Deaktivieren Sie hierzu die Einstellung „allow PolyBase“.
Azure Synapse Analytics-Ressourcenklasse
Um den optimalen Durchsatz zu erzielen, sollten Sie dem Benutzer, der die Daten über PolyBase in Azure Synapse Analytics lädt, eine größere Ressourcenklasse zuweisen.
Problembehandlung in PolyBase
Laden in die Spalte „Decimal“
Wenn Ihre Quelldaten im Textformat vorliegen oder sich in anderen nicht mit PolyBase kompatiblen Speichern befinden (unter Verwendung von gestaffeltem Kopieren und PolyBase) und einen leeren Wert enthalten, der in die Spalte „Decimal“ von Azure Synapse Analytics geladen werden soll, erhalten Sie möglicherweise folgende Fehlermeldung:
ErrorCode=FailedDbOperation, ......HadoopSqlException: Error converting data type VARCHAR to DECIMAL.....Detailed Message=Empty string can't be converted to DECIMAL.....
Die Lösung besteht darin, die Option „Use type default“ in der Senke der Kopieraktivität unter den > PolyBase-Einstellungen zu deaktivieren (Festlegung auf „false“). „USE_TYPE_DEFAULT“ ist eine native PolyBase-Konfiguration, mit der die Behandlung von fehlenden Werten in durch Trennzeichen getrennten Textdateien angegeben wird, wenn PolyBase Daten aus der Textdatei abruft.
Überprüfen der tableName-Eigenschaft in Azure Synapse Analytics
Die folgende Tabelle enthält Beispiele zum Angeben der tableName-Eigenschaft im JSON-Dataset. Es zeigt verschiedene Kombinationen von Schema und Tabellennamen.
| Datenbankschema | Tabellenname | JSON-Eigenschaft tableName |
|---|---|---|
| dbo | MyTable | MyTable oder dbo.MyTable oder [dbo].[MyTable] |
| dbo1 | MyTable | dbo1.MyTable oder [dbo1].[MyTable] |
| dbo | My.Table | [My.Table] oder [dbo].[My.Table] |
| dbo1 | My.Table | [dbo1].[My.Table] |
Sollte der folgende Fehler auftreten, liegt dies unter Umständen am Wert für die tableName-Eigenschaft. Informationen zur korrekten Angabe von Werten für die JSON-Eigenschaft tableName finden Sie in der Tabelle oben.
Type=System.Data.SqlClient.SqlException,Message=Invalid object name 'stg.Account_test'.,Source=.Net SqlClient Data Provider
Spalten mit Standardwerten
Das PolyBase-Feature akzeptiert aktuell lediglich dieselbe Anzahl von Spalten wie in der Zieltabelle. Beispiel: Sie verfügen über eine Tabelle mit vier Spalten, von denen eine mit einem Standardwert definiert ist. Die Eingabedaten müssen weiterhin vier Spalten aufweisen. Bei Bereitstellung eines Eingabedatasets mit drei Spalten tritt ein Fehler wie der folgende auf:
All columns of the table must be specified in the INSERT BULK statement.
Der NULL-Wert ist eine Sonderform des Standardwerts. Wenn die Spalte NULL-Werte zulässt, können die Eingabedaten im Blob für diese Spalte leer sein. Sie dürfen im Eingabedataset aber nicht fehlen. PolyBase fügt für fehlende Daten in Azure Synapse Analytics einen NULL-Wert ein.
Fehler beim Zugriff auf externe Dateien
Wenn Sie die folgende Fehlermeldung erhalten, stellen Sie sicher, dass Sie die Authentifizierung mit verwalteter Identität verwenden und der verwalteten Identität des Azure Synapse-Arbeitsbereichs Speicherblob-Datenleser-Berechtigungen erteilt wurden.
Job failed due to reason: at Sink '[SinkName]': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist
Weitere Informationen finden Sie unter Gewähren von Berechtigungen für die verwaltete Identität nach der Erstellung eines Arbeitsbereichs.
Eigenschaften von Mapping Data Flow
Beim Transformieren von Daten im Zuordnungsdatenfluss können Sie Tabellen in Azure Synapse Analytics lesen und in diese schreiben. Weitere Informationen finden Sie unter Quellentransformation und Senkentransformation in Zuordnungsdatenflüssen.
Quellentransformation
Spezifische Einstellungen für Azure Synapse Analytics sind auf der Registerkarte Quellenoptionen der Quellentransformation verfügbar.
Eingabe: Wählen Sie aus, ob Sie Ihre Quelle auf eine Tabelle verweisen (Äquivalent von Select * from <table-name>) oder eine benutzerdefinierte SQL-Abfrage eingeben.
Staging aktivieren: Es wird dringend empfohlen, diese Option für Produktionsworkloads mit Azure Synapse Analytics-Quellen zu verwenden. Wenn Sie eine Datenflussaktivität mit Azure Synapse Analytics-Quellen aus einer Pipeline ausführen, werden Sie zur Eingabe eines Speicherkontos am Stagingort aufgefordert und verwenden dieses für das gestaffelte Laden von Daten. Es ist der schnellste Mechanismus zum Laden von Daten aus Azure Synapse Analytics.
- Wenn Sie die Authentifizierung per verwalteter Identität für den mit dem Speicher verknüpften Dienst verwenden, machen Sie sich jeweils mit den erforderlichen Konfigurationen für Azure Blob und Azure Data Lake Storage Gen2 vertraut.
- Wenn Ihre Azure Storage-Instanz mit einem VNET-Dienstendpunkt konfiguriert ist, müssen Sie die Authentifizierung per verwalteter Identität mit für das Speicherkonto aktivierter Option „Vertrauenswürdigen Microsoft-Diensten den Zugriff auf dieses Speicherkonto erlauben“ verwenden. Informationen hierzu finden Sie unter Auswirkungen der Verwendung von VNET-Dienstendpunkten mit Azure Storage.
- Wenn Sie den serverlosen Azure Synapse-SQL-Pool als Quelle verwenden, wird das Aktivieren des Stagings nicht unterstützt.
Query (Abfrage): Wenn Sie im Eingabefeld „Abfrage“ auswählen, geben Sie eine SQL-Abfrage für die Quelle ein. Diese Einstellung überschreibt jede Tabelle, die Sie im Dataset ausgewählt haben. Order By-Klauseln werden hier nicht unterstützt. Sie können aber eine vollständige SELECT FROM-Anweisung festlegen. Sie können auch benutzerdefinierte Tabellenfunktionen verwenden. select * from udfGetData() ist eine benutzerdefinierte Funktion in SQL, die eine Tabelle zurückgibt. Diese Abfrage generiert eine Quelltabelle, die Sie in Ihrem Datenfluss verwenden können. Die Verwendung von Abfragen stellt auch eine gute Möglichkeit dar, um die Zeilen für Tests oder Suchvorgänge zu verringern.
SQL-Beispiel: Select * from MyTable where customerId > 1000 and customerId < 2000
Batchgröße: Geben Sie eine Batchgröße ein, um große Datenmengen in Leseblöcke zu segmentieren. In Datenflüssen wird diese Einstellung verwendet, um die Spark-Zwischenspeicherung in Spalten festzulegen. Dies ist ein Optionsfeld, in dem Spark-Standardwerte verwendet werden, wenn kein Wert eingegeben wurde.
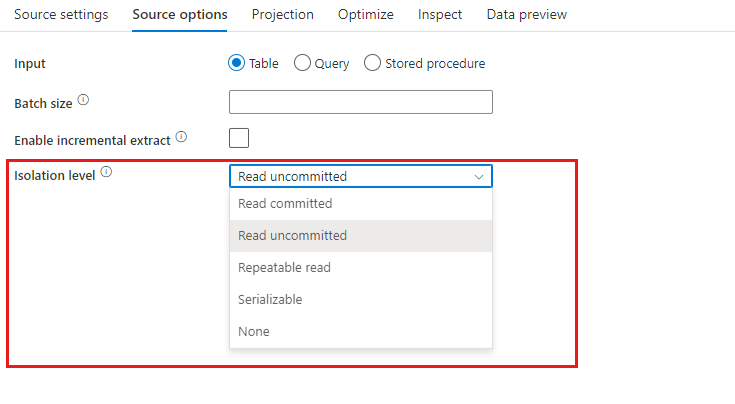
Isolationsstufe: Der Standardwert für SQL-Quellen in Mapping Data Flow lautet „Lesen nicht zugesichert“. Sie können die Isolationsstufe hier in einen der folgenden Werte ändern:
- Lesen zugesichert
- Lesen nicht zugesichert
- Wiederholbarer Lesevorgang
- Serialisierbar
- Keine (Isolationsstufe ignorieren)
Senkentransformation
Spezifische Einstellungen für Azure Synapse Analytics sind auf der Registerkarte Einstellungen der Senkentransformation verfügbar.
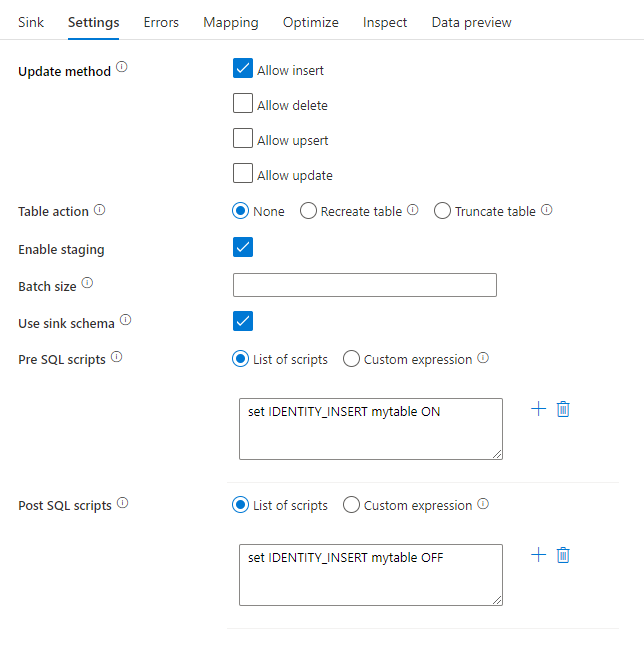
Updatemethode: Bestimmt, welche Vorgänge für das Datenbankziel zulässig sind. Standardmäßig sind lediglich Einfügevorgänge zulässig. Wenn Sie für Zeilen Update-, Upsert- oder Löschvorgänge verwenden möchten, fügen Sie zunächst eine Transformation zur Änderung von Zeilen hinzu, um Zeilen für diese Aktionen zu kennzeichnen. Für Update-, Upsert- und Löschvorgänge muss mindestens eine Schlüsselspalte festgelegt werden, um die Zeile zu bestimmen, die geändert werden soll.
Tabellenaktion: Bestimmt, ob die Zieltabelle vor dem Schreiben neu erstellt werden soll oder alle Zeilen aus der Zieltabelle entfernt werden sollen.
- Keine: Es wird keine Aktion an der Tabelle vorgenommen.
- Neu erstellen: Die Tabelle wird gelöscht und neu erstellt. Erforderlich, wenn eine neue Tabelle dynamisch erstellt wird.
- Abschneiden: Alle Zeilen werden aus der Zieltabelle entfernt.
Staging aktivieren: Dies ermöglicht das Laden in Azure Synapse Analytics-SQL-Pools mithilfe des Kopierbefehls, was für die meisten Synapse-Senken empfohlen wird. Der Stagingspeicher wird unter Datenflussaktivität in Azure Data Factory konfiguriert.
- Wenn Sie die Authentifizierung per verwalteter Identität für den mit dem Speicher verknüpften Dienst verwenden, machen Sie sich jeweils mit den erforderlichen Konfigurationen für Azure Blob und Azure Data Lake Storage Gen2 vertraut.
- Wenn Ihre Azure Storage-Instanz mit einem VNET-Dienstendpunkt konfiguriert ist, müssen Sie die Authentifizierung per verwalteter Identität mit für das Speicherkonto aktivierter Option „Vertrauenswürdigen Microsoft-Diensten den Zugriff auf dieses Speicherkonto erlauben“ verwenden. Informationen hierzu finden Sie unter Auswirkungen der Verwendung von VNET-Dienstendpunkten mit Azure Storage.
Batchgröße: Steuert, wie viele Zeilen in die einzelnen Buckets geschrieben werden. Durch größere Batches werden zwar Komprimierung und Arbeitsspeicheroptimierung verbessert, beim Zwischenspeichern von Daten besteht aber die Gefahr, dass Ausnahmen wegen unzureichenden Arbeitsspeichers auftreten.
Sinkschema verwenden: Standardmäßig wird eine temporäre Tabelle unter dem Sinkschema als Staging erstellt. Alternativ können Sie die Option Sinkschema verwenden deaktivieren, und stattdessen einen Schemanamen in Benutzer-DB-Schema verwenden angeben, unter dem Data Factory eine Stagingtabelle erstellt, um vorgelagerte Daten zu laden und diese automatisch nach Abschluss zu löschen. Stellen Sie sicher, dass Sie Tabellenberechtigungen in der Datenbank erstellen und die Berechtigung für das Schema ändern.

Pre- und Post SQL-Skripts: Geben Sie mehrzeilige SQL-Skripts ein, die ausgeführt werden, bevor Daten in die Senkendatenbank geschrieben werden (Vorverarbeitung) und danach (Nachbearbeitung).
Tipp
- Es wird empfohlen, einzelne Batchskripts mit mehreren Befehlen in mehrere Batches aufzuteilen.
- In einem Batch können nur DDL- (Data Definition Language) und DML-Anweisungen (Data Manipulation Language) ausgeführt werden, die eine einfache Updatezählung zurückgeben. Weitere Informationen finden Sie unter Ausführen von Batchvorgängen.
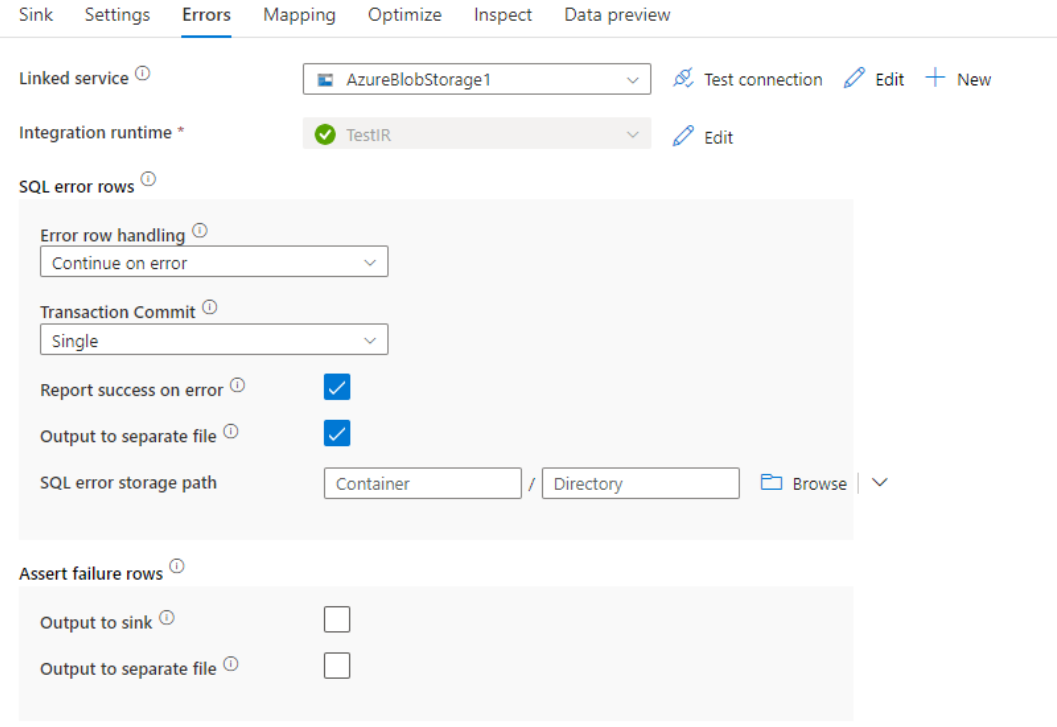
Fehlerzeilenbehandlung
Beim Schreiben in Azure Synapse Analytics können aufgrund von Einschränkungen durch das Ziel Fehler bei bestimmten Datenzeilen auftreten. Häufige Fehler sind z. B. folgende:
- Zeichenfolgen- oder Binärdaten würden in der Tabelle abgeschnitten.
- Der Wert NULL kann nicht in die Spalte einfügt werden.
- Fehler beim Konvertieren des Werts in den Datentyp
Standardmäßig scheitert eine Datenflussausführung beim ersten erhaltenen Fehler. Sie können die Option Bei Fehler fortsetzen auswählen, die einen Abschluss des Datenflusses auch dann ermöglicht, wenn einzelne Zeilen Fehler aufweisen. Der Dienst bietet Ihnen verschiedene Optionen, mit denen Sie diese Fehlerzeilen behandeln können.
Transaktionscommit: Wählen Sie aus, ob Ihre Daten in einer einzelnen Transaktion oder in Batches geschrieben werden. Eine einzelne Transaktion führt zu einer besseren Leistung, und es werden keine geschriebenen Daten für andere sichtbar gemacht, bis die Transaktion abgeschlossen ist. Batchtransaktionen haben eine schlechtere Leistung, können aber für große Datasets verwendet werden.
Abgelehnte Daten ausgeben: Wenn diese Option aktiviert ist, können Sie die Fehlerzeilen in eine CSV-Datei in Azure Blob Storage oder ein Azure Data Lake Storage Gen2-Konto Ihrer Wahl ausgeben. Dadurch werden die Fehlerzeilen mit drei zusätzlichen Spalten geschrieben: dem SQL-Vorgang wie INSERT oder UPDATE, dem Datenfluss-Fehlercode und der Fehlermeldung für die Zeile.
Bericht bei Fehler als erfolgreich markieren: Wenn diese Option aktiviert ist, wird der Datenfluss als erfolgreich markiert, auch wenn Fehlerzeilen gefunden werden.
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Eigenschaften der GetMetadata-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter GetMetadata-Aktivität.
Datentypzuordnung für Azure Synapse Analytics
Beim Kopieren von Daten aus bzw. nach Azure Synapse Analytics werden die folgenden Zuordnungen von Azure Synapse Analytics-Datentypen zu Azure Data Factory-Zwischendatentypen verwendet. Diese Zuordnungen werden auch beim Kopieren von Daten von oder nach Azure Synapse Analytics mithilfe von Synapse-Pipelines verwendet, da Pipelines auch Azure Data Factory innerhalb von Azure Synapse implementieren. Unter Schema- und Datentypzuordnungen erfahren Sie, wie Sie Aktivitätszuordnungen für Quellschema und Datentyp in die Senke kopieren.
Tipp
Im Artikel Tabellendatentypen in Azure Synapse Analytics finden Sie Informationen zu den von Azure Synapse Analytics unterstützten Datentypen und zu den Problemumgehungen für Datentypen, die nicht unterstützt werden.
| Datentyp von Azure Synapse Analytics | Data Factory-Zwischendatentyp |
|---|---|
| BIGINT | Int64 |
| BINARY | Byte[] |
| bit | Boolean |
| char | String, Char[] |
| date | Datetime |
| Datetime | Datetime |
| datetime2 | Datetime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM attribute (varbinary(max)) | Byte[] |
| Float | Double |
| image | Byte[] |
| INT | Int32 |
| money | Decimal |
| NCHAR | String, Char[] |
| NUMERIC | Decimal |
| NVARCHAR | String, Char[] |
| real | Single |
| rowversion | Byte[] |
| smalldatetime | Datetime |
| SMALLINT | Int16 |
| SMALLMONEY | Decimal |
| time | TimeSpan |
| TINYINT | Byte |
| UNIQUEIDENTIFIER | Guid |
| varbinary | Byte[] |
| varchar | String, Char[] |
Upgraden der Azure Synapse Analytics-Version
Um ein Upgrade für die Azure Synapse Analytics-Version durchzuführen, wählen Sie auf der Seite Verknüpften Dienst bearbeiten unter Version die Option Empfohlen aus, und konfigurieren Sie den verknüpften Dienst anhand des Abschnitts Eigenschaften des verknüpften Diensts für die empfohlene Version.
Unterschiede zwischen der empfohlenen Version und der Legacyversion
In der nachstehenden Tabelle sind die Unterschiede zwischen Azure Synapse Analytics unter Verwendung der empfohlenen Version und der Legacyversion dargestellt.
| Empfohlene Version | Legacyversion |
|---|---|
Unterstützung von TLS 1.3 über encrypt als strict. |
TLS 1.3 wird nicht unterstützt. |
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quellen und Senken für die Kopieraktivität unterstützt werden, finden Sie unter Unterstützte Datenspeicher und Formate.