Améliorer la qualité de l’application RAG
Cet article fournit une vue d’ensemble de la façon dont vous pouvez affiner chaque composant pour améliorer la qualité de votre application de génération augmentée de récupération (RAG).
Il existe de nombreux « boutons » à régler pour chaque point du pipeline de données hors connexion et de la chaîne RAG en ligne. Bien qu’il y en ait énormément, l’article se concentre sur les boutons les plus importants, qui ont le plus d’impact sur la qualité de votre application RAG. Databricks recommande de commencer par ces boutons.
Considération des deux types de qualité
D’un point de vue conceptuel, il faut considérer les boutons de qualité RAG à travers l’objectif des deux principaux types de problèmes liés à la qualité :
Qualité de récupération : récupérez-vous les informations les plus pertinentes pour telle ou telle requête de récupération ?
Il est difficile de générer une sortie RAG de haute qualité si le contexte fourni au LLM manque d’informations importantes ou contient des informations superflues.
Qualité de génération : étant donné les informations récupérées et la requête utilisateur d’origine, le LLM génère-t-il la réponse la plus précise, cohérente et utile possible ?
Les problèmes présentés ici peuvent se manifester sous forme d’altérations, de sortie incohérente ou d’incapacité de traiter directement la requête de l’utilisateur.
Les applications RAG présentent deux composants qui peuvent être itérés pour relever les défis que pose la qualité : le pipeline de données et la chaîne. On peut être tenté d’imaginer une distinction nette entre les problèmes de récupération (mettre simplement à jour le pipeline de données) et les problèmes de génération (mettre à jour la chaîne RAG). Toutefois, la réalité est bien plus complexe. La qualité de récupération peut être influencée par le pipeline de données (par exemple, la stratégie d’analyse ou de segmentation, la stratégie de métadonnées, le modèle d’incorporation) et par la chaîne RAG (par exemple, transformation de requête utilisateur, nombre de blocs récupérés, nouveau classement). De même, la qualité de la génération sera toujours affectée par une mauvaise récupération (par exemple, des informations non pertinentes ou manquantes affectant la sortie du modèle).
Cette influence réciproque appuie la nécessité d’une approche holistique de l’amélioration de la qualité de RAG. En comprenant les composants à modifier dans le pipeline de données et la chaîne RAG, et en expliquant comment ces modifications affectent la solution globale, vous pouvez effectuer des mises à jour ciblées pour améliorer la qualité de sortie RAG.
Considérations relatives à la qualité du pipeline de données
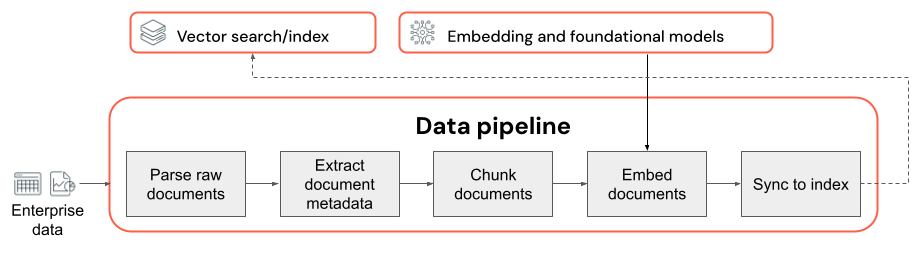
Considérations principales relatives au pipeline de données :
- Composition du corpus de données d’entrée.
- Comment les données brutes sont extraites et transformées en format utilisable (par exemple, analyse d’un document PDF).
- Comment les documents sont divisés en blocs plus petits et comment ces blocs sont mis en forme (par exemple, stratégie de segmentation et taille de bloc).
- Les métadonnées (telles que le titre de la section ou du document) ont été extraites sur chaque document et/ou segment. Comment ces métadonnées sont incluses (ou non) dans chaque segment.
- Modèle d’incorporation utilisé pour convertir du texte en représentations vectorielles pour la recherche de similarité.
Chaîne RAG
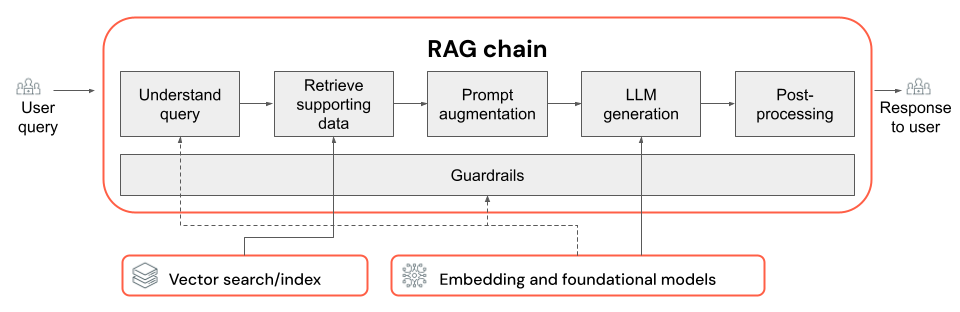
- Choix de LLM et de ses paramètres (par exemple, jetons de température et de maximum).
- Paramètres de récupération (par exemple, le nombre de blocs ou de documents récupérés).
- Approche de récupération (par exemple, mot clé, hybride et recherche sémantique réécriture de la requête de l’utilisateur, transformation d’une requête utilisateur en filtres ou nouveau classement).
- Comment mettre en forme l’invite avec le contexte récupéré pour guider le LLM vers une sortie de qualité.