Améliorer la qualité de la chaîne RAG
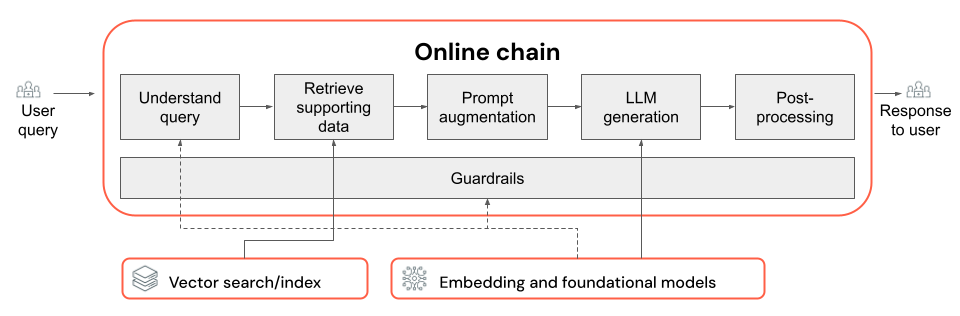
Cet article explique comment améliorer la qualité de l’application RAG à l’aide de composants de la chaîne RAG.
La chaîne RAG prend une requête utilisateur comme entrée, récupère les informations pertinentes en fonction de cette requête, et génère une réponse appropriée reposant sur les données récupérées. Bien que les étapes exactes d’une chaîne RAG puissent varier considérablement en fonction du cas d’usage et des exigences, les composants clés à prendre en compte lors de la création de votre chaîne RAG sont les suivants :
- Compréhension des requêtes : analyse et transformation des requêtes utilisateur pour mieux représenter l’intention et extraire les informations pertinentes, telles que des filtres ou des mots clés, afin d’améliorer le processus de récupération.
- Récupération : recherche des segments d’informations les plus pertinents en fonction d’une requête de récupération. Dans le cas des données non structurées, cela implique généralement une recherche sémantique, une recherche de mots clés, ou une combinaison des deux.
- Augmentation de prompt : combinaison d’une requête utilisateur avec des informations récupérées et des instructions pour guider le LLM vers la génération de réponses de haute qualité.
- LLM : sélection du modèle (et des paramètres de modèle) le plus approprié pour votre application afin d’optimiser/équilibrer les performances, la latence et le coût.
- Post-traitement et garde-fous : application d’étapes de traitement et de mesures de sécurité supplémentaires afin de garantir que les réponses générées par le LLM ne sont pas hors sujet, sont cohérentes du point de vue des faits, et respectent des directives ou des contraintes spécifiques.
Implémenter et évaluer des correctifs de manière itérative montre comment itérer sur les composants d’une chaîne.
Compréhension des requêtes
L’utilisation de la requête utilisateur directement en tant que requête de récupération peut fonctionner pour certaines requêtes. Toutefois, il est généralement préférable de reformuler la requête avant l’étape de récupération. La compréhension des requêtes comprend une étape (ou une série d’étapes) au début d’une chaîne afin d’analyser et de transformer les requêtes utilisateur pour mieux représenter l’intention, extraire les informations pertinentes et aider au processus de récupération suivant. Les approches de transformation d’une requête utilisateur pour améliorer la récupération sont les suivantes :
Réécriture de requête : la réécriture de requête implique la traduction d’une requête utilisateur en une ou plusieurs requêtes qui représentent mieux l’intention d’origine. L’objectif est de reformuler la requête d’une manière qui augmente la probabilité que l’étape de récupération trouve les documents les plus pertinents. Cela peut être particulièrement utile lorsque vous traitez des requêtes complexes ou ambiguës qui peuvent ne pas correspondre directement à la terminologie utilisée dans les documents de récupération.
Exemples :
- Paraphrase de l’historique des conversations dans une conversation multitour
- Correction des erreurs d’orthographe dans la requête de l’utilisateur
- Remplacement de mots ou d’expressions dans la requête utilisateur par des synonymes pour capturer un large éventail de documents pertinents
Important
La réécriture de requête doit être effectuée conjointement avec les modifications apportées au composant de récupération.
Extraction de filtre : dans certains cas, les requêtes utilisateur peuvent contenir des filtres ou des critères spécifiques qui peuvent être utilisés pour affiner les résultats de la recherche. L’extraction de filtre implique l’identification et l’extraction de ces filtres à partir de la requête, et leur transmission à l’étape de récupération en tant que paramètres supplémentaires. Cela peut améliorer la pertinence des documents récupérés en mettant l’accent sur des sous-ensembles spécifiques des données disponibles.
Exemples :
- Extraction de périodes spécifiques mentionnées dans la requête, telles que « articles des 6 derniers mois » ou « rapports de 2023 ».
- Identification des mentions de produits, de services ou de catégories spécifiques dans la requête, telles que « Services professionnels Databricks » ou « ordinateurs portables ».
- Extraction d’entités géographiques à partir de la requête, telles que les noms de villes ou les codes de pays.
Remarque
L’extraction de filtre doit être effectuée conjointement avec les modifications apportées aux composants du pipeline de données d’extraction de métadonnées et de la chaîne de récupération. L’étape d’extraction des métadonnées doit veiller à ce que les champs de métadonnées appropriés soient disponibles pour chaque document/segment, et l’étape de récupération doit être implémentée de façon à accepter et à appliquer des filtres extraits.
Outre la réécriture de requête et l’extraction de filtre, une autre considération importante dans la compréhension des requêtes est le fait de savoir s’il faut utiliser un seul ou plusieurs appels LLM. Bien que l’utilisation d’un seul appel avec un prompt soigneusement conçu puisse être efficace, il existe des cas où la décomposition du processus de compréhension de requête en plusieurs appels LLM peut entraîner de meilleurs résultats. Ceci est d’ailleurs une règle générale applicable lorsque vous essayez d’implémenter plusieurs étapes logiques complexes dans un seul prompt.
Par exemple, vous pouvez utiliser un appel LLM pour classifier l’intention de requête, un autre pour extraire les entités pertinentes, et un troisième pour réécrire la requête en fonction des informations extraites. Bien que cette approche puisse ajouter une certaine latence au processus global, elle peut offrir un contrôle plus précis et améliorer potentiellement la qualité des documents récupérés.
Compréhension des requêtes multi-étape pour un bot de support
Voici comment un composant de compréhension des requêtes multi-étape peut rechercher un bot de support client :
- Classification des intentions : utilisez un LLM pour classifier la requête de l’utilisateur en catégories prédéfinies, telles que « informations sur le produit », « résolution des problèmes » ou « gestion des comptes ».
- Extraction d’entité : en fonction de l’intention identifiée, utilisez un autre appel LLM pour extraire les entités pertinentes à partir de la requête, telles que les noms de produits, les erreurs signalées ou les numéros de compte.
- Réécriture de requête : utilisez l’intention et les entités extraites pour réécrire la requête d’origine dans un format plus spécifique et ciblé, par exemple, « Le déploiement de ma chaîne RAG sur Model Serving échoue, je vois l’erreur suivante... ».
Récupération
Le composant de récupération de la chaîne RAG est responsable de la recherche des segments d’informations les plus pertinents pour une requête de récupération. Dans le contexte de données non structurées, la récupération implique généralement une recherche sémantique, une recherche de mots clés ou un filtrage des métadonnées, ou une combinaison de ces trois opérations. Le choix de la stratégie de récupération dépend des exigences spécifiques de votre application, de la nature des données et des types de requêtes que vous prévoyez de gérer. Comparons ces options :
- Recherche sémantique : la recherche sémantique utilise un modèle d’incorporations pour convertir chaque segment de texte en une représentation vectorielle qui capture sa signification sémantique. En comparant la représentation vectorielle de la requête de récupération avec les représentations vectorielles des segments, la recherche sémantique peut récupérer des documents conceptuellement similaires, même s’ils ne contiennent pas les mots clés exacts de la requête.
- Recherche de mots clés : la recherche de mots clés détermine la pertinence des documents en analysant la fréquence et la distribution des mots partagés entre la requête de récupération et les documents indexés. Plus les mêmes mots apparaissent souvent à la fois dans la requête et dans un document, plus le score de pertinence attribué à ce document est élevé.
- Recherche hybride : la recherche hybride combine les points forts de la recherche sémantique et de la recherche de mots clés en utilisant un processus de récupération en deux étapes. Tout d’abord, elle effectue une recherche sémantique pour récupérer un ensemble de documents conceptuellement pertinents. Ensuite, elle applique la recherche de mots clés sur cet ensemble réduit pour affiner davantage les résultats en fonction des correspondances exactes des mots clés. Pour finir, elle combine les scores des deux étapes pour classer les documents.
Comparer les stratégies de récupération
Le tableau suivant compare chacune de ces stratégies de récupération :
| Recherche sémantique | Recherche de mots clés | Recherche hybride | |
|---|---|---|---|
| Explication simple | Si les mêmes concepts apparaissent dans la requête et dans un document potentiel, ils sont pertinents. | Si les mêmes mots apparaissent dans la requête et dans un document potentiel, ils sont pertinents. Plus il y a de mots de la requête dans le document, plus ce document est pertinent. | Exécute une recherche sémantique ET une recherche par mot clé, puis combine les résultats. |
| Exemple de cas d’usage | Support client où les requêtes utilisateur sont différentes des mots employés dans les manuels de produit. Exemple : « comment faire pour allumer mon téléphone ? » alors que la section du manuel s’intitule « mise sous tension ». | Support client où les requêtes contiennent des termes techniques spécifiques et non descriptifs. Exemple : « Que fait le modèle HD7-8D ? » | Requêtes de support client qui combinent des termes sémantiques et techniques. Exemple : « comment faire pour allumer mon HD7-8D ? » |
| Approches techniques | Utilise des incorporations pour représenter du texte dans un espace vectoriel continu, autorisant ainsi la recherche sémantique. | S’appuie sur des méthodes discrètes basées sur des jetons telles que bag-of-words, TF-IDF, BM25 pour la correspondance de mots clés. | Utilise une approche de reclassement pour combiner les résultats, telle que la fusion de classement réciproque ou un modèle de reclassement. |
| Strengths | Récupération d’informations contextuellement similaires à une requête, même si les mots exacts ne sont pas utilisés. | Scénarios nécessitant des correspondances de mots clés précises. Idéal pour des requêtes spécifiques axées sur des termes tels que des noms de produits. | Combine le meilleur des deux approches. |
Méthodes pour améliorer le processus de récupération
Outre ces stratégies de récupération de base, vous pouvez appliquer plusieurs techniques pour améliorer encore davantage le processus de récupération :
- Extension de requête : l’extension de requête peut aider à capturer un plus large éventail de documents pertinents en utilisant plusieurs variantes de la requête de récupération. Vous pouvez pour cela effectuer des recherches individuelles pour chaque requête étendue, ou utiliser une concaténation de toutes les requêtes de recherche étendues en une requête de récupération unique.
Remarque
L’extension de requête doit être effectuée conjointement avec les modifications apportées au composant de compréhension des requêtes (chaîne RAG). Les multiples variantes d’une requête de récupération sont généralement générées lors de cette étape.
- Reclassement : après avoir récupéré un ensemble initial de segments, appliquez des critères de classement supplémentaires (par exemple, trier en fonction du temps) ou un modèle de reclassement pour réordonner les résultats. Le reclassement peut aider à hiérarchiser les segments les plus pertinents pour une requête de récupération spécifique. La reclassement avec des modèles d’encodeurs croisés tels que mxbai-rerank et ColBERTv2 peut accroître les performances de récupération.
- Filtrage des métadonnées : utilisez des filtres de métadonnées extraits à partir de l’étape de compréhension des requêtes pour affiner l’espace de recherche en fonction de critères spécifiques. Les filtres de métadonnées peuvent inclure des attributs tels que le type de document, la date de création, l’auteur, ou des étiquettes propres au domaine. En combinant des filtres de métadonnées avec la recherche sémantique ou la recherche de mots clés, vous pouvez créer une récupération plus ciblée et efficace.
Remarque
Le filtrage des métadonnées doit être effectué conjointement avec les modifications apportées aux composants de compréhension des requêtes (chaîne RAG) et d’extraction de métadonnées (pipeline de données).
Augmentation de prompt
L’augmentation de prompt est l’étape où la requête utilisateur est combinée avec les informations récupérées et les instructions d’un modèle de prompt afin de guider le modèle de langage vers la génération de réponses de haute qualité. L’itération sur ce modèle pour optimiser le prompt fourni au LLM (autrement dit, l’ingénierie de prompt) est nécessaire afin de garantir que le modèle est guidé pour produire des réponses justes, ancrées et cohérentes.
Il existe des guides complets pour l’ingénierie de prompt, mais voici quelques considérations à prendre en compte lorsque vous effectuez une itération sur le modèle de prompt :
- Fournir des exemples
- Incluez des exemples de requêtes bien formées et de leurs réponses idéales correspondantes dans le modèle de prompt lui-même (apprentissage en quelques essais, ou few-shot learning). Cela aide le modèle à comprendre le format, le style et le contenu souhaités des réponses.
- Une façon utile de trouver de bons exemples consiste à identifier les types de requêtes avec lesquelles votre chaîne rencontre des difficultés. Créez des réponses standard pour ces requêtes, et incluez-les comme exemples dans le prompt.
- Vérifiez que les exemples que vous fournissez sont représentatifs des requêtes utilisateur que vous vous attendez à voir au moment de l’inférence. Visez à couvrir un large éventail de requêtes attendues, pour aider le modèle à mieux généraliser.
- Paramétriser votre modèle de prompt
- Concevez votre modèle de prompt de façon à ce qu’il soit flexible en le paramétrisant pour incorporer des informations supplémentaires au-delà des données récupérées et de la requête utilisateur. Il peut s’agir de variables telles que la date actuelle, le contexte utilisateur ou d’autres métadonnées pertinentes.
- L’injection de ces variables dans le prompt au moment de l’inférence peut générer des réponses plus personnalisées ou contextuelles.
- Penser aux prompts en chaîne de pensée
- Pour les requêtes complexes où les réponses directes ne sont pas facilement apparentes, pensez aux prompts en chaîne de pensée (ou CoT, Chain-of-Thought). Cette stratégie d’ingénierie de prompt décompose les questions complexes en étapes plus simples et séquentielles, guidant le LLM par le biais d’un processus de raisonnement logique.
- En invitant le modèle à « réfléchir au problème pas à pas », vous l’encouragez à fournir des réponses plus détaillées et raisonnées, ce qui peut être particulièrement efficace lors de la gestion des requêtes multi-étapes ou ouvertes.
- Le transfert de prompts entre modèles peut ne pas être possible
- Vous devez reconnaître le fait que le transfert de prompts entre différents modèles de langage ne s’effectue pas toujours de manière fluide. Chaque modèle a ses propres caractéristiques uniques, et un prompt qui fonctionne bien pour un modèle peut ne pas être aussi efficace pour un autre.
- Expérimentez avec différents formats et longueurs de prompts, consultez les guides en ligne (tels que OpenAI Cookbook et le livre de recettes anthropic), et soyez prêt à adapter et à affiner vos prompts lors du basculement d’un modèle à un autre.
LLM
Le composant de génération de la chaîne RAG prend le modèle de prompt augmenté de l’étape précédente et le transmet à un LLM. Lors de la sélection et de l’optimisation d’un LLM pour le composant de génération d’une chaîne RAG, tenez compte des facteurs suivants, qui sont tout aussi applicables aux autres étapes qui impliquent des appels LLM :
- Expérimentez avec différents modèles produits du commerce.
- Chaque modèle a ses propres propriétés, forces et faiblesses uniques. Certains modèles peuvent avoir une meilleure compréhension de certains domaines, ou offrir de meilleures performances sur des tâches spécifiques.
- Comme mentionné plus haut, gardez à l’esprit que le choix du modèle peut également influencer le processus d’ingénierie de prompt, car différents modèles peuvent répondre différemment aux mêmes prompts.
- Si plusieurs étapes de votre chaîne nécessitent un LLM, par exemple des appels de compréhension des requêtes en plus de l’étape de génération, envisagez d’utiliser différents modèles pour différentes étapes. Le recours à des modèles coûteux à usage général peut être superflu pour des tâches telles que la détermination de l’intention d’une requête utilisateur.
- Commencez petit et gravissez les échelons en fonction des besoins.
- Bien qu’il soit tentant de faire immédiatement appel aux modèles les plus puissants et capables disponibles (par exemple, GPT-4 ou Claude), il est souvent plus efficace de commencer par des modèles plus petits et plus légers.
- Dans de nombreux cas, de petites alternatives open source comme Llama 3 ou DBRX peuvent fournir des résultats satisfaisants à un coût moindre et avec des temps d’inférence plus rapides. Ces modèles peuvent être particulièrement efficaces pour les tâches qui ne nécessitent pas de raisonnement très complexe ou de connaissances du monde étendues.
- À mesure que vous développez et affinez votre chaîne RAG, évaluez en permanence les performances et les limitations de votre modèle choisi. Si vous constatez que le modèle rencontre des difficultés avec certains types de requêtes ou ne parvient pas à fournir des réponses suffisamment détaillées ou justes, envisagez d’effectuer un scale-up vers un modèle plus capable.
- Surveillez l’impact du changement de modèle sur les métriques clés telles que la qualité de la réponse, la latence et le coût, afin d’être certain d’atteindre le bon équilibre pour les exigences de votre cas d’usage spécifique.
- Optimisez les paramètres du modèle.
- Expérimentez avec différents paramètres pour trouver l’équilibre optimal entre la qualité de la réponse, la diversité et la cohérence. Par exemple, l’ajustement de la température peut contrôler le caractère aléatoire du texte généré, tandis que max_tokens peut limiter la longueur de la réponse.
- N’oubliez pas que les paramètres optimaux peuvent varier en fonction de la tâche, du prompt et du style de sortie souhaité. Testez et affinez ces paramètres de manière itérative en fonction de l’évaluation des réponses générées.
- Ajustement propre à la tâche
- À mesure que vous affinez les performances, pensez à ajuster les plus petits modèles pour des sous-tâches spécifiques au sein de votre chaîne RAG, telles que la compréhension des requêtes.
- En entraînant des modèles spécialisés pour des tâches spécifiques avec la chaîne RAG, vous pouvez potentiellement améliorer les performances globales, réduire la latence et diminuer les coûts d’inférence par rapport à l’utilisation d’un seul modèle volumineux pour toutes les tâches.
- Pré-entraînement continu
- Si votre application RAG traite d’un domaine spécialisé ou nécessite des connaissances qui ne sont pas bien représentées dans le LLM préentraîné, pensez à effectuer un pré-entraînement continu sur des données propres au domaine.
- Le pré-entraînement continu peut améliorer la compréhension par un modèle de la terminologie ou des concepts spécifiques propres à votre domaine. Cela peut ensuite réduire le besoin de recourir à une ingénierie de prompt étendue ou à des exemples few-shot.
Post-traitement et garde-fous
Une fois que le LLM a généré une réponse, il est souvent nécessaire d’appliquer des techniques de post-traitement ou des garde-fous pour s’assurer que la sortie répond aux exigences de format, de style et de contenu souhaitées. Ces étapes finales peuvent aider à maintenir la cohérence et la qualité parmi les réponses générées. Si vous implémentez un post-traitement et des garde-fous, tenez compte des éléments suivants :
- Application du format de sortie
- En fonction de votre cas d’usage, vous pouvez exiger que les réponses générées adhèrent à un format spécifique, tel qu’un modèle structuré ou un type de fichier particulier (par exemple, JSON, HTML, Markdown, etc.).
- Si une sortie structurée est requise, des bibliothèques telles que Instructor ou Outlines fournissent de bons points de départ pour implémenter ce type d’étape de validation.
- Lors du développement, prenez du temps pour veiller à ce que l’étape de post-traitement soit suffisamment flexible pour gérer les variantes dans les réponses générées tout en conservant le format requis.
- Maintien de la cohérence de style
- Si votre application RAG a des instructions de style spécifiques ou des exigences de ton (par exemple, ton formel ou informel, style concis ou détaillé), une étape de post-traitement peut vérifier et appliquer ces attributs de style à toutes les réponses générées.
- Filtres de contenu et garde-fous de sécurité
- En fonction de la nature de votre application RAG et des risques potentiels associés au contenu généré, il peut être important d’implémenter des filtres de contenu ou des garde-fous de sécurité afin d’empêcher la génération d’informations inappropriées, offensives ou dangereuses.
- Envisagez d’utiliser des modèles tels que Llama Guard ou des API spécifiquement conçues pour la sécurité et la modération du contenu, comme l’API de modération d’OpenAI, afin d’implémenter des garde-fous de sécurité.
- Gestion des hallucinations
- La défense contre les hallucinations peut également être implémentée en tant qu’étape de post-traitement. Cela peut impliquer le référencement croisé de la sortie générée avec des documents récupérés, ou l’utilisation de LLM supplémentaires pour valider l’exactitude factuelle de la réponse.
- Développez des mécanismes de secours pour gérer les cas où la réponse générée ne répond pas aux exigences d’exactitude factuelle, par exemple en générant des réponses alternatives ou en présentant des clauses d’exclusion de responsabilité à l’utilisateur.
- Gestion des erreurs
- Avec toutes les étapes de post-traitement, implémentez des mécanismes pour traiter correctement les cas où l’étape rencontre un problème ou ne parvient pas à générer une réponse satisfaisante. Cela peut impliquer la génération d’une réponse par défaut, ou l’escalade du problème à un opérateur humain en vue d’une révision manuelle.