Configurer l’apprentissage AutoML avec Python
S’APPLIQUE À :  SDK Python azureml v1
SDK Python azureml v1
Dans ce guide, découvrez comment configurer l’exécution d’un apprentissage AutoML (Machine Learning automatisé) avec le kit de développement logiciel (SDK) Python Azure Machine Learning à l’aide de l’AutoML Azure Machine Learning. Le ML automatisé choisit pour vous un algorithme et des hyperparamètres, et génère un modèle prêt pour le déploiement. Ce guide fournit des détails sur les différentes options que vous pouvez utiliser pour configurer des expériences ML automatisées.
Pour obtenir un exemple de bout en bout, consultez Tutoriel : AutoML - Former un modèle de régression.
Si vous préférez une expérience sans code, vous pouvez également Configurer un apprentissage AutoML sans code dans Azure Machine Learning Studio.
Prérequis
Pour cet article, vous avez besoin des éléments suivants :
Un espace de travail Azure Machine Learning. Pour créer l’espace de travail, consultez Créer des ressources d’espace de travail.
Le kit SDK Python d’Azure Machine Learning installé. Pour installer le kit de développement logiciel (SDK), vous pouvez :
Créer une instance de calcul, qui installe automatiquement le kit de développement logiciel (SDK) et est préconfigurée pour les flux de travail ML. Consultez Créer et gérer une instance de calcul Azure Machine Learning pour plus d’informations.
Installez vous-même le package
automl, qui comprend l’installation par défaut du Kit de développement logiciel (SDK).
Important
Les commandes python de cet article requièrent la dernière
azureml-train-automlversion du package.- Installez le dernier package
azureml-train-automldans votre environnement local. - Pour plus d’informations sur le dernier package
azureml-train-automl, consultez les notes de publication.
Avertissement
Python 3.8 n’est pas compatible avec
automl.
Sélectionner le type de votre expérience
Avant de commencer votre expérience, vous devez déterminer le type de problème de machine learning que vous résolvez. La Machine Learning automatisé prend en charge les types de tâches classification, regression et forecasting. Découvrez plus d’informations sur les types de tâches.
Notes
Prise en charge des tâches de traitement en langage naturel (NLP) : la classification des images (plusieurs classes et plusieurs étiquettes) et la reconnaissance d’entités nommées sont disponibles en préversion publique. En savoir plus sur les tâches de NLP dans le ML automatisé.
Ces fonctionnalités en préversion sont fournies sans contrat de niveau de service. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Le code suivant utilise le paramètre task dans le constructeur AutoMLConfig pour spécifier le type d’expérience comme classification.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Source et format des données
Le machine learning automatisé prend en charge les données qui se trouvent sur votre poste de travail local ou dans le cloud, comme Stockage Blob Azure. Les données peuvent être lues dans un DataFrame Pandas ou un TabularDataset Azure Machine Learning. En savoir plus sur les jeux de données.
Configuration requise pour les données d’apprentissage en lien avec le Machine Learning :
- Les données doivent être sous forme tabulaire.
- La valeur à prédire, la colonne cible, doit figurer dans les données.
Important
Les expériences ML automatisées ne prennent pas en charge l’entraînement avec les jeux de données qui utilisent un accès aux données basé sur les identités.
Pour les expériences à distance, les données d’entraînement doivent être accessibles à partir de la ressource de calcul distante. AutoML accepte uniquement TabularDatasets Azure Machine Learning lors de l’utilisation d’un calcul distant.
Les jeux de données Azure Machine Learning exposent les fonctionnalités suivantes :
- Transférez facilement des données de fichiers statiques ou d’URL sources vers votre espace de travail.
- Rendez vos données disponibles pour l’entraînement des scripts dans le cas de l’exécution sur des ressources de calcul cloud. Pour obtenir un exemple d’utilisation de la classe
Datasetpour monter des données dans votre cible de calcul à distance, consultez Comment former un modèle avec des jeux de données.
Le code suivant crée un TabularDataset à partir d’une URL web. Consultez Créer un TabularDataset pour obtenir des exemples de code sur la création de jeux de données à partir d’autres sources, comme des fichiers locaux et des magasins de données.
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
Pour les expériences de calcul locales, nous recommandons les dataframes pandas pour accélérer les temps de traitement.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Formation, validation et test des données
Vous pouvez spécifier des jeux de données d’apprentissage et de validation distincts directement dans le constructeur AutoMLConfig. Découvrez comment configurer la formation, la validation, la validation croisée et les données de test pour vos expériences AutoML.
Si vous ne spécifiez pas explicitement un paramètre validation_data ou n_cross_validation, le Machine Learning automatisé applique les techniques par défaut pour déterminer la façon dont la validation est effectuée. Cette détermination dépend du nombre de lignes dans le jeu de données affecté à votre paramètre training_data.
| Taille des données d’entraînement | Technique de validation |
|---|---|
| Plus de 20 000 lignes | Le fractionnement des données de formation/validation est appliqué. La valeur par défaut consiste à prendre 10 % du jeu de données d’apprentissage initial en tant que jeu de validation. Ce jeu de validation est ensuite utilisé pour le calcul des métriques. |
| Moins de 20 000 lignes | L’approche de validation croisée est appliquée. Le nombre de plis par défaut dépend du nombre de lignes. Si le jeu de données est inférieur à 1 000 lignes, 10 plis sont utilisés. S’il y a entre 1 000 et 20 000 lignes, trois plis sont utilisés. |
Conseil
Vous pouvez charger des données de test (préversion) pour évaluer les modèles que le ML automatisé a générés pour vous. Ces fonctionnalités sont des capacités en préversion expérimentales susceptibles d’évoluer à tout moment. Découvrez comment :
- Transmettre des données de test à votre objet AutoMLConfig.
- Tester les modèles générés par le ML automatisé pour votre expérience.
Si vous préférez une expérience sans code, consultez l’étape 12 dans Configurer AutoML avec l’interface utilisateur du studio.
Données volumineuses
AutoML prend en charge un nombre limité d’algorithmes à des fins d’apprentissage sur des données volumineuses susceptibles de générer des modèles de Big Data sur de petites machines virtuelles. Les heuristiques AutoML dépendent de propriétés telles que la taille des données, la taille de mémoire de la machine virtuelle, l’expiration de l’expérience et les paramètres caractérisation pour déterminer si ces algorithmes de données volumineuses doivent être appliqués. Découvrez les modèles pris en charge dans AutoML.
Pour la régression, Régresseur de descente de gradient en ligne et Régresseur linéaire rapide
Pour la classification, Classifieur Perceptron moyenné et Classifieur SVM linéaire, où le classifieur SVM linéaire a des versions de données volumineuses et non volumineuses.
Si vous souhaitez remplacer ces heuristiques, appliquez les paramètres suivants :
| Tâche | Paramètre | Notes |
|---|---|---|
| Bloquer les algorithmes de streaming de données | blocked_models de votre objet AutoMLConfig, puis répertoriez le(s) modèle(s) que vous ne souhaitez pas utiliser. |
Provoque l’échec de l’exécution ou une durée d’exécution longue |
| Utiliser les algorithmes de streaming de données | allowed_models de votre objet AutoMLConfig, puis répertoriez le(s) modèle(s) que vous souhaitez utiliser. |
|
| Utiliser les algorithmes de streaming de données (expériences de l’interface utilisateur Studio) |
Bloquez tous les modèles, à l’exception des algorithmes de Big Data que vous souhaitez utiliser. |
Capacité de calcul pour exécuter l’expérience
Ensuite, l’endroit où le modèle doit être entraîné est déterminé. Une expérience de ML automatisé peut s’exécuter sur les options de calcul suivantes.
Choisir un calcul local : si votre scénario concerne des explorations initiales ou des démonstrations utilisant des données de petite taille et des apprentissages courts (de quelques secondes à quelques minutes par exécution enfant), un apprentissage sur votre ordinateur local peut constituer un meilleur choix. Il n’y a pas de temps de configuration. Les ressources d’infrastructure (votre PC ou votre machine virtuelle) sont directement disponibles. Consultez ce notebook pour un exemple de calcul local.
Choisir un cluster de calcul de Machine Learning distant : si vous effectuez un apprentissage avec des jeux de données plus volumineux, tel un apprentissage de production créant des modèles nécessitant des apprentissages plus longs, un calcul distant offre des performances de temps de bout en bout bien meilleures, car
AutoMLparallélise les apprentissages dans les nœuds du cluster. Sur un calcul distant, le temps de démarrage de l’infrastructure interne ajoute environ 1,5 minute par exécution enfant, ainsi que des minutes supplémentaires pour l’infrastructure de cluster si les machines virtuelles ne sont pas encore en cours d’exécution.Azure Machine Learning Managed Compute est un service managé qui permet d’entraîner des modèles Machine Learning sur des clusters de machines virtuelles Azure. L’instance de calcul est également prise en charge en tant que cible de calcul.Un cluster Azure Databricks dans votre abonnement Azure. Pour plus de détails, consultez Configurer un cluster Azure Databricks pour ML automatisé. Consultez ce site GitHub pour voir des exemples de notebooks avec Azure Databricks.
Lors du choix de votre cible de calcul, considérez les facteurs suivants :
| Avantages (avantages) | Inconvénients (handicaps) | |
|---|---|---|
| Cible de calcul locale | ||
| Clusters de calcul ML distants |
Configurer les paramètres de votre expérience
Vous pouvez utiliser plusieurs options pour configurer des expériences de ML automatisé. Ces paramètres sont définis en instanciant un objet AutoMLConfig. Pour obtenir la liste complète des paramètres, reportez-vous à la Classe AutoMLConfig.
L’exemple suivant est destiné à une tâche de classification. L’expérience utilise l’AUC pondéré comme métrique principale et présente un délai d’expiration défini sur 30 minutes et 2 plis de validation croisée.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
Vous pouvez également configurer des tâches de prévision qui nécessitent une configuration supplémentaire. Pour plus d’informations, consultez l’article Configurer AutoML pour la prévision de séries chronologiques.
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Modèles pris en charge
Le machine learning automatisé essaie différents modèles et algorithmes lors du processus d’automatisation et d’optimisation. En tant qu’utilisateur, vous n’avez pas besoin de spécifier l’algorithme.
Les trois valeurs de paramètre task différentes déterminent la liste des algorithmes ou modèles à appliquer. Utilisez les paramètres allowed_models ou blocked_models pour modifier les itérations avec les modèles disponibles à inclure ou à exclure.
Le tableau suivant récapitule les modèles pris en charge par type de tâche.
Notes
Si vous envisagez d’exporter vos modèles créés de ML automatisé vers un modèle ONNX, seuls les algorithmes indiqués par * (astérisque) peuvent être convertis au format ONNX. Apprenez-en davantage sur la conversion de modèles au format ONNX.
Notez également qu’ONNX prend en charge uniquement les tâches de classification et de régression pour l’instant.
Métrique principale
Le paramètre primary_metric détermine la métrique à utiliser pendant l’entraînement du modèle dans un but d’optimisation. Les mesures disponibles que vous pouvez sélectionner sont déterminées par le type de tâche que vous choisissez.
Le choix d’une métrique principale pour l’optimisation du ML automatisé dépend de nombreux facteurs. Nous vous recommandons avant tout de choisir une métrique correspondant au mieux à vos besoins métier. Examinez ensuite si la métrique convient pour votre profil de jeu de données (taille des données, plage, distribution de classe, etc.). Les sections suivantes résument les mesures principales recommandées en fonction du type de tâche et du scénario d’entreprise.
Pour découvrir les définitions spécifiques de ces métriques, consultez Comprendre les résultats du Machine Learning automatisé.
Métriques pour les scénarios de classification
Des métriques dépendant du seuil telles que accuracy, recall_score_weighted, norm_macro_recall et precision_score_weighted ne permettent pas d’obtenir une bonne optimisation pour des jeux de données de petite taille ou présentant une asymétrie (déséquilibre) de classe conséquente, ou lorsque la valeur de métrique attendue est très proche de 0.0 ou 1.0. Dans ces cas, AUC_weighted peut être un meilleur choix pour la métrique principale. Une fois l’opération de ML automatisé terminée, vous pouvez choisir le modèle gagnant en fonction de la métrique la plus adaptée à vos besoins métier.
| Métrique | Exemple(s) de cas d’usage |
|---|---|
accuracy |
Classification d’images, analyse des sentiments, prédiction d’attrition |
AUC_weighted |
Détection des fraudes, classification d’images, détection d’anomalies, détection de courrier indésirable |
average_precision_score_weighted |
analyse de sentiments |
norm_macro_recall |
Prédiction d’attrition |
precision_score_weighted |
Métriques pour les scénarios de régression
r2_score, normalized_mean_absolute_error et normalized_root_mean_squared_error essaient tous de réduire les erreurs de prédiction. r2_score et normalized_root_mean_squared_error réduisent les erreurs quadratiques moyennes, tandis que normalized_mean_absolute_error réduit la valeur absolue moyenne des erreurs. La valeur absolue traite les erreurs de toutes les amplitudes, et les erreurs au carré ont une pénalité beaucoup plus importante pour les erreurs avec des valeurs absolues plus grandes. Selon que les erreurs de plus grande taille doivent être punies ou non, vous pouvez choisir d’optimiser l’erreur au carré ou l’erreur absolue.
La principale différence entre r2_score et normalized_root_mean_squared_error est la façon dont elles sont normalisées et leurs significations. normalized_root_mean_squared_error est l’erreur quadratique moyenne normalisée par plage et peut être interprétée comme l’amplitude moyenne des erreurs pour la prédiction. r2_score est une erreur carrée moyenne normalisée par une estimation de la variance des données. Il s’agit de la proportion de variation qui peut être capturée par le modèle.
Notes
r2_score et normalized_root_mean_squared_error se comportent également de la même façon que les métriques principales. Si un jeu de validation fixe est appliqué, ces deux métriques optimisent la même cible, l’erreur quadratique moyenne, et sont optimisées par le même modèle. Lorsque seul un jeu d’apprentissage est disponible et que la validation croisée est appliquée, elles sont légèrement différentes, du fait que la normalisation de normalized_root_mean_squared_error est fixe en tant que plage de l’ensemble d’apprentissage, alors que la normalisation de r2_score serait différente pour chaque pli, car il s’agit de l’écart pour chaque pli.
Si le classement, plutôt que la valeur exacte, vous intéresse, spearman_correlation peut être un meilleur choix, car il mesure la corrélation de classement entre les valeurs réelles et les prédictions.
Toutefois, actuellement, aucune métrique principale pour la régression ne porte sur la différence relative. r2_score, normalized_mean_absolute_error et normalized_root_mean_squared_error traitent chacun une erreur de prédiction de 20 000 $ de la même façon pour un employé avec un salaire de 30 000 $ que pour un employé gagnant 20 millions $, si ces deux points de données appartiennent au même jeu de données pour la régression ou la même série chronologique spécifiée par l’identificateur de série chronologique. Or, en réalité, prévoir seulement 20 000 dollars de réduction sur un salaire de 20 millions de dollars est insignifiant (petite différence relative de 0,1 %), tandis que 20 000 dollars de réduction sur un salaire de 30 000 dollars est tout à fait conséquent (grande différence relative de 67 %). Pour résoudre le problème de différence relative, vous pouvez effectuer l’apprentissage d’un modèle avec les métriques principales disponibles, puis sélectionner le modèle avec la meilleure valeur de mean_absolute_percentage_error ou root_mean_squared_log_error.
| Métrique | Exemple(s) de cas d’usage |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Prédiction de prix (maison/produit/pourboire), examen de prédiction de score |
r2_score |
Retard de compagnie aérienne, estimation du salaire, temps de résolution des bogues |
normalized_mean_absolute_error |
Métriques pour les scénarios de prévision de séries chronologiques
Les recommandations sont similaires à celles indiquées pour les scénarios de régression.
| Métrique | Exemple(s) de cas d’usage |
|---|---|
normalized_root_mean_squared_error |
Prédiction (prévision) de prix, optimisation de stocks, prévision de la demande |
r2_score |
Prédiction (prévision) de prix, optimisation de stocks, prévision de la demande |
normalized_mean_absolute_error |
Caractérisation de données
Dans chaque expérience d’apprentissage automatique automatisée, vos données sont automatiquement mises à l’échelle et normalisées pour faciliter l’exécution de certains algorithmes qui sont sensibles aux caractéristiques d’échelles différentes. Cette mise à l’échelle et la normalisation sont appelées caractérisation. Pour plus d’informations et des exemples de code, consultez Caractérisation dans AutoML.
Notes
Les étapes de caractérisation du Machine Learning automatisé (normalisation des fonctionnalités, gestion des données manquantes, conversion de texte en valeurs numériques, etc.) font partie du modèle sous-jacent. Lorsque vous utilisez le modèle pour des prédictions, les étapes de caractérisation qui sont appliquées pendant la formation sont appliquées automatiquement à vos données d’entrée.
Lorsque vous configurez vos expériences dans votre objet AutoMLConfig, vous pouvez activer/désactiver le paramètre featurization. Le tableau suivant présente les paramètres acceptés pour la caractérisation dans l’objet AutoMLConfig.
| Configuration de la caractérisation | Description |
|---|---|
"featurization": 'auto' |
Indique que, dans le cadre du prétraitement, des étapes de garde-fous des données et de caractérisation sont automatiques. Paramètre par défaut. |
"featurization": 'off' |
Indique que l’étape de caractérisation ne doit pas être automatique. |
"featurization": 'FeaturizationConfig' |
Indique que l’étape de caractérisation personnalisée doit être utilisée. Découvrez comment personnaliser la caractérisation. |
Configuration des ensembles
Les modèles ensemblistes sont activés par défaut, et leurs itérations apparaissent comme les dernières itérations d’une exécution d’AutoML. Actuellement, VotingEnsemble et StackEnsemble sont pris en charge.
Le vote implémente un vote réversible, qui utilise des moyennes pondérées. La méthode d’empilement utilise une implémentation à deux couches, dans laquelle la première couche comprend les mêmes modèles que l’ensemble de vote, et où le modèle de la deuxième couche sert à trouver la combinaison optimale des modèles de la première couche.
Si vous utilisez des modèles ONNX ou si vous avez activé l’explicabilité des modèles, l’empilement est désactivé et seul le vote est utilisé.
La formation des ensembles peut être désactivée à l’aide des paramètres booléens enable_voting_ensemble et enable_stack_ensemble.
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Plusieurs arguments par défaut peuvent être fournis en tant que kwargs dans un objet AutoMLConfig pour modifier le comportement par défaut de l’ensemble.
Important
Les paramètres suivants ne sont pas des paramètres explicites de la classe AutoMLConfig.
ensemble_download_models_timeout_sec: Pendant la génération des modèles VotingEnsemble et StackEnsemble, plusieurs modèles ajustés des exécutions enfants précédentes sont téléchargés. Si vous rencontrez l’erreur suivante :AutoMLEnsembleException: Could not find any models for running ensembling, vous devrez peut-être prévoir plus de temps pour le téléchargement des modèles. La valeur par défaut est de 300 secondes pour le téléchargement de ces modèles en parallèle et il n’y a pas de limite maximale pour le délai d’expiration. Si plus de temps est nécessaire, configurez ce paramètre avec une valeur supérieure à 300 secondes.Notes
Si le délai d’expiration est atteint et que des modèles sont téléchargés, l’ensemble se poursuit avec autant de modèles qu’il a téléchargés. Il n’est pas nécessaire que tous les modèles soient téléchargés pour terminer dans ce délai. Les paramètres suivants s’appliquent uniquement aux modèles StackEnsemble :
stack_meta_learner_type: ce modèle est entraîné avec la sortie de modèles hétérogènes individuels. Les méta-learners par défaut sontLogisticRegressionpour les tâches de classification (ouLogisticRegressionCV, si la validation croisée est activée) etElasticNetpour les tâches de régression/prévision (ouElasticNetCV, si la validation croisée est activée). Ce paramètre peut correspondre à l’une des chaînes suivantes :LogisticRegression,LogisticRegressionCV,LightGBMClassifier,ElasticNet,ElasticNetCV,LightGBMRegressorouLinearRegression.stack_meta_learner_train_percentage: spécifie la proportion du jeu d’entraînement (lorsque vous choisissez le type d’entraînement « Entraîner et valider ») à réserver pour l’entraînement du méta-learner. La valeur par défaut est0.2.stack_meta_learner_kwargs: paramètres facultatifs à passer à l’initialiseur du méta-learner. Ces paramètres et types de paramètres reflètent ceux du constructeur de modèle correspondant, et sont transmis à celui-ci.
Le code suivant montre un exemple de spécification d’un comportement d’ensemble personnalisé dans un objet AutoMLConfig.
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Critères de sortie
Vous pouvez définir quelques options dans votre AutoMLConfig pour terminer votre expérience.
| Critères | description |
|---|---|
| Aucun critère | si vous ne définissez pas de paramètres de sortie, l’expérience continuera jusqu’à ce que votre métrique principale ne progresse plus. |
| Après un certain temps | Utilisez experiment_timeout_minutes dans vos paramètres pour définir la durée, en minutes, pendant laquelle votre expérience doit continuer à s’exécuter. Pour éviter les échecs d’expiration du délai d’expérience, il y a un minimum de 15 minutes, ou de 60 minutes si la taille de ligne par colonne dépasse 10 millions. |
| Un score a été atteint | Si vous utilisez experiment_exit_score, l’expérience se termine après qu’un score de métrique principal spécifié a été atteint. |
Exécuter une expérience
Avertissement
Si vous exécutez plusieurs fois une expérience avec les mêmes paramètres de configuration et la même métrique principale, vous constaterez probablement des variations dans chaque score de métrique finale d’expériences et de modèles générés. Les algorithmes utilisés par le ML automatisé présentent un fonctionnement aléatoire inhérent qui peut provoquer de légères variations dans la sortie des modèles par l’expérience et le score de métrique final de modèle recommandé, comme la précision. Vous verrez probablement également des résultats avec le même nom de modèle, mais des hyperparamètres différents.
Pour le Machine Learning automatisé, vous devez créer un objet Experiment, qui est un objet nommé d’un Workspace, utilisé pour exécuter des expériences.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Soumettez l’expérience pour qu’elle s’exécute et génère un modèle. Passez AutoMLConfig à la méthode submit pour générer le modèle.
run = experiment.submit(automl_config, show_output=True)
Notes
Les dépendances sont d’abord installées sur une nouvelle machine. Jusqu’à 10 minutes peuvent être nécessaires avant l’affichage de la sortie.
La définition de show_output sur True fait que la sortie est affichée sur la console.
Plusieurs exécutions enfants sur des clusters
Les exécutions enfants d’expérimentation ML automatisé peuvent intervenir sur un cluster exécutant déjà une autre expérience. Toutefois, le minutage dépend du nombre de nœuds du cluster et de la disponibilité de ces nœuds pour exécuter une expérience différente.
Chaque nœud du cluster fait office de machine virtuelle individuelle capable d’effectuer une seule exécution d’apprentissage ; en termes de ML automatisé, cela signifie une exécution enfant. Si tous les nœuds sont occupés, la nouvelle expérience est mise en file d’attente. Cela étant, si des nœuds sont disponibles, la nouvelle expérience procède à des exécutions enfants de ML automatisé en parallèle dans les nœuds/machines virtuelles disponibles.
Pour faciliter la gestion des exécutions enfants et le moment où elles peuvent intervenir, nous vous recommandons de créer un cluster dédié par expérience et de faire correspondre le nombre de max_concurrent_iterations de votre expérience avec le nombre de nœuds du cluster. Ainsi, vous utilisez tous les nœuds du cluster en même temps que les exécutions/itérations enfants simultanées de votre choix.
Configurez max_concurrent_iterations dans votre objet AutoMLConfig. S’il n’est pas configuré, par défaut, une seule exécution/itération enfant simultanée est autorisée par expérience.
Dans le cas d’une instance de calcul, max_concurrent_iterations peut être défini comme étant le même que le nombre de cœurs sur la machine virtuelle de l’instance de calcul.
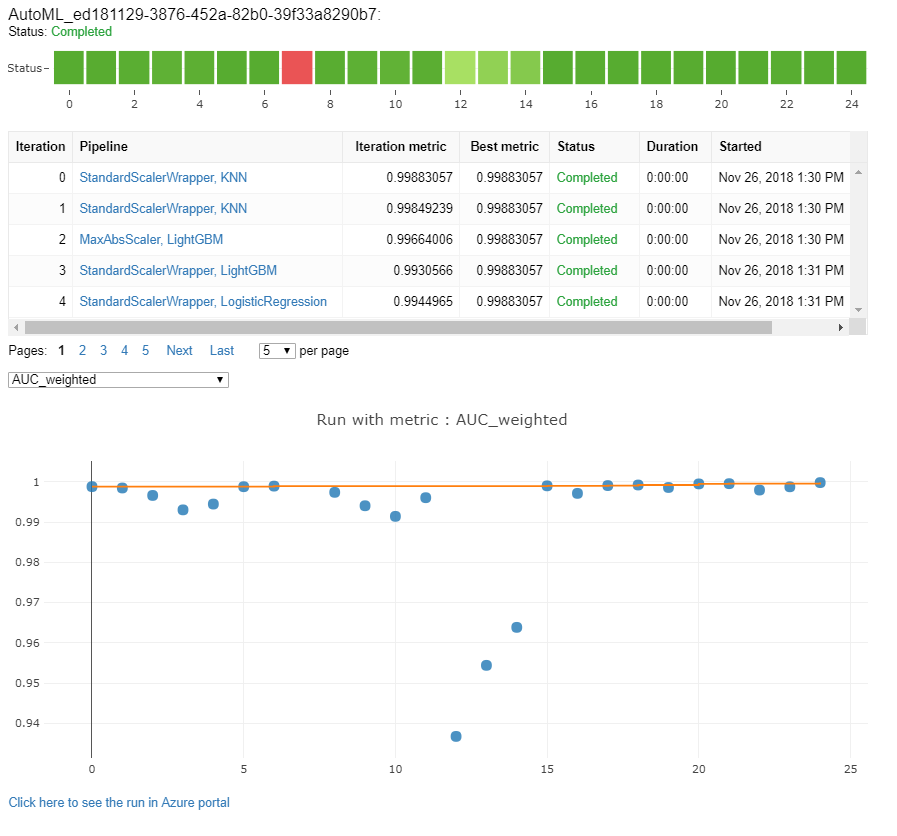
Explorer les modèles et les métriques
Le ML automatisé offre des options pour surveiller et évaluer les résultats de l’apprentissage.
Vous pouvez consulter vos résultats de formation dans un widget ou en ligne si vous êtes dans un notebook. Pour plus d’informations, consultez Surveiller les exécutions de Machine Learning automatisé.
Pour obtenir des définitions et des exemples des graphiques et métriques de performances fournis pour chaque exécution, consultez Évaluer les résultats de l’expérience de Machine Learning automatisé.
Pour obtenir un résumé de caractérisation et comprendre les fonctionnalités qui ont été ajoutées à un modèle particulier, consultez Transparence de la caractérisation.
Vous pouvez afficher les hyperparamètres, les techniques de mise à l’échelle et de normalisation, ainsi que l’algorithme appliqué à une exécution de ML automatisé spécifique avec la solution de code personnaliséprint_model().
Conseil
Le ML automatisé vous permet également d’afficher le code de formation du modèle généré pour les modèles entraînés par le ML automatique. Cette fonctionnalité est disponible en préversion publique et peut changer à tout moment.
Surveiller les exécutions de Machine Learning automatisé
Pour les exécutions de ML automatisé, pour accéder aux graphiques d’une exécution précédente, remplacez <<experiment_name>> par le nom de l’expérience appropriée :
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
Tester des modèles (préversion)
Important
Le test de vos modèles avec un jeu de données de test pour évaluer les modèles générés par le ML automatisé est une fonctionnalité d’évaluation. Cette capacité est une caractéristique expérimentale en préversion qui peut évoluer à tout moment.
Avertissement
Cette fonctionnalité n’est pas disponible pour les scénarios de ML automatisé suivants :
- Tâches de vision par ordinateur
- Entraînement d’un grand nombre de modèles de prévision de séries chronologiques hiérarchiques (préversion)
- Tâches de prévision pour lesquelles le deep learning des réseaux neuronaux (DNN) est activé
- Exécution du ML automatisé à partir de calculs locaux ou de clusters Azure Databricks
Lorsque vous transmettez des paramètres test_data ou test_size dans le AutoMLConfig, vous déclenchez automatiquement une série de tests à distance qui utilise les données de test fournies pour évaluer le meilleur modèle que le ML automatisé recommande à l’issue de l’expérience. Cette série de tests à distance est effectuée à la fin de l’expérience, une fois que le meilleur modèle est déterminé. Voir comment transmettre des données de test dans votre AutoMLConfig.
Obtenir les résultats du travail de test
Vous pouvez obtenir les prédictions et les mesures de la tâche de tests distants à partir de Azure Machine Learning studio ou avec le code suivant.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
La tâche de tests du modèle génère le fichier predictions.csv qui est stocké dans le magasin de données par défaut créé avec l’espace de travail. Ce magasin données est visible par tous les utilisateurs d’un même abonnement. Les tâches de tests ne sont pas recommandées pour les scénarios où les informations utilisées ou créées par la tâche de tests doivent rester privées.
Tester le modèle de ML automatisé existant
Pour tester d’autres modèles de ML automatisé créés, la meilleure tâche ou tâche enfant, utilisez ModelProxy() pour tester un modèle une fois l’exécution principale d’AutoML terminée. ModelProxy() renvoie déjà les prédictions et les mesures et ne nécessite pas de traitement supplémentaire pour récupérer les sorties.
Notes
ModelProxy est une classe d’évaluation expérimentale susceptible d’évoluer à tout moment.
Le code suivant montre comment tester un modèle à partir de n’importe quelle exécution à l’aide de la méthode ModelProxy.test(). Dans la méthode test(), vous avez la possibilité de spécifier si vous souhaitez uniquement voir les prédictions de la série de tests avec le paramètre include_predictions_only.
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Inscrire et déployer des modèles
Après avoir testé un modèle et confirmé que vous souhaitez l’utiliser en production, vous pouvez l’inscrire pour une utilisation ultérieure.
Pour enregistrer un modèle à partir d’une exécution de ML automatisé, utilisez la méthode register_model().
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Pour plus d’informations sur la création d’une configuration de déploiement et le déploiement d’un modèle enregistré dans un service web, consultez Comment et où déployer un modèle.
Conseil
Pour les modèles enregistrés, le déploiement en un clic est disponible via Azure Machine Learning studio. Découvrez comment déployer des modèles enregistrés à partir de Studio.
Interprétabilité de modèles
L’interprétabilité de modèles vous permet de comprendre pourquoi vos modèles ont effectué des prédictions, ainsi que les valeurs d’importance des caractéristiques sous-jacentes. Le SDK comprend différents packages pour l’activation des caractéristiques d’interprétabilité de modèles, aussi bien au moment de l’entraînement qu’au moment de l’inférence, pour les modèles locaux et déployés.
Découvrez comment activer les caractéristiques d’interprétabilité spécifiquement au sein d’expériences de ML automatisé.
Pour obtenir des informations générales sur la façon dont les explications de modèle et l’importance des caractéristiques peuvent être activées dans d’autres domaines du SDK en dehors du Machine Learning automatisé, consultez l’article de présentation du concept de l’interprétabilité.
Notes
Le modèle ForecastTCN n’est actuellement pas pris en charge par le client d’explication. Ce modèle ne retourne pas de tableau de bord s’il est retourné comme meilleur modèle et ne prend pas en charge les exécutions d’explications à la demande.
Étapes suivantes
Découvrez plus d’informations sur comment et où déployer un modèle.
Découvrez plus d’informations sur comment effectuer l’apprentissage d’un modèle de régression avec le Machine Learning automatisé.