Formato di file di Excel in Azure Data Factory e Azure Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Seguire questo articolo quando si desidera analizzare i file di Excel. Il servizio supporta sia ".xls" che ".xlsx".
Il formato Excel è supportato per i connettori seguenti: Amazon S3, Amazon S3 Compatible Storage, BLOB di Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, File di Azure, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage e SFTP. È supportato come origine, ma non come sink.
Nota
Il formato ".xls" non è supportato durante l'uso di HTTP.
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati. In questa sezione viene fornito un elenco delle proprietà supportate dal set di dati di Excel.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su Excel. | Sì |
| location | Impostazioni di posizione dei file. Ogni connettore basato su file ha il proprio tipo di percorso e le proprietà supportate in location. |
Sì |
| sheetName | Nome del foglio di lavoro di Excel per leggere i dati. | Specificare sheetName o sheetIndex |
| sheetIndex | Indice del foglio di lavoro di Excel per leggere i dati, a partire da 0. | Specificare sheetName o sheetIndex |
| range | Intervallo di celle nel foglio di lavoro specificato per individuare i dati selettivi, ad esempio: - Non specificato: legge l'intero foglio di lavoro come tabella dalla prima riga e colonna non vuota - A3: legge una tabella a partire dalla cella specificata, rileva dinamicamente tutte le righe seguenti e tutte le colonne a destra- A3:H5: legge questo intervallo fisso come tabella- A3:A3: legge questa singola cella |
No |
| firstRowAsHeader | Specifica se trattare la prima riga dell’intervallo/foglio di lavoro come riga di intestazione con nomi di colonne. I valori consentiti sono true e false (impostazione predefinita). |
No |
| nullValue | Specifica la rappresentazione di stringa del valore Null. Il valore predefinito è stringa vuota. |
No |
| compressione | Gruppo di proprietà per configurare la compressione dei file. Configurare questa sezione se si desidera eseguire la compressione/decompressione durante l'esecuzione dell'attività. | No |
| type (in compression) |
Codec di compressione usato per leggere/scrivere file JSON. I valori consentiti sono bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappyo lz4. Il valore predefinito non è compresso. Nota attualmente l'attività Copy non supporta "snappy" & "lz4" e il flusso di dati di mapping non supporta "ZipDeflate", "TarGzip" e "Tar". Si noti che quando si usa l'attività di copia per decomprimere i file ZipDeflate e scrivere nell'archivio dati sink basato su file, i file vengono estratti nella cartella : <path specified in dataset>/<folder named as source zip file>/. |
No. |
| level (in compression) |
Rapporto di compressione. I valori consentiti sono ottimale o più veloce. - Fastest: l'operazione di compressione deve essere completata il più rapidamente possibile, anche se il file risultante non viene compresso in modo ottimale. - Optimal: l'operazione di compressione deve comprimere il file in modo ottimale, anche se il completamento richiede più tempo. Per maggiori informazioni, vedere l'argomento relativo al livello di compressione . |
No |
Di seguito è riportato un esempio di set di dati di Excel in Archiviazione BLOB di Azure:
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. In questa sezione viene fornito un elenco delle proprietà supportate dall'origine excel.
Excel come origine
Nella sezione *source* dell'attività Copy sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su ExcelSource. | Sì |
| storeSettings | Gruppo di proprietà su come leggere i dati da un archivio dati. Ogni connettore basato su file dispone di impostazioni di lettura proprie supportate in storeSettings. |
No |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Proprietà del flusso di dati per mapping
Nei flussi di dati di mapping è possibile leggere il formato excel negli archivi dati seguenti: Archiviazione BLOB di Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Amazon S3 e SFTP. È possibile puntare ai file di Excel usando il set di dati di Excel o usando un set di dati inline.
Proprietà di origine
Nella tabella seguente sono elencate le proprietà supportate da un'origine excel. È possibile modificare queste proprietà nella scheda Opzioni origine. Quando si usa il set di dati inline, verranno visualizzate impostazioni di file aggiuntive, che corrispondono alle proprietà descritte nella sezione proprietà del set di dati.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Percorsi con caratteri jolly | Verranno elaborati tutti i file corrispondenti al percorso con caratteri jolly. Esegue l'override della cartella e del percorso del file impostato nel set di dati. | no | String[] | wildcardPaths |
| Partition Root Path (Percorso radice partizione) | Per i dati dei file partizionati, è possibile immettere un percorso radice della partizione per leggere le cartelle partizionate come colonne | no | String | partitionRootPath |
| Elenco di file | Indica se l'origine punta a un file di testo che elenca i file da elaborare | no | true oppure false |
fileList |
| Colonna in cui archiviare il nome file | Creare una nuova colonna con il nome e il percorso del file di origine | no | String | rowUrlColumn |
| Dopo il completamento | Eliminare o spostare i file dopo l'elaborazione. Il percorso del file inizia dalla radice del contenitore | no | Eliminare: true o false Spostare: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtra per data ultima modifica | Scegliere di filtrare i file in base all'ultima modifica | no | Timestamp: | modifiedAfter modifiedBefore |
| Consenti nessun file trovato | Se true, non viene generato un errore se non vengono trovati file | no | true oppure false |
ignoreNoFilesFound |
Esempio di origine
L'immagine seguente è un esempio di configurazione di origine excel nei flussi di dati di mapping tramite la modalità set di dati.
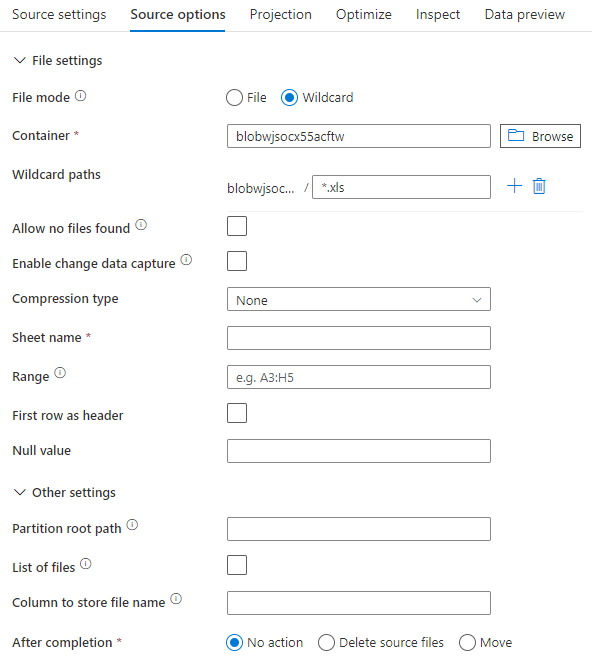
Lo script del flusso di dati associato è:
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
Se si usa un set di dati inline, nel flusso di dati di mapping vengono visualizzate le opzioni di origine seguenti.
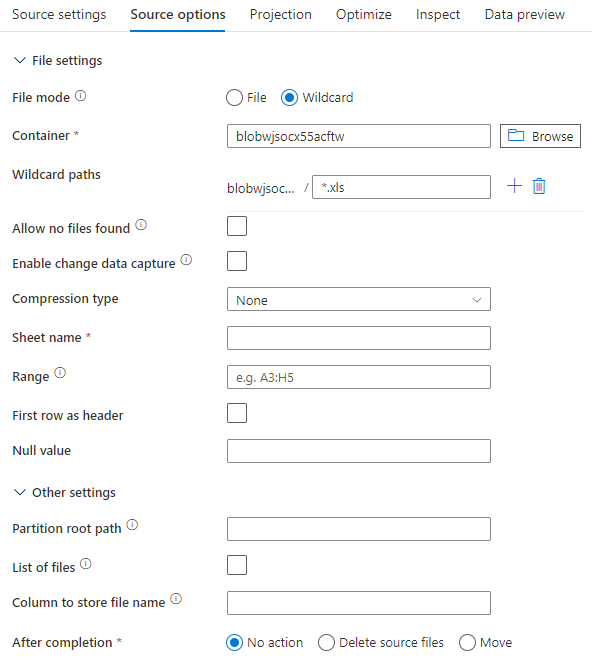
Lo script del flusso di dati associato è:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Nota
Il flusso di dati di mapping non supporta la lettura di file di Excel protetti, perché questi file possono contenere avvisi di riservatezza o imporre restrizioni di accesso specifiche che limitano l'accesso al contenuto.
Gestione di file di Excel molto grandi
Il connettore Excel non supporta la lettura in streaming per il attività Copy e deve caricare l'intero file in memoria prima che i dati possano essere letti. Per importare schema, visualizzare in anteprima i dati o aggiornare un set di dati di Excel, i dati devono essere restituiti prima del timeout della richiesta HTTP (100s). Per i file di Excel di grandi dimensioni, queste operazioni potrebbero non terminare entro tale intervallo di tempo, causando un errore di timeout. Se si desidera spostare file di Excel di grandi dimensioni (>100 MB) in un altro archivio dati, è possibile utilizzare una delle opzioni seguenti per ovviare a questa limitazione:
- Usare il runtime di integrazione self-hosted (SHIR), quindi usare il attività Copy per spostare il file di Excel di grandi dimensioni in un altro archivio dati con shir.
- Dividere il file di Excel di grandi dimensioni in diversi file più piccoli, quindi usare il attività Copy per spostare la cartella contenente i file.
- Usare un'attività del flusso di dati per spostare il file di Excel di grandi dimensioni in un altro archivio dati. Il flusso di dati supporta la lettura in streaming per Excel e può spostare/trasferire rapidamente file di grandi dimensioni.
- Convertire manualmente il file di Excel di grandi dimensioni in formato CSV, quindi usare un attività Copy per spostare il file.