Copiare dati da Un'archiviazione compatibile con Amazon S3 usando Azure Data Factory o Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo descrive come copiare dati da Amazon Simple Storage Service (Amazon S3) Compatible Storage Storage. Per altre informazioni, vedere gli articoli introduttivi per Azure Data Factory e Synapse Analytics.
Funzionalità supportate
Questo connettore di archiviazione compatibile con Amazon S3 è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività Copy (origine/-) | (1) (2) |
| Attività Lookup | (1) (2) |
| Attività GetMetadata | (1) (2) |
| Attività Delete | (1) (2) |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
In particolare, questo connettore di archiviazione compatibile con Amazon S3 supporta la copia di file così come è o l'analisi dei file con i formati di file supportati e i codec di compressione. Il connettore usa AWS Signature Version 4 per autenticare le richieste a S3. È possibile usare questo connettore di archiviazione compatibile con Amazon S3 per copiare i dati da qualsiasi provider di archiviazione compatibile con S3. Specificare l'URL del servizio corrispondente nella configurazione del servizio collegato.
Autorizzazioni necessarie
Per copiare dati da Amazon S3 Compatible Storage, assicurarsi di avere ottenuto le autorizzazioni seguenti per le operazioni sugli oggetti Amazon S3: s3:GetObject e s3:GetObjectVersion.
Se si usa l'interfaccia utente per creare, sono necessarie autorizzazioni e s3:ListBucket/s3:GetBucketLocation aggiuntive s3:ListAllMyBuckets per operazioni come il test della connessione al servizio collegato e l'esplorazione dalla radice. Se non si vogliono concedere queste autorizzazioni, è possibile scegliere le opzioni "Test connessione al percorso del file" o "Sfoglia dal percorso specificato" dall'interfaccia utente.
Per l'elenco completo delle autorizzazioni di Amazon S3, vedere Specifica delle autorizzazioni in un criterio nel sito AWS.
Introduzione
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- SDK di Python
- Azure PowerShell
- API REST
- Modello di Azure Resource Manager
Creare un servizio collegato all'archiviazione compatibile con Amazon S3 usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato ad Amazon S3 Compatible Storage nell'interfaccia utente di portale di Azure.
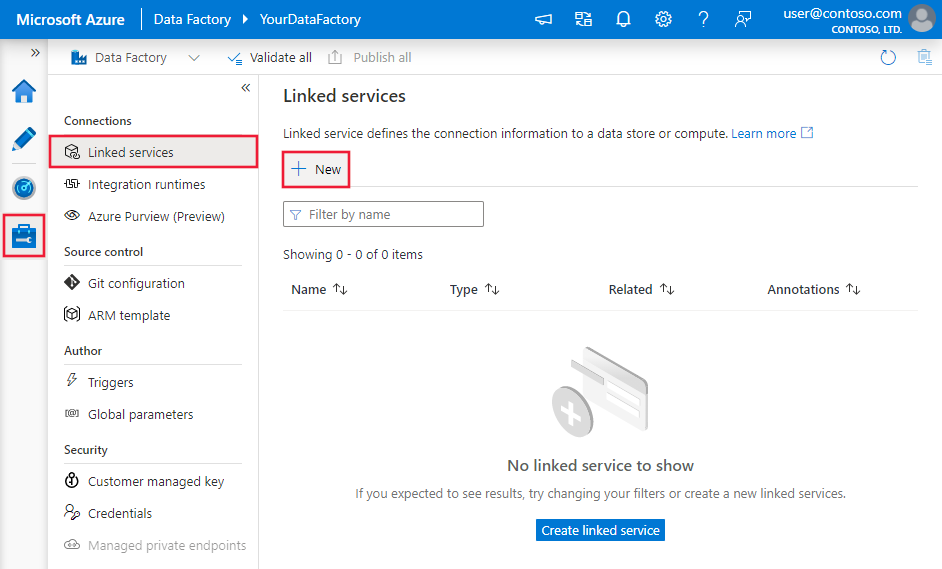
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
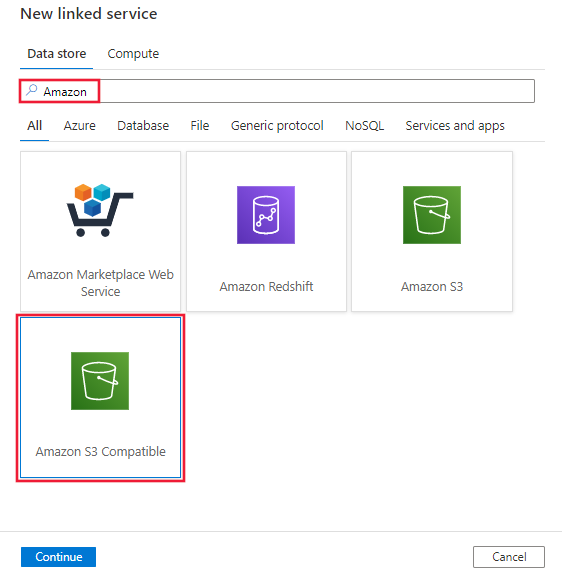
Cercare Amazon e selezionare il connettore Amazon S3 Compatible Storage.
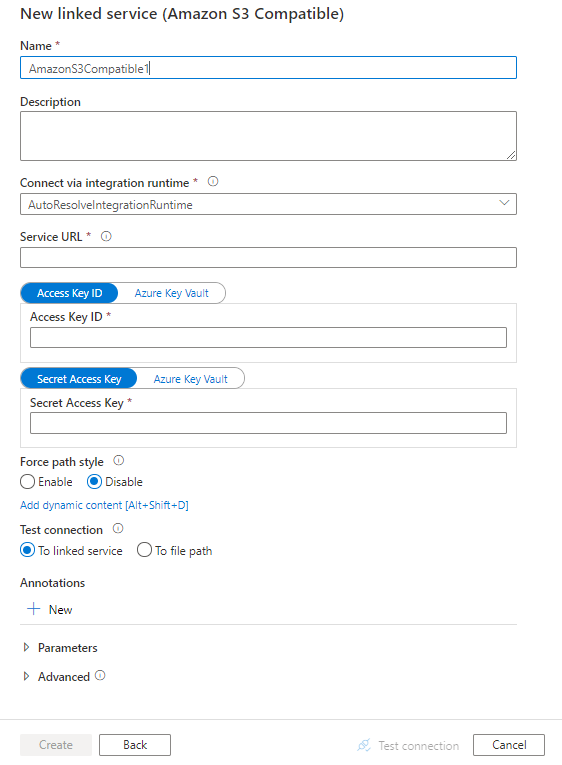
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti forniscono informazioni dettagliate sulle proprietà usate per definire entità specifiche di Amazon S3 Compatible Storage.
Proprietà del servizio collegato
Per un servizio collegato compatibile con Amazon S3 sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AmazonS3Compatible. | Sì |
| accessKeyId | ID della chiave di accesso segreta. | Sì |
| secretAccessKey | La stessa chiave di accesso segreta. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro oppure fare riferimento a un segreto archiviato in Azure Key Vault. | Sì |
| serviceUrl | Specificare l'endpoint https://<service url>S3 personalizzato. |
No |
| forcePathStyle | Indica se usare l'accesso in stile percorso S3 anziché l'accesso in stile ospitato virtuale. I valori consentiti sono: false (impostazione predefinita), true. Controllare la documentazione di ogni archivio dati se è necessario o meno l'accesso in stile percorso. |
No |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted, se l'archivio dati si trova in una rete privata. Se questa proprietà non è specificata, il servizio usa il runtime di integrazione di Azure predefinito. | No |
Esempio:
{
"name": "AmazonS3CompatibleLinkedService",
"properties": {
"type": "AmazonS3Compatible",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati.
Azure Data Factory supporta i formati di file seguenti. Per impostazioni basate sui formati, fare riferimento ai singoli articoli.
- Formato Avro
- Formato binario
- Formato di testo delimitato
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Le proprietà seguenti sono supportate per Amazon S3 Compatible in location impostazioni in un set di dati basato sul formato:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type in location in un set di dati deve essere impostata su AmazonS3CompatibleLocation. |
Sì |
| bucketName | Nome del bucket S3 Compatible Storage. | Sì |
| folderPath | Percorso della cartella nel bucket specificato. Se si vuole usare un carattere jolly per filtrare la cartella, ignorare questa impostazione e specificare che nelle impostazioni dell'origine attività. | No |
| fileName | Nome del file nel bucket e nel percorso della cartella specificati. Se si vuole usare un carattere jolly per filtrare i file, ignorare questa impostazione e specificare che nelle impostazioni dell'origine dell'attività. | No |
| versione | Versione dell'oggetto Storage compatibile S3, se è abilitato il controllo delle versioni di archiviazione compatibile S3. Se non è specificato, verrà recuperata la versione più recente. | No |
Esempio:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Amazon S3 Compatible Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AmazonS3CompatibleLocation",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione fornisce un elenco delle proprietà supportate dall'origine di archiviazione compatibile con Amazon S3.
Amazon S3 Compatible Storage as a source type (Archiviazione compatibile con Amazon S3 come tipo di origine)
Azure Data Factory supporta i formati di file seguenti. Per impostazioni basate sui formati, fare riferimento ai singoli articoli.
- Formato Avro
- Formato binario
- Formato di testo delimitato
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
Le proprietà seguenti sono supportate per l'archiviazione compatibile con Amazon S3 nelle storeSettings impostazioni in un'origine di copia basata su formato:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type in storeSettings deve essere impostata su AmazonS3CompatibleReadSettings. |
Sì |
| Individuare i file da copiare: | ||
| OPZIONE 1: percorso statico |
Copia dal percorso del bucket o della cartella/file specificato nel set di dati. Per copiare tutti i file da un bucket o una cartella, specificare anche wildcardFileName come *. |
|
| OPZIONE 2: Prefisso di archiviazione compatibile con S3 - prefisso |
Prefisso per il nome della chiave di archiviazione compatibile S3 nel bucket specificato configurato in un set di dati per filtrare i file di archiviazione compatibili con S3 di origine. Le chiavi S3 Compatible Storage i cui nomi iniziano con bucket_in_dataset/this_prefix sono selezionate. Usa il filtro lato servizio S3 Compatible Storage, che garantisce prestazioni migliori rispetto a un filtro con caratteri jolly.Quando si usa il prefisso e si sceglie di copiare nel sink basato su file con conservazione della gerarchia, si noti che il sottopercorso dopo l'ultimo "/" nel prefisso verrà mantenuto. Ad esempio, per l'origine bucket/folder/subfolder/file.txt si configura il prefisso folder/sub e quindi il percorso del file conservato è subfolder/file.txt. |
No |
| OPZIONE 3: carattere jolly - wildcardFolderPath |
Percorso della cartella con caratteri jolly nel bucket specificato configurato in un set di dati per filtrare le cartelle di origine. I caratteri jolly consentiti sono: * (corrispondenza di zero o più caratteri) e ? (corrispondenza di zero caratteri o di un carattere singolo). Usare ^ per evitare che il nome della cartella contenga un carattere jolly o tale carattere di escape. Vedere altri esempi in Esempi di filtro file e cartelle. |
No |
| OPZIONE 3: carattere jolly - wildcardFileName |
Nome file con caratteri jolly nel percorso del bucket e della cartella specificati, oppure nel percorso della cartella con carattere jolly, per filtrare i file di origine. I caratteri jolly consentiti sono: * (corrispondenza di zero o più caratteri) e ? (corrispondenza di zero caratteri o di un carattere singolo). Usare ^ per evitare che il nome del file contenga un carattere jolly o tale carattere di escape. Vedere altri esempi in Esempi di filtro file e cartelle. |
Sì |
| OPZIONE 4: un elenco di file - fileListPath |
Indica di copiare un determinato set di file. Puntare a un file di testo che include un elenco di file da copiare, un file per riga, che rappresenta il percorso relativo del percorso configurato nel set di dati. Quando si usa questa opzione, non specificare un nome file nel set di dati. Per altri esempi, vedere Esempi di elenco di file. |
No |
| Impostazioni aggiuntive: | ||
| recursive | Indica se i dati vengono letti in modo ricorsivo dalle cartelle secondarie o solo dalla cartella specificata. Si noti che quando la proprietà recursive è impostata su true e il sink consiste in un archivio basato su file, una cartella o una sottocartella vuota non viene copiata o creata nel sink. I valori consentiti sono true (predefinito) e false. Questa proprietà non è applicabile quando si configura fileListPath. |
No |
| deleteFilesAfterCompletion | Indica se i file binari verranno eliminati dall'archivio di origine dopo il passaggio all'archivio di destinazione. L'eliminazione dei file avviene a livello di singolo file, pertanto quando l'attività Copy non riesce, verranno visualizzati alcuni file già copiati nella destinazione ed eliminati dall'origine, mentre altri sono ancora presenti nell'archivio di origine. Questa proprietà è valida solo nello scenario di copia dei file binari. Il valore predefinito è false. |
No |
| modifiedDatetimeStart | I file vengono filtrati in base all'attributo seguente: ultima modifica. I file verranno selezionati se la data/ora dell'ultima modifica è maggiore o uguale a modifiedDatetimeStart e minore di modifiedDatetimeEnd. Data e ora vengono applicate in base al fuso orario UTC nel formato "2018-12-01T05:00:00Z". Le proprietà possono essere NULL, a indicare che al set di dati non verrà applicato alcun filtro di attributo di file. Quando modifiedDatetimeStart presenta un valore datetime ma modifiedDatetimeEnd è NULL, verranno selezionati i file il cui ultimo attributo modificato sia maggiore o uguale al valore datetime. Quando modifiedDatetimeEnd ha un valore datetime ma modifiedDatetimeStart è NULL verranno selezionati i file il cui ultimo attributo modificato sia minore del valore datetime.Questa proprietà non è applicabile quando si configura fileListPath. |
No |
| modifiedDatetimeEnd | Come sopra. | No |
| enablePartitionDiscovery | Per i file partizionati, specificare se analizzare le partizioni dal percorso del file e aggiungerle come colonne di origine aggiuntive. I valori consentiti sono false (predefinito) e true. |
No |
| partitionRootPath | Quando l'individuazione delle partizioni è abilitata, specificare il percorso radice assoluto per leggere le cartelle partizionate come colonne di dati. Se ciò non è specificato, per impostazione predefinita, - Quando si usa il percorso del file nel set di dati o nell'elenco di file nell'origine, il percorso radice della partizione è il percorso configurato nel set di dati. - Quando si usa il filtro delle cartelle con caratteri jolly, il percorso radice della partizione è il percorso secondario prima del primo carattere jolly. - Quando si usa il prefisso, il percorso radice della partizione è sottopercorso prima dell'ultimo "/". Si supponga, ad esempio, di configurare il percorso nel set di dati come "root/folder/year=2020/month=08/day=27": - Se si specifica il percorso radice della partizione come "root/folder/year=2020", l'attività Copy genererà altre due colonne month e day, rispettivamente con il valore "08" e "27", oltre alle colonne all'interno dei file.- Se il percorso radice della partizione non è specificato, non verrà generata alcuna colonna aggiuntiva. |
No |
| maxConcurrentConnections | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | No |
Esempio:
"activities":[
{
"name": "CopyFromAmazonS3CompatibleStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AmazonS3CompatibleReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Esempi di filtro file e cartelle
Questa sezione descrive il comportamento risultante del percorso cartella e del nome del file con i filtri con caratteri jolly.
| bucket | key | recursive | Struttura delle cartelle di origine e risultato del filtro (i file in grassetto sono stati recuperati) |
|---|---|---|---|
| bucket | Folder*/* |
false | bucket CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv AltraCartellaB File6.csv |
| bucket | Folder*/* |
true | bucket CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv AltraCartellaB File6.csv |
| bucket | Folder*/*.csv |
false | bucket CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv AltraCartellaB File6.csv |
| bucket | Folder*/*.csv |
true | bucket CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv AltraCartellaB File6.csv |
Esempi di elenco di file
Questa sezione descrive il comportamento risultante dell'uso di un percorso di elenco di file in un'origine attività Copy.
Si supponga di disporre della struttura di cartelle di origine seguente e di voler copiare i file in grassetto:
| Esempio di struttura di origine | Contenuto in FileListToCopy.txt | Impostazione |
|---|---|---|
| bucket CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv Metadati UFX FileListToCopy.txt |
File1.csv Sottocartella1/File3.csv Sottocartella1/File5.csv |
Nel set di dati: - Bucket: bucket- Percorso cartella: FolderANell'origine dell'attività Copy: - Percorso elenco file: bucket/Metadata/FileListToCopy.txt Il percorso dell'elenco di file fa riferimento a un file di testo nello stesso archivio dati che include un elenco di file da copiare, ad esempio un file per riga, con il percorso relativo a quello configurato nel set di dati. |
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Proprietà dell'attività GetMetadata
Per altre informazioni sulle proprietà, vedere Attività GetMetadata.
Proprietà dell'attività Delete
Per altre informazioni sulle proprietà, vedere Attività Delete.
Contenuto correlato
Per un elenco degli archivi dati supportati dall'attività Copy come origini e sink, vedere Archivi dati supportati.