Migliorare la qualità dell'applicazione RAG
Questo articolo offre una panoramica del modo in cui è possibile perfezionare ogni componente per aumentare la qualità dell'applicazione di generazione aumentata (RAG) di recupero.
Ci sono innumerevoli "manopole" da ottimizzare in ogni punto sia nella pipeline di dati offline che nella catena RAG online. Anche se ci sono innumerevoli altri, l'articolo è incentrato sulle manopole più importanti che hanno il maggiore impatto sulla qualità dell'applicazione RAG. Databricks consiglia di iniziare con queste manopole.
Due tipi di considerazioni sulla qualità
Dal punto di vista concettuale, è utile visualizzare le manopole di qualità RAG attraverso l'obiettivo dei due tipi chiave di problemi di qualità:
Qualità del recupero: si recuperano le informazioni più rilevanti per una determinata query di recupero?
È difficile generare output RAG di alta qualità se il contesto fornito all'LLM non contiene informazioni importanti o contiene informazioni superflue.
Qualità della generazione: date le informazioni recuperate e la query dell'utente originale, l'LLM genera la risposta più accurata, coerente e utile possibile?
I problemi qui possono manifestarsi come allucinazioni, output incoerente o mancata gestione diretta della query dell'utente.
Le app RAG hanno due componenti su cui è possibile eseguire l'iterazione per risolvere i problemi di qualità: la pipeline di dati e la catena. È consigliabile presupporre una divisione pulita tra i problemi di recupero (semplicemente aggiornare la pipeline di dati) e i problemi di generazione (aggiornare la catena RAG). Tuttavia, la realtà è più sfumata. La qualità del recupero può essere influenzata sia dalla pipeline di dati (ad esempio, la strategia di analisi/suddivisione in blocchi, la strategia di metadati, il modello di incorporamento) che la catena RAG (ad esempio, la trasformazione delle query utente, il numero di blocchi recuperati, la nuova classificazione). Analogamente, la qualità della generazione invariabilmente sarà influenzata da un recupero scarso (ad esempio, informazioni irrilevanti o mancanti che influiscono sull'output del modello).
Questa sovrapposizione sottolinea la necessità di un approccio olistico al miglioramento della qualità RAG. Comprendendo quali componenti modificare sia nella pipeline di dati che nella catena RAG e in che modo queste modifiche influiscono sulla soluzione complessiva, è possibile apportare aggiornamenti mirati per migliorare la qualità dell'output RAG.
Considerazioni sulla qualità della pipeline di dati
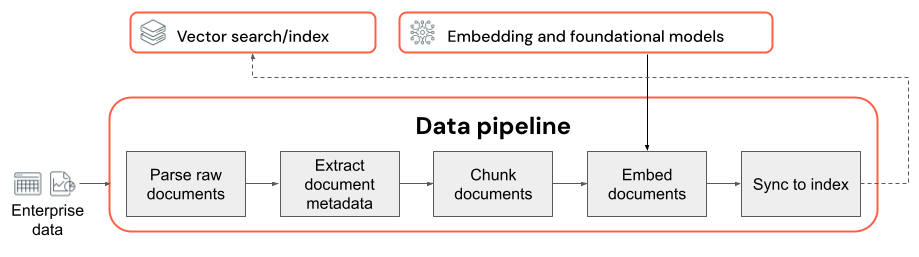
Considerazioni chiave sulla pipeline di dati:
- Composizione del corpus di dati di input.
- Modalità di estrazione e trasformazione dei dati non elaborati in un formato utilizzabile ( ad esempio, analisi di un documento PDF).
- Modalità di suddivisione dei documenti in blocchi più piccoli e modalità di formattazione dei blocchi (ad esempio, strategia di suddivisione in blocchi e dimensioni blocchi).
- I metadati (ad esempio il titolo della sezione o il titolo del documento) estratti su ogni documento e/o blocco. Modalità di inserimento di questi metadati (o non inclusi) in ogni blocco.
- Modello di incorporamento usato per convertire il testo in rappresentazioni vettoriali per la ricerca di somiglianza.
Catena RAG
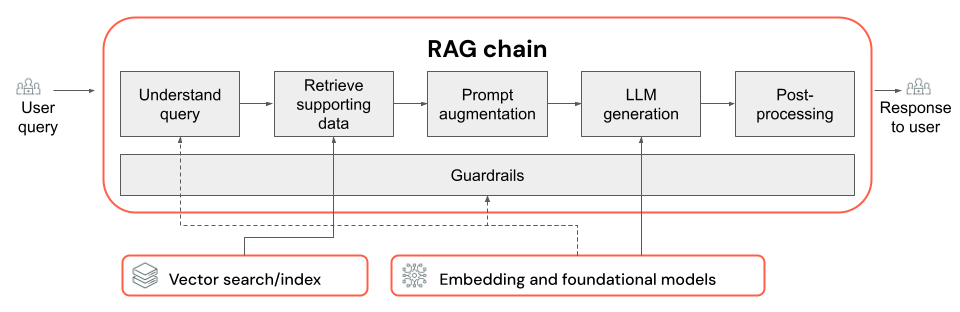
- Scelta di LLM e dei relativi parametri ( ad esempio, temperatura e max token).
- Parametri di recupero, ad esempio il numero di blocchi o documenti recuperati.
- Approccio di recupero (ad esempio, parola chiave e ricerca semantica ibrida o semantica, riscrittura della query dell'utente, trasformazione della query di un utente in filtri o nuova classificazione).
- Come formattare il prompt con il contesto recuperato per guidare l'LLM verso l'output di qualità.