Migliorare la qualità della catena RAG
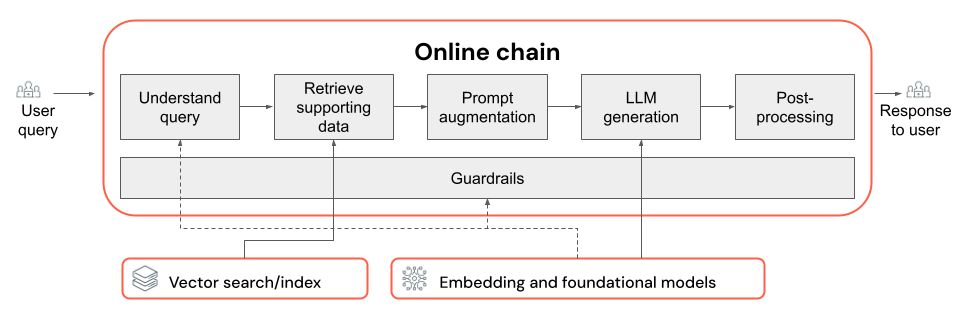
Questo articolo illustra come migliorare la qualità dell'app RAG usando i componenti della catena RAG.
La catena RAG accetta una query utente come input, recupera le informazioni pertinenti in base alla query e genera una risposta appropriata in base ai dati recuperati. Anche se i passaggi esatti all'interno di una catena RAG possono variare notevolmente a seconda del caso d'uso e dei requisiti, di seguito sono riportati i componenti chiave da considerare per la creazione della catena RAG:
- Informazioni sulle query: analisi e trasformazione delle query utente per rappresentare meglio le finalità ed estrarre informazioni pertinenti, ad esempio filtri o parole chiave, per migliorare il processo di recupero.
- Recupero: ricerca dei blocchi di informazioni più rilevanti in base a una query di recupero. Nel caso dei dati non strutturati, questo comporta in genere una o una combinazione di ricerca semantica o basata su parole chiave.
- Aumento prompt: combinazione di una query utente con informazioni recuperate e istruzioni per guidare l'LLM verso la generazione di risposte di alta qualità.
- LLM: selezionare il modello e i parametri del modello più appropriati per l'applicazione per ottimizzare/bilanciare le prestazioni, la latenza e i costi.
- Post-elaborazione e protezioni: applicazione di ulteriori passaggi di elaborazione e misure di sicurezza per garantire che le risposte generate dall'LLM siano on-topic, coerenti in modo effettivo e rispettino linee guida o vincoli specifici.
Implementare e valutare in modo iterativo correzioni di qualità mostra come scorrere i componenti di una catena.
Informazioni sulle query
L'uso della query utente direttamente come query di recupero può funzionare per alcune query. Tuttavia, in genere è utile riformulare la query prima del passaggio di recupero. La comprensione delle query comprende un passaggio (o una serie di passaggi) all'inizio di una catena per analizzare e trasformare le query utente per rappresentare meglio la finalità, estrarre le informazioni pertinenti e infine aiutare il processo di recupero successivo. Gli approcci alla trasformazione di una query utente per migliorare il recupero includono:
Riscrittura delle query: la riscrittura delle query comporta la conversione di una query utente in una o più query che rappresentano meglio la finalità originale. L'obiettivo è riformulare la query in modo da aumentare la probabilità che il passaggio di recupero trovi i documenti più rilevanti. Ciò può essere particolarmente utile quando si gestiscono query complesse o ambigue che potrebbero non corrispondere direttamente alla terminologia usata nei documenti di recupero.
Esempi:
- Parafrasare la cronologia delle conversazioni in una chat a più turni
- Correzione degli errori di ortografia nella query dell'utente
- Sostituzione di parole o frasi nella query dell'utente con sinonimi per acquisire un'ampia gamma di documenti pertinenti
Importante
La riscrittura delle query deve essere eseguita insieme alle modifiche apportate al componente di recupero
Estrazione di filtri: in alcuni casi, le query utente possono contenere filtri o criteri specifici che possono essere usati per restringere i risultati della ricerca. L'estrazione dei filtri comporta l'identificazione e l'estrazione di questi filtri dalla query e il passaggio al passaggio di recupero come parametri aggiuntivi. Ciò consente di migliorare la pertinenza dei documenti recuperati concentrandosi su subset specifici dei dati disponibili.
Esempi:
- Estrazione di periodi di tempo specifici indicati nella query, ad esempio "articoli degli ultimi 6 mesi" o "report dal 2023".
- Identificazione di menzioni di prodotti, servizi o categorie specifici nella query, ad esempio "Databricks Professional Services" o "portatili".
- Estrazione di entità geografiche dalla query, ad esempio nomi di città o codici paese.
Nota
L'estrazione dei filtri deve essere eseguita in combinazione con le modifiche apportate alla pipeline di dati di estrazione dei metadati e ai componenti della catena di recupero. Il passaggio di estrazione dei metadati deve garantire che i campi dei metadati pertinenti siano disponibili per ogni documento/blocco e che il passaggio di recupero debba essere implementato per accettare e applicare filtri estratti.
Oltre alla riscrittura delle query e all'estrazione di filtri, un'altra considerazione importante nella comprensione delle query consiste nell'usare una singola chiamata LLM o più chiamate. Anche se l'uso di una singola chiamata con una richiesta accuratamente creata può essere efficiente, esistono casi in cui suddividere il processo di comprensione delle query in più chiamate LLM può portare a risultati migliori. Questo, a proposito, è una regola generale applicabile quando si tenta di implementare una serie di passaggi logici complessi in un'unica richiesta.
Ad esempio, è possibile usare una chiamata LLM per classificare la finalità della query, un'altra per estrarre le entità pertinenti e una terza per riscrivere la query in base alle informazioni estratte. Anche se questo approccio può aggiungere una certa latenza al processo complessivo, può consentire un controllo più granulare e potenzialmente migliorare la qualità dei documenti recuperati.
Informazioni sulle query con più passaggi per un bot di supporto
Ecco come un componente di analisi delle query in più passaggi potrebbe cercare un bot di supporto clienti:
- Classificazione delle finalità: usare un LLM per classificare la query dell'utente in categorie predefinite, ad esempio "informazioni sul prodotto", "risoluzione dei problemi" o "gestione degli account".
- Estrazione di entità: in base alla finalità identificata, usare un'altra chiamata LLM per estrarre le entità pertinenti dalla query, ad esempio i nomi dei prodotti, gli errori segnalati o i numeri di account.
- Riscrittura delle query: usare la finalità estratta e le entità per riscrivere la query originale in un formato più specifico e mirato, ad esempio "La catena RAG non riesce a eseguire la distribuzione in Model Serving, viene visualizzato l'errore seguente...".
Recupero
Il componente di recupero della catena RAG è responsabile della ricerca dei blocchi di informazioni più rilevanti in base a una query di recupero. Nel contesto dei dati non strutturati, il recupero in genere implica una o una combinazione di ricerca semantica, ricerca basata su parole chiave e filtro dei metadati. La scelta della strategia di recupero dipende dai requisiti specifici dell'applicazione, dalla natura dei dati e dai tipi di query che si prevede di gestire. Confrontare le opzioni seguenti:
- Ricerca semantica: la ricerca semantica usa un modello di incorporamento per convertire ogni blocco di testo in una rappresentazione vettoriale che acquisisce il significato semantico. Confrontando la rappresentazione vettoriale della query di recupero con le rappresentazioni vettoriali dei blocchi, la ricerca semantica può recuperare documenti concettualmente simili, anche se non contengono le parole chiave esatte dalla query.
- Ricerca basata su parole chiave: la ricerca basata su parole chiave determina la pertinenza dei documenti analizzando la frequenza e la distribuzione delle parole condivise tra la query di recupero e i documenti indicizzati. Più spesso le stesse parole vengono visualizzate sia nella query che in un documento, maggiore è il punteggio di pertinenza assegnato a tale documento.
- Ricerca ibrida: la ricerca ibrida combina i punti di forza della ricerca semantica e basata su parole chiave usando un processo di recupero in due passaggi. In primo luogo, esegue una ricerca semantica per recuperare un set di documenti concettualmente pertinenti. Applica quindi la ricerca basata su parole chiave su questo set ridotto per perfezionare ulteriormente i risultati in base alle corrispondenze esatte delle parole chiave. Infine, combina i punteggi di entrambi i passaggi per classificare i documenti.
Confrontare le strategie di recupero
La tabella seguente contrasta ognuna di queste strategie di recupero tra loro:
| Ricerca semantica | Ricerca per parole chiave | Ricerca ibrida | |
|---|---|---|---|
| Spiegazione semplice | Se nella query e in un documento potenziale vengono visualizzati gli stessi concetti , sono rilevanti. | Se le stesse parole vengono visualizzate nella query e in un documento potenziale, sono rilevanti. Maggiore è il numero di parole della query nel documento, più rilevante è il documento. | Esegue sia una ricerca semantica che una ricerca di parole chiave, quindi combina i risultati. |
| Caso d'uso di esempio | Assistenza clienti in cui le query utente sono diverse dalle parole nei manuali del prodotto. Esempio: "Come attivare il telefono?" e la sezione manuale è denominata "attivazione/disattivazione della potenza". | Supporto clienti in cui le query contengono termini tecnici specifici e non descrittivi. Esempio: "Che cosa fa il modello HD7-8D?" | Query del supporto tecnico che combinano termini semantici e tecnici. Esempio: "Come si attiva HD7-8D?" |
| Approcci tecnici | Usa incorporamenti per rappresentare il testo in uno spazio vettoriale continuo, abilitando la ricerca semantica. | Si basa su metodi discreti basati su token come bag-of-words, TF-IDF, BM25 per la corrispondenza delle parole chiave. | Usare un approccio di rivalutazione per combinare i risultati, ad esempio la fusione di rango reciproco o un modello di rivalutazione. |
| Punti di forza | Recupero contestualmente di informazioni simili a una query, anche se le parole esatte non vengono usate. | Scenari che richiedono corrispondenze di parole chiave precise, ideali per query specifiche incentrate sui termini, ad esempio i nomi dei prodotti. | Combina il meglio di entrambi gli approcci. |
Modi per migliorare il processo di recupero
Oltre a queste strategie di recupero principali, esistono diverse tecniche che è possibile applicare per migliorare ulteriormente il processo di recupero:
- Espansione delle query: l'espansione delle query consente di acquisire un'ampia gamma di documenti pertinenti usando più varianti della query di recupero. A tale scopo, è possibile eseguire singole ricerche per ogni query espansa o usare una concatenazione di tutte le query di ricerca espanse in una singola query di recupero.
Nota
L'espansione delle query deve essere eseguita insieme alle modifiche apportate al componente di analisi delle query (catena RAG). In questo passaggio vengono in genere generate più varianti di una query di recupero.
- Re-ranking: dopo aver recuperato un set iniziale di blocchi, applicare criteri di classificazione aggiuntivi (ad esempio, ordinare in base al tempo) o un modello reranker per riordinare i risultati. La rivalutazione può aiutare a classificare in ordine di priorità i blocchi più rilevanti in base a una query di recupero specifica. La reranking con modelli di codificatore incrociato come mxbai-rerank e ColBERTv2 può produrre un aumento delle prestazioni di recupero.
- Filtro dei metadati: usare i filtri di metadati estratti dal passaggio di analisi delle query per limitare lo spazio di ricerca in base a criteri specifici. I filtri di metadati possono includere attributi come tipo di documento, data di creazione, autore o tag specifici del dominio. Combinando i filtri di metadati con la ricerca semantica o basata su parole chiave, è possibile creare un recupero più mirato ed efficiente.
Nota
Il filtro dei metadati deve essere eseguito insieme alle modifiche apportate ai componenti di analisi delle query (catena RAG) e all'estrazione dei metadati (pipeline di dati).
Aumento delle richieste
L'aumento delle richieste è il passaggio in cui la query utente viene combinata con le informazioni recuperate e le istruzioni in un modello di richiesta per guidare il modello linguistico verso la generazione di risposte di alta qualità. L'iterazione su questo modello per ottimizzare la richiesta fornita all'LLM (AKA prompt engineering) è necessaria per garantire che il modello sia guidato per produrre risposte accurate, a terra e coerenti.
Esistono intere guide per richiedere la progettazione, ma di seguito sono riportate alcune considerazioni da tenere presenti quando si esegue l'iterazione sul modello di richiesta:
- Fornire esempi
- Includere esempi di query ben formate e le risposte ideali corrispondenti all'interno del modello di richiesta stesso (apprendimento con pochi scatti). Ciò consente al modello di comprendere il formato, lo stile e il contenuto desiderati delle risposte.
- Un modo utile per trovare esempi validi consiste nell'identificare i tipi di query con cui la catena ha difficoltà. Creare risposte standard gold per tali query e includerle come esempi nel prompt.
- Assicurarsi che gli esempi forniti siano rappresentativi delle query utente previste in fase di inferenza. Mirare a coprire un'ampia gamma di query previste per semplificare la generalizzazione del modello.
- Parametrizzare il modello di richiesta
- Progettare il modello di richiesta in modo che sia flessibile parametrizzandolo per incorporare informazioni aggiuntive oltre ai dati recuperati e alla query dell'utente. Può trattarsi di variabili come data corrente, contesto utente o altri metadati pertinenti.
- L'inserimento di queste variabili nella richiesta in fase di inferenza può abilitare risposte più personalizzate o con riconoscimento del contesto.
- Prendere in considerazione la richiesta di concatenamento
- Per le query complesse in cui le risposte dirette non sono facilmente evidenti, prendere in considerazione il prompt chain-of-thought (CoT). Questa strategia di progettazione prompt suddivide le domande complesse in passaggi più semplici e sequenziali, guidando l'LLM attraverso un processo logico di ragionamento.
- Richiedendo al modello di "esaminare il problema in modo dettagliato", è consigliabile fornire risposte più dettagliate e ben ragionate, che possono essere particolarmente efficaci per la gestione di query in più passaggi o aperte.
- I prompt potrebbero non essere trasferiti tra modelli
- Riconoscere che le richieste spesso non vengono trasferite facilmente tra modelli linguistici diversi. Ogni modello ha le proprie caratteristiche univoche in cui un prompt funziona bene per un modello potrebbe non essere così efficace per un altro.
- Sperimentare diversi formati di richiesta e lunghezze, fare riferimento a guide online (ad esempio OpenAI Cookbook, cookbook anthropic) e essere pronti ad adattare e perfezionare le richieste quando si passa da un modello all'altro.
LLM
Il componente di generazione della catena RAG accetta il modello di richiesta aumentata dal passaggio precedente e lo passa a un LLM. Quando si seleziona e si ottimizza un LLM per il componente di generazione di una catena RAG, considerare i fattori seguenti, che sono ugualmente applicabili a qualsiasi altro passaggio che comporta chiamate LLM:
- Provare a usare modelli diversi off-the-shelf.
- Ogni modello ha proprietà, punti di forza e punti deboli univoci. Alcuni modelli possono avere una migliore comprensione di determinati domini o prestazioni migliori in attività specifiche.
- Come accennato in precedenza, tenere presente che la scelta del modello può anche influenzare il processo di progettazione delle richieste, in quanto modelli diversi possono rispondere in modo diverso alle stesse richieste.
- Se nella catena sono presenti più passaggi che richiedono un LLM, ad esempio chiamate per la comprensione delle query oltre al passaggio di generazione, è consigliabile usare modelli diversi per passaggi diversi. I modelli di utilizzo generico più costosi possono essere eccessivamente avanzati per le attività, ad esempio per determinare la finalità di una query utente.
- Avviare piccole dimensioni e aumentare le prestazioni in base alle esigenze.
- Anche se può essere tentata di raggiungere immediatamente i modelli più potenti e capaci disponibili (ad esempio GPT-4, Claude), è spesso più efficiente iniziare con modelli più piccoli e più leggeri.
- In molti casi, alternative open source più piccole come Llama 3 o DBRX possono fornire risultati soddisfacenti a un costo inferiore e con tempi di inferenza più rapidi. Questi modelli possono essere particolarmente efficaci per le attività che non richiedono un ragionamento estremamente complesso o un'ampia conoscenza globale.
- Durante lo sviluppo e l'affinamento della catena RAG, valutare continuamente le prestazioni e le limitazioni del modello scelto. Se si rileva che il modello ha difficoltà con determinati tipi di query o non riesce a fornire risposte sufficientemente dettagliate o accurate, è consigliabile aumentare le prestazioni fino a un modello più idoneo.
- Monitorare l'impatto della modifica dei modelli sulle metriche chiave, ad esempio la qualità della risposta, la latenza e i costi, per assicurarsi di raggiungere il giusto equilibrio per i requisiti del caso d'uso specifico.
- Ottimizzare i parametri del modello
- Sperimentare diverse impostazioni dei parametri per trovare l'equilibrio ottimale tra qualità della risposta, diversità e coerenza. Ad esempio, la regolazione della temperatura può controllare la casualità del testo generato, mentre max_tokens può limitare la lunghezza della risposta.
- Tenere presente che le impostazioni dei parametri ottimali possono variare a seconda dell'attività, della richiesta e dello stile di output desiderato. Testare e perfezionare queste impostazioni in modo iterativo in base alla valutazione delle risposte generate.
- Ottimizzazione specifica dell'attività
- Man mano che si ottimizzano le prestazioni, è consigliabile ottimizzare i modelli più piccoli per attività secondarie specifiche all'interno della catena rag, ad esempio la comprensione delle query.
- Eseguendo il training di modelli specializzati per singole attività con la catena RAG, è possibile migliorare potenzialmente le prestazioni complessive, ridurre la latenza e ridurre i costi di inferenza rispetto all'uso di un singolo modello di grandi dimensioni per tutte le attività.
- Formazione preliminare continua
- Se l'applicazione RAG gestisce un dominio specializzato o richiede conoscenze non ben rappresentate nell'LLM con training preliminare, è consigliabile eseguire il pre-training continuo (CPT) sui dati specifici del dominio.
- La pre-training continua può migliorare la comprensione di un modello di terminologia o concetti specifici univoci per il dominio. A sua volta questo può ridurre la necessità di un'ampia progettazione di richieste o esempi di pochi scatti.
Post-elaborazione e protezioni
Dopo che LLM genera una risposta, è spesso necessario applicare tecniche di post-elaborazione o protezioni per garantire che l'output soddisfi i requisiti di formato, stile e contenuto desiderati. Questo passaggio finale (o più passaggi) nella catena può contribuire a mantenere la coerenza e la qualità tra le risposte generate. Se si implementano post-elaborazione e protezioni, considerare alcuni dei seguenti aspetti:
- Applicazione del formato di output
- A seconda del caso d'uso, è possibile che le risposte generate siano conformi a un formato specifico, ad esempio un modello strutturato o un particolare tipo di file (ad esempio JSON, HTML, Markdown e così via).
- Se è necessario un output strutturato, le librerie come Instructor o Outlines forniscono buoni punti di partenza per implementare questo tipo di passaggio di convalida.
- Durante lo sviluppo, dedicare tempo per garantire che il passaggio di post-elaborazione sia sufficientemente flessibile da gestire le variazioni nelle risposte generate mantenendo il formato richiesto.
- Mantenimento della coerenza dello stile
- Se l'applicazione RAG ha specifiche linee guida di stile o requisiti di tono (ad esempio, formali e casuali, concisi e dettagliati), un passaggio di post-elaborazione può controllare e applicare questi attributi di stile tra le risposte generate.
- Filtri di contenuto e protezioni per la sicurezza
- A seconda della natura dell'applicazione RAG e dei potenziali rischi associati al contenuto generato, può essere importante implementare filtri di contenuto o protezioni di sicurezza per impedire l'output di informazioni inappropriate, offensive o dannose.
- Prendere in considerazione l'uso di modelli come Llama Guard o API appositamente progettate per la con modalità tenda ration e la sicurezza, ad esempio l'API di moderazione di OpenAI, per implementare protezioni di sicurezza.
- Gestione delle allucinazioni
- La difesa contro le allucinazioni può essere implementata anche come passaggio post-elaborazione. Ciò può comportare l'esecuzione di riferimenti incrociati all'output generato con documenti recuperati o l'uso di llms aggiuntivi per convalidare l'accuratezza effettiva della risposta.
- Sviluppare meccanismi di fallback per gestire i casi in cui la risposta generata non soddisfa i requisiti di accuratezza effettiva, ad esempio la generazione di risposte alternative o la fornitura di dichiarazioni di non responsabilità all'utente.
- Gestione degli errori
- Con qualsiasi procedura di post-elaborazione, implementare meccanismi per gestire correttamente i casi in cui il passaggio rileva un problema o non riesce a generare una risposta soddisfacente. Ciò potrebbe comportare la generazione di una risposta predefinita o l'escalation del problema a un operatore umano per la revisione manuale.