Azure HDInsight è uno dei servizi più diffusi fra i clienti enterprise per analisi open source in Azure.
Sottoscrivere le note sulla versione di HDInsight per informazioni aggiornate su HDInsight e su tutte le versioni di HDInsight.
Per eseguire la sottoscrizione, fare clic sul pulsante "Watch" nel banner e seguire le versioni di HDInsight.
Informazioni sulla versione
Data di rilascio: 30 agosto 2024
Nota
Si tratta di una versione hotfix/manutenzione per il provider di risorse. Per altre informazioni, vedere Provider di risorse.
Azure HDInsight rilascia periodicamente gli aggiornamenti di manutenzione per la distribuzione di correzioni di bug, miglioramenti delle prestazioni e patch di sicurezza, consentendo all'utente di rimanere al passo con questi aggiornamenti e garantendo prestazioni e affidabilità ottimali.
Questa nota sulla versione si applica a
HDInsight versione 5.1.
HDInsight versione 5.0.
HDInsight versione 4.0.
La versione di HDInsight sarà disponibile in tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2407260448. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Il 31 agosto 2024 verranno ritirate le VM di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle VM serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD.
Siamo in ascolto: è possibile aggiungere altre idee e altri argomenti e votarli in HDInsight Ideas e seguirci per altri aggiornamenti nella community di AzureHDInsight.
Nota
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Data di rilascio: 09 agosto 2024
Questa nota sulla versione si applica a
HDInsight versione 5.1.
HDInsight versione 5.0.
HDInsight versione 4.0.
La versione di HDInsight sarà disponibile in tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2407260448. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
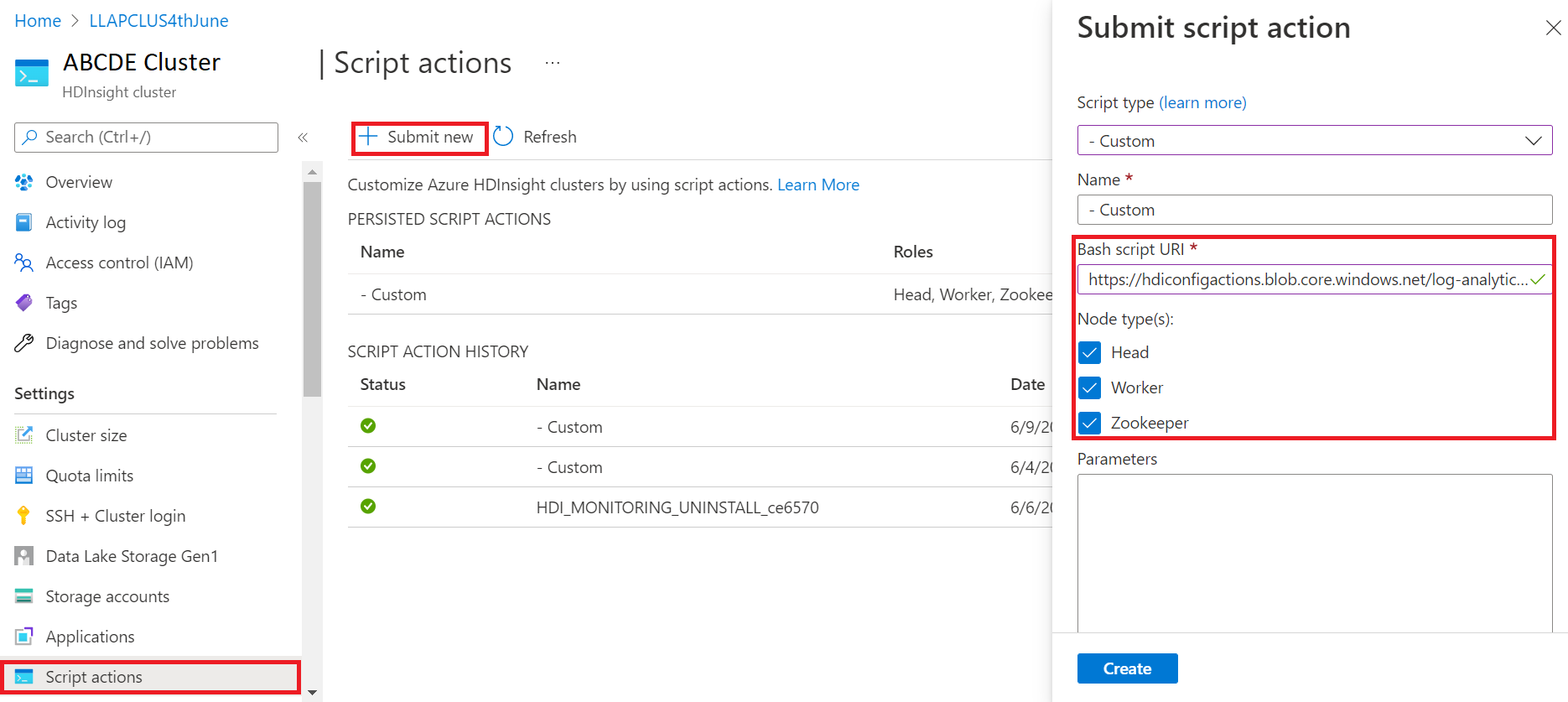
Il numero di immagine effettivo 2407260448, i clienti che usano il portale per Log Analytics avranno l'esperienza predefinita dell'agente di Monitoraggio di Azure. Se si vuole passare all'esperienza di Monitoraggio di Azure (anteprima), è possibile aggiungere i cluster alle immagini precedenti creando una richiesta di supporto.
Data di rilascio: 05 luglio 2024
Nota
Si tratta di una versione hotfix/manutenzione per il provider di risorse. Per altre informazioni, vedere Provider di risorse
Problemi risolti
I tag HOBO sovrascrivono i tag utente.
I tag HOBO sovrascrivono i tag utente nelle risorse secondarie nella creazione del cluster HDInsight.
Data di rilascio: 19 giugno 2024
Questa nota sulla versione si applica a
HDInsight versione 5.1.
HDInsight versione 5.0.
HDInsight versione 4.0.
La versione di HDInsight sarà disponibile in tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2406180258. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Miglioramenti all'uso dei tag per i cluster in linea con i requisiti SFI.
Miglioramenti apportati agli script dei probe in base ai requisiti SFI.
Miglioramenti in HDInsight Log Analytics con il supporto dell'identità gestita dal sistema per il provider di risorse HDInsight.
Aggiunta di una nuova attività per aggiornare la versione dell'agente mdsd per l'immagine vecchia (creata prima del 2024).
Abilitazione di MISE nel gateway come parte dei miglioramenti continui per la Migrazione MSAL.
Incorporare Spark Thrift Server Httpheader hiveConf in Jetty HTTP ConnectionFactory.
Ripristinare RANGER-3753 e RANGER-3593.
L'implementazione setOwnerUser fornita nella versione di Ranger 2.3.0 presenta un problema critico di regressione quando viene usata da Hive. In Ranger 2.3.0, quando HiveServer2 tenta di valutare i criteri, Ranger Client tenta di ottenere il proprietario della tabella hive chiamando il Metastore nella funzione setOwnerUser che essenzialmente effettua una chiamata all'archiviazione per verificare l'accesso per tale tabella. Questo problema causa un rallentamento dell'esecuzione delle query quando Hive viene eseguito su Ranger 2.3.0.
Il 31 agosto 2024 verranno ritirate le VM di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle VM serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD.
Siamo in ascolto: è possibile aggiungere altre idee e altri argomenti e votarli in HDInsight Ideas e seguirci per altri aggiornamenti nella community di AzureHDInsight.
Nota
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Data di rilascio: 16 maggio 2024
Questa nota sulla versione si applica a
HDInsight 5.0 versione.
HDInsight versione 4.0.
La versione di HDInsight sarà disponibile per tutte le aree in diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2405081840. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Aggiunta dell'API nel gateway per ottenere il token per KeyVault, come parte dell'iniziativa SFI.
Nella nuova tabella HDInsightSparkLogs Monitoraggio log, per il tipo di log SparkDriverLog, alcuni dei campi erano mancanti. Ad esempio: LogLevel & Message. Questa versione aggiunge i campi mancanti agli schemi e alla formattazione fissa per SparkDriverLog.
I log livy non sono disponibili nella tabella di monitoraggio SparkDriverLog di Log Analytics, a causa di un problema relativo al percorso di origine del log Livy e all'analisi dei log nelle configurazioni SparkLivyLog.
Qualsiasi cluster HDInsight che usa ADLS Gen2 come account di archiviazione primario può sfruttare l'accesso basato su MSI a qualsiasi risorsa di Azure (ad esempio SQL, Keyvaults) usata all'interno del codice dell'applicazione.
Il 31 agosto 2024 verranno ritirate le VM di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle VM serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD.
Siamo in ascolto: è possibile aggiungere altre idee e altri argomenti e votarli in HDInsight Ideas e seguirci per altri aggiornamenti nella community di AzureHDInsight.
Nota
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Data di rilascio: 15 aprile 2024
Questa nota sulla versione si applica a HDInsight versione 5.1.
La versione di HDInsight sarà disponibile in tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2403290825. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 5.1: Ubuntu 18.04.5 LTS Kernel Linux 5.4
Il 31 agosto 2024 verranno ritirate le VM di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle VM serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD.
Siamo in ascolto: è possibile aggiungere altre idee e altri argomenti e votarli in HDInsight Ideas e seguirci per altri aggiornamenti nella community di AzureHDInsight.
Nota
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Data di rilascio: 15 febbraio 2024
Questa versione si applica alle versioni di HDInsight 4.x e 5.x. La versione di HDInsight sarà disponibile in tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2401250802. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 4.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.1: Ubuntu 18.04.5 LTS Kernel Linux 5.4
Supporto di Apache Ranger per Spark SQL in Spark 3.3.0 (HDInsight versione 5.1) con Enterprise Security Package. Per altre informazioni, vedere qui.
Problemi risolti
Correzioni di sicurezza dei componenti di Ambari e Oozie
Prossimamente
Ritiro VM di serie A Basic e Standard.
Il 31 agosto 2024 verranno ritirate le VM di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle VM serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD.
Per evitare interruzioni del servizio, eseguire la migrazione dei carichi di lavoro dalle macchine virtuali serie A Basic e Standard alle macchine virtuali serie Av2 prima del 31 agosto 2024.
Siamo in ascolto: è possibile aggiungere altre idee e proporre altri argomenti, votarli in HDInsight Ideas e seguirci per altri aggiornamenti nella community di AzureHDInsight
Nota
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Azure HDInsight è uno dei servizi più diffusi fra i clienti enterprise per analisi open source in Azure.
Se si vogliono sottoscrivere le note sulla versione, seguire questo repository GitHub.
Data di rilascio: 10 gennaio 2024
Questa versione hotfix si applica alle versioni di HDInsight 4.x e 5.x. La versione di HDInsight sarà disponibile in tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2401030422. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 4.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.1: Ubuntu 18.04.5 LTS Kernel Linux 5.4
Correzioni di sicurezza dei componenti di Ambari e Oozie
Prossimamente
Ritiro VM di serie A Basic e Standard.
Il 31 agosto 2024 verranno ritirate le VM di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle VM serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD.
Per evitare interruzioni del servizio, eseguire la migrazione dei carichi di lavoro dalle macchine virtuali serie A Basic e Standard alle macchine virtuali serie Av2 prima del 31 agosto 2024.
Siamo in ascolto: è possibile aggiungere altre idee e proporre altri argomenti, votarli in HDInsight Ideas e seguirci per altri aggiornamenti nella community di AzureHDInsight
Nota
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Data di rilascio: 26 ottobre 2023
Questa versione si applica alle versioni di HDInsight 4.x e 5.x. HDInsight sarà disponibile per tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2310140056. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 4.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.1: Ubuntu 18.04.5 LTS Kernel Linux 5.4
Per le versioni specifiche del carico di lavoro, vedere
HDInsight annuncia la disponibilità generale di HDInsight 5.1 a partire dal 1° novembre 2023. Questa versione introduce un aggiornamento completo dello stack per i componenti open source e le integrazioni di Microsoft.
Ultime versioni open source - HDInsight 5.1 include la versione open source stabile più recente disponibile. I clienti possono trarre vantaggio da tutte le funzionalità open source più recenti, dai miglioramenti delle prestazioni di Microsoft e dalle correzioni di bug.
Sicuro - Le ultime versioni sono dotate delle correzioni di sicurezza più recenti, sia delle correzioni di sicurezza open source che dei miglioramenti della sicurezza di Microsoft.
TCO inferiore - Grazie ai miglioramenti delle prestazioni, i clienti possono ridurre il costo di proprietà con la scalabilità automatica avanzata.
Autorizzazioni del cluster per l'archiviazione sicura
I clienti possono specificare durante la creazione del cluster se per la connessione dei nodi del cluster HDInsight all'account di archiviazione occorre usare un canale sicuro.
Creazione di cluster HDInsight con reti virtuali personalizzate.
Per migliorare la postura di sicurezza complessiva dei cluster HDInsight, i cluster HDInsight che usano reti virtuali personalizzate devono verificare che l'utente debba avere l'autorizzazione per Microsoft Network/virtualNetworks/subnets/join/action per eseguire operazioni di creazione. Se questo controllo non è abilitato, il cliente potrebbe riscontrare errori di creazione.
Cluster ABFS non ESP [Autorizzazioni cluster per Word leggibile]
I cluster ABFS non ESP impediscono agli utenti di gruppo non Hadoop di eseguire comandi Hadoop per le operazioni di archiviazione. Questa modifica migliora la postura di sicurezza del cluster.
Aggiornamento della quota inline.
Ora è possibile richiedere un aumento della quota direttamente dalla pagina Quota personale. Con la chiamata API diretta, l'operazione è molto più veloce. Nel caso in cui la chiamata API non riesca, è possibile creare una nuova richiesta di supporto per l'aumento della quota.
Prossimamente
La lunghezza massima del nome del cluster viene modificata in 45 da 59 caratteri, per migliorare il comportamento di sicurezza dei cluster. Questa modifica verrà implementata in tutte le aree a partire dalla prossima versione.
Ritiro delle macchine virtuali di serie A Basic e Standard.
Il 31 agosto 2024 verranno ritirate le macchine virtuali di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle macchine virtuali serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD.
Per evitare interruzioni del servizio, eseguire la migrazione dei carichi di lavoro dalle macchine virtuali serie A Basic e Standard alle macchine virtuali serie Av2 prima del 31 agosto 2024.
Siamo in ascolto: è possibile aggiungere altre idee e proporre altri argomenti, votarli in HDInsight Ideas e seguirci per altri aggiornamenti nella community di AzureHDInsight
Nota
Questa versione risolve le CVE seguenti pubblicate da MSRC il 12 settembre 2023. L'azione è l'aggiornamento all'immagine più recente 2308221128 o 2310140056. I clienti sono invitati a pianificare di conseguenza.
Altitudine dell'Utilità di pianificazione del flusso di lavoro Apache Oozie per Azure HDInsight di vulnerabilità del privilegio
Applicare l'azione Script nei cluster o eseguire l'aggiornamento all'immagine 2310140056
Nota
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Data di rilascio: 7 settembre 2023
Questa versione si applica alle versioni di HDInsight 4.x e 5.x. HDInsight sarà disponibile per tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2308221128. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 4.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.1: Ubuntu 18.04.5 LTS Kernel Linux 5.4
Per le versioni specifiche del carico di lavoro, vedere
Questa versione risolve le CVE seguenti pubblicate da MSRC il 12 settembre 2023. L'azione è l'aggiornamento all'immagine più recente 2308221128. I clienti sono invitati a pianificare di conseguenza.
La lunghezza massima del nome del cluster viene modificata in 45 da 59 caratteri, per migliorare il comportamento di sicurezza dei cluster. Questa modifica verrà implementata entro il 30 settembre 2023.
Autorizzazioni del cluster per l'archiviazione sicura
I clienti possono specificare durante la creazione del cluster se i nodi del cluster HDInsight devono usare un canale sicuro per contattare l'account di archiviazione.
Aggiornamento della quota inline.
È possibile richiedere un aumento della quota direttamente dalla pagina Quota personale. Si tratterà di una chiamata API diretta, che è più veloce. Se la chiamata APdI ha esito negativo, i clienti devono creare una nuova richiesta di supporto per l'aumento della quota.
Creazione di cluster HDInsight con reti virtuali personalizzate.
Per migliorare la postura di sicurezza complessiva dei cluster HDInsight, i cluster HDInsight che usano reti virtuali personalizzate devono verificare che l'utente debba avere l'autorizzazione per Microsoft Network/virtualNetworks/subnets/join/action per eseguire operazioni di creazione. I clienti devono tenerne conto per la pianificazione, in quanto questa modifica sarebbe un controllo obbligatorio per evitare errori di creazione del cluster prima del 30 settembre 2023.
Ritiro delle macchine virtuali di serie A Basic e Standard.
Il 31 agosto 2024 verranno ritirate le VM di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle VM serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD. Per evitare interruzioni del servizio, eseguire la migrazione dei carichi di lavoro dalle macchine virtuali serie A Basic e Standard alle macchine virtuali serie Av2 prima del 31 agosto 2024.
Cluster ABFS non ESP [Autorizzazioni cluster per la leggibilità generale]
È prevista l'introduzione di una modifica nei cluster ABFS non ESP per impedire agli utenti di gruppo non Hadoop di eseguire comandi Hadoop per le operazioni di archiviazione. Questa modifica migliora la postura di sicurezza del cluster. I clienti devono pianificare gli aggiornamenti prima del 30 settembre 2023.
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Data di rilascio: 25 luglio 2023
Questa versione si applica alle versioni di HDInsight 4.x e 5.x. HDInsight sarà disponibile per tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2307201242. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 4.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.1: Ubuntu 18.04.5 LTS Kernel Linux 5.4
Per le versioni specifiche del carico di lavoro, vedere
Questa versione risolve le CVE seguenti pubblicate da MSRC l'8 agosto 2023. L'azione è l'aggiornamento all'immagine più recente 2307201242. I clienti sono invitati a pianificare di conseguenza.
Vulnerabilità di spoofing di Apache Hadoop in Azure
Prossimamente
La lunghezza massima del nome del cluster viene modificata in 45 da 59 caratteri, per migliorare il comportamento di sicurezza dei cluster. I clienti devono pianificare gli aggiornamenti prima del 30 settembre 2023.
Autorizzazioni del cluster per l'archiviazione sicura
I clienti possono specificare durante la creazione del cluster se i nodi del cluster HDInsight devono usare un canale sicuro per contattare l'account di archiviazione.
Aggiornamento della quota inline.
È possibile richiedere un aumento della quota direttamente dalla pagina Quota personale. Si tratterà di una chiamata API diretta, che è più veloce. Se la chiamata API ha esito negativo, i clienti devono creare una nuova richiesta di supporto per l'aumento della quota.
Creazione di cluster HDInsight con reti virtuali personalizzate.
Per migliorare la postura di sicurezza complessiva dei cluster HDInsight, i cluster HDInsight che usano reti virtuali personalizzate devono verificare che l'utente debba avere l'autorizzazione per Microsoft Network/virtualNetworks/subnets/join/action per eseguire operazioni di creazione. I clienti dovranno pianificare di conseguenza in quanto questa modifica sarebbe un controllo obbligatorio per evitare errori di creazione del cluster prima del 30 settembre 2023.
Ritiro delle macchine virtuali di serie A Basic e Standard.
Il 31 agosto 2024 verranno ritirate le macchine virtuali di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle macchine virtuali serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD. Per evitare interruzioni del servizio, eseguire la migrazione dei carichi di lavoro dalle macchine virtuali serie A Basic e Standard alle macchine virtuali serie Av2 prima del 31 agosto 2024.
Cluster ABFS non ESP [Autorizzazioni cluster per la leggibilità generale]
È prevista l'introduzione di una modifica nei cluster ABFS non ESP per impedire agli utenti di gruppo non Hadoop di eseguire comandi Hadoop per le operazioni di archiviazione. Questa modifica migliora la postura di sicurezza del cluster. I clienti devono pianificare gli aggiornamenti prima del 30 settembre 2023.
Qui è possibile aggiungere altre proposte, idee e altri argomenti; oltre a votarli - Community di HDInsight (azure.com); per altri aggiornamenti è possibile seguirci su X
Nota
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Data di rilascio: 08 maggio 2023
Questa versione si applica alle versioni di HDInsight 4.x e 5.x. HDInsight è disponibile in tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2304280205. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 4.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
Per le versioni specifiche del carico di lavoro, vedere
Tutti i componenti sono integrati con Hadoop 3.3.4 e ZK 3.6.3
Tutti i componenti aggiornati precedenti sono ora disponibili nei cluster non ESP per l'anteprima pubblica.
Scalabilità automatica avanzata per HDInsight
Azure HDInsight ha apportato notevoli miglioramenti alla stabilità e alla latenza sulla scalabilità automatica. Le modifiche essenziali includono un ciclo di feedback migliorato per le decisioni di ridimensionamento, un miglioramento significativo della latenza per il ridimensionamento e il supporto per il ripristino dei nodi rimossi. Qui sono disponibili altre informazioni sui miglioramenti e su come personalizzare la configurazione del cluster ed eseguirne la migrazione per usufruire della scalabilità automatica avanzata. La funzionalità di scalabilità automatica avanzata è disponibile a partire dal 17 maggio 2023 in tutte le aree supportate.
Azure HDInsight ESP per Apache Kafka 2.4.1 è ora disponibile a livello generale.
Azure HDInsight ESP per Apache Kafka 2.4.1 è disponibile in anteprima pubblica a partire da aprile 2022. Dopo miglioramenti significativi nella stabilità e nelle correzioni CVE, Azure HDInsight ESP per Kafka 2.4.1 è ora disponibile a livello generale e pronto per i carichi di lavoro di produzione. Leggere le informazioni dettagliate sulla configurazione e la migrazione.
Gestione della quota per HDInsight
Attualmente HDInsight alloca la quota alle sottoscrizioni dei clienti a livello di area. I core allocati ai clienti sono generici e non classificati a livello di famiglia di macchine virtuali (ad esempio, Dv2, Ev3, Eav4 e così via).
HDInsight ha introdotto una visualizzazione migliorata, che mostra i dettagli e la classificazione delle quote per le macchine virtuali a livello di famiglia. Questa funzionalità consente ai clienti di visualizzare le quote correnti e rimanenti per un'area a livello di famiglia di VM. Con la visualizzazione migliorata, i clienti usufruiscono di una visibilità più ampia per la pianificazione delle quote e di un'esperienza utente migliore. Questa funzionalità è attualmente disponibile in HDInsight 4.x e 5.x per l'area Stati Uniti orientali (EUAP). Altre aree seguiranno più avanti.
La lunghezza massima del nome del cluster cambia da 59 a 45 caratteri per migliorare la postura di sicurezza dei cluster.
Autorizzazioni del cluster per l'archiviazione sicura
I clienti possono specificare durante la creazione del cluster se i nodi del cluster HDInsight devono usare un canale sicuro per contattare l'account di archiviazione.
Aggiornamento della quota inline.
È possibile richiedere un aumento della quota direttamente dalla pagina Quota personale. Si tratta di una chiamata API diretta, che è più veloce. Se la chiamata API ha esito negativo, i clienti devono creare una nuova richiesta di supporto per l'aumento della quota.
Creazione di cluster HDInsight con reti virtuali personalizzate.
Per migliorare la postura di sicurezza complessiva dei cluster HDInsight, i cluster HDInsight che usano reti virtuali personalizzate devono verificare che l'utente debba avere l'autorizzazione per Microsoft Network/virtualNetworks/subnets/join/action per eseguire operazioni di creazione. I clienti devono pianificare di conseguenza, in quanto si tratta di un controllo obbligatorio per evitare errori di creazione del cluster.
Ritiro delle macchine virtuali di serie A Basic e Standard.
Il 31 agosto 2024 verranno ritirate le macchine virtuali di serie A Basic e Standard. Prima di tale data, è necessario eseguire la migrazione dei carichi di lavoro alle macchine virtuali serie Av2, che offrono una maggiore quantità di memoria per vCPU e un'archiviazione più veloce su unità SSD. Per evitare interruzioni del servizio, eseguire la migrazione dei carichi di lavoro dalle macchine virtuali serie A Basic e Standard alle macchine virtuali serie Av2 prima del 31 agosto 2024.
Cluster ABFS non ESP [Autorizzazioni cluster per la leggibilità generale]
È prevista l'introduzione di una modifica nei cluster ABFS non ESP per impedire agli utenti di gruppo non Hadoop di eseguire comandi Hadoop per le operazioni di archiviazione. Questa modifica migliora la postura di sicurezza del cluster. I clienti devono pianificare gli aggiornamenti.
Data di rilascio: 28 febbraio 2023
Questa versione si applica a HDInsight 4.0. e 5.0, 5.1. La versione di HDInsight è disponibile per tutte le aree per diversi giorni. Questa nota sulla versione è applicabile per il numero di immagine 2302250400. Come controllare il numero di immagine?
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 4.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
Per le versioni specifiche del carico di lavoro, vedere
Microsoft ha rilasciato CVE-2023-23408, che è stato risolto nella versione corrente. I clienti sono invitati ad aggiornare i cluster all'immagine più recente.
HDInsight 5.1
È stata avviata l'implementazione di una nuova versione di HDInsight 5.1. Tutte le nuove versioni open source sono state aggiunte come versioni incrementali in HDInsight 5.1.
Kafka 3.2.0 include diverse nuove funzionalità e miglioramenti significativi.
Aggiornamento di Zookeeper alla versione 3.6.3
Supporto di Kafka Streams
Garanzie di recapito superiori per il producer Kafka abilitate per impostazione predefinita.
log4j 1.x è stato sostituito con reload4j.
Invio un suggerimento al leader della partizione per recuperare la partizione.
JoinGroupRequest e LeaveGroupRequest hanno un motivo collegato.
Aggiunta delle metriche di conteggio broker8.
Miglioramenti del mirroring Maker2.
Aggiornamento di HBase 2.4.11 (anteprima)
Questa versione include nuove funzionalità, tra cui l'aggiunta di nuovi tipi di meccanismi di memorizzazione nella cache a blocchi e la possibilità di modificare hbase:meta table e visualizzare la tabella hbase:meta dall'interfaccia utente Web di HBase.
Aggiornamento di Phoenix 5.1.2 (anteprima)
In questa versione, Phoenix è stato aggiornato alla versione 5.1.2. Questo aggiornamento include Phoenix Query Server. Phoenix Query Server offre un proxy per il driver JDBC Phoenix standard e fornisce un protocollo di trasmissione compatibile con le versioni precedenti per richiamare tale driver JDBC.
CVE di Ambari
Sono stati corretti più CVE di Ambari.
Nota
ESP non è supportato per Kafka e HBase in questa versione.
Passaggi successivi
Autoscale
Scalabilità automatica con una latenza inferiore e diversi miglioramenti
Limitazione della modifica del nome del cluster
La lunghezza massima del nome del cluster passa da 59 a 45 nei cloud Pubblico, Azure Cina e Azure per enti pubblici.
Autorizzazioni del cluster per l'archiviazione sicura
I clienti possono specificare durante la creazione del cluster se i nodi del cluster HDInsight devono usare un canale sicuro per contattare l'account di archiviazione.
Cluster ABFS non ESP [Autorizzazioni cluster per la leggibilità generale]
È prevista l'introduzione di una modifica nei cluster ABFS non ESP per impedire agli utenti di gruppo non Hadoop di eseguire comandi Hadoop per le operazioni di archiviazione. Questa modifica migliora la postura di sicurezza del cluster. I clienti devono pianificare gli aggiornamenti.
Aggiornamenti open source
Apache Spark 3.3.0 e Hadoop 3.3.4 sono in fase di sviluppo in HDInsight 5.1 e includono diverse nuove funzionalità, prestazioni e altri miglioramenti significativi.
Nota
È consigliabile che i clienti usino le versioni più recenti di HDInsight Images perché consentono di ottenere gli aggiornamenti open source, gli aggiornamenti di Azure e le correzioni di sicurezza migliori. Per altre informazioni, vedere Procedure consigliate.
Data di rilascio: 12 dicembre 2022
Questa versione si applica a HDInsight 4.0. e la versione di HDInsight 5.0 è resa disponibile per tutte le aree in diversi giorni.
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Versioni del sistema operativo
HDInsight 4.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
HDInsight 5.0: Ubuntu 18.04.5 LTS Kernel Linux 5.4
Log Analytics - I clienti possono abilitare il monitoraggio classico per ottenere l'ultima versione di OMS 14.19. Per rimuovere le versioni precedenti, disabilitare e abilitare il monitoraggio classico.
Disconnessione automatica dell'utente dall'interfaccia di Ambari per inattività. Per altre informazioni, vedere qui
Spark - Questa versione include una versione nuova e ottimizzata di Spark 3.1.3. Abbiamo testato Apache Spark 3.1.2 (versione precedente) e Apache Spark 3.1.3 (versione corrente) usando il benchmark TPC-DS. Il test è stato eseguito usando lo SKU E8 V3 per Apache Spark su un carico di lavoro di 1 TB. Apache Spark 3.1.3 (versione corrente) ha superato le prestazioni di Apache Spark 3.1.2 (versione precedente) di oltre il 40% nel runtime di query totale per le query TPC-DS usando le stesse specifiche hardware. Il team di Microsoft Spark ha aggiunto ottimizzazioni disponibili in Azure Synapse con Azure HDInsight. Per altre informazioni, vedere Velocizzare i carichi di lavoro dei dati con gli aggiornamenti delle prestazioni di Apache Spark 3.1.2 in Azure Synapse
Qatar centrale
Germania settentrionale
HDInsight è passato da Azul Zulu Java JDK 8 a Adoptium Temurin JDK 8, che supporta runtime certificati TCK di alta qualità e la tecnologia associata per l'uso nell'intero ecosistema Java.
HDInsight è passato a reload4j. Le modifiche di log4j sono applicabili a
Apache Hadoop
Apache Zookeeper
Apache Oozie
Apache Ranger
Apache Sqoop
Apache Pig
Apache Ambari
Apache Kafka
Apache Spark
Apache Zeppelin
Apache Livy
Apache Rubix
Apache Hive
Apache Tez
Apache HBase
OMI
Apache Phoenix
In futuro HDInsight implementerà TLS1.2. Le versioni precedenti verranno aggiornate sulla piattaforma. Se si eseguono applicazioni in HDInsight che usano TLS 1.0 e 1.1, eseguire l'aggiornamento a TLS 1.2 per evitare interruzioni nei servizi.
Fine del supporto per i cluster Azure HDInsight in Ubuntu 16.04 LTS dal 30 novembre 2022. HDInsight ha iniziato a rilasciare immagini del cluster con Ubuntu 18.04 dal 27 giugno 2021. I clienti che eseguono cluster che usano Ubuntu 16.04 devono ricompilare i cluster con le immagini HDInsight più recenti entro il 30 novembre 2022.
Per altre informazioni su come controllare la versione Ubuntu del cluster, vedere qui
Eseguire il comando "lsb_release -a" nel terminale.
Se il valore della proprietà "Description" nell'output è "Ubuntu 16.04 LTS", questo aggiornamento è applicabile al cluster.
Supporto per la selezione delle zone di disponibilità per i cluster Kafka e HBase (accesso in scrittura).
Aggiornare Jackson databind alla versione 2.12.6.1 o superiore per evitare CVE-2020-36518
Data di rilascio: 10/08/2022
Questa versione si applica a HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni.
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Nuova funzionalità
1. Collegare dischi esterni nei cluster HDI Hadoop/Spark
Il cluster HDInsight include spazio su disco predefinito in base allo SKU. Questo spazio potrebbe non essere sufficiente in scenari con processi di grandi dimensioni.
Questa nuova funzionalità consente di aggiungere altri dischi nel cluster, che vengono usati come directory locale di gestione nodi. Aggiungere il numero di dischi ai nodi di lavoro durante la creazione di cluster HIVE e Spark, mentre i dischi selezionati fanno parte delle directory locali dello strumento di gestione nodi.
Nota
I dischi aggiunti sono configurati solo per le directory locali di gestione nodi.
L'analisi della registrazione selettiva è ora disponibile in anteprima pubblica in tutte le aree. È possibile connettere il cluster a un'area di lavoro Log Analytics. Dopo l'abilitazione è possibile visualizzare i log e le metriche, ad esempio i log di sicurezza di HDInsight, Yarn Resource Manager, le metriche di sistema e così via. È possibile monitorare i carichi di lavoro e vedere in che modo influiscono sulla stabilità del cluster. La registrazione selettiva consente di abilitare/disabilitare tutte le tabelle o di abilitare tabelle selettive nell'area di lavoro Log Analytics. È possibile modificare il tipo di origine per ogni tabella, perché nella nuova versione del monitoraggio di Geneva una tabella ha più origini.
Il sistema di monitoraggio Geneva usa mdsd (daemon di MDS), che è un agente di monitoraggio, e Fluentd per raccogliere i log usando un livello di registrazione unificato.
La registrazione selettiva usa l'azione script per disabilitare/abilitare le tabelle e i relativi tipi di log. Poiché non apre nuove porta né modifica impostazioni di sicurezza esistenti, non ci sono modifiche alla sicurezza.
L'azione script viene eseguita in parallelo in tutti i nodi specificati e modifica i file di configurazione per disabilitare/abilitare le tabelle e i relativi tipi di log.
Log Analytics integrato con Azure HDInsight che esegue OMS versione 13 richiede un aggiornamento a OMS 14 per applicare gli ultimi aggiornamenti della sicurezza.
I clienti che usano la versione precedente del cluster con OMS 13 devono installare OMS versione 14 per soddisfare i requisiti di sicurezza. (Come controllare la versione corrente e installare la 14)
Evitare di leggere la tabella come ACID quando il nome della tabella inizia con "delta", ma la tabella non è transazionale e viene usata la strategia di suddivisione BI
HDInsight è compatibile con Apache HIVE 3.1.2. A causa di un bug in questa versione, la versione di Hive viene visualizzata come 3.1.0 nelle interfacce hive. Non c'è però alcun impatto sulle funzionalità.
Data di rilascio: 10/08/2022
Questa versione si applica a HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni.
HDInsight usa procedure di distribuzione sicure, che comportano la distribuzione graduale nelle varie aree. Potrebbero essere necessari fino a 10 giorni lavorativi perché una nuova versione sia disponibile in tutte le regioni.
Nuova funzionalità
1. Collegare dischi esterni nei cluster HDI Hadoop/Spark
Il cluster HDInsight include spazio su disco predefinito in base allo SKU. Questo spazio potrebbe non essere sufficiente in scenari con processi di grandi dimensioni.
Questa nuova funzionalità consente di aggiungere altri dischi nel cluster, che verranno usati come directory locale di gestione nodi. Aggiungere il numero di dischi ai nodi di lavoro durante la creazione di cluster HIVE e Spark, mentre i dischi selezionati fanno parte delle directory locali dello strumento di gestione nodi.
Nota
I dischi aggiunti sono configurati solo per le directory locali di gestione nodi.
L'analisi della registrazione selettiva è ora disponibile in anteprima pubblica in tutte le aree. È possibile connettere il cluster a un'area di lavoro Log Analytics. Dopo l'abilitazione è possibile visualizzare i log e le metriche, ad esempio i log di sicurezza di HDInsight, Yarn Resource Manager, le metriche di sistema e così via. È possibile monitorare i carichi di lavoro e vedere in che modo influiscono sulla stabilità del cluster. La registrazione selettiva consente di abilitare/disabilitare tutte le tabelle o di abilitare tabelle selettive nell'area di lavoro Log Analytics. È possibile modificare il tipo di origine per ogni tabella, perché nella nuova versione del monitoraggio di Geneva una tabella ha più origini.
Il sistema di monitoraggio Geneva usa mdsd (daemon di MDS), che è un agente di monitoraggio, e Fluentd per raccogliere i log usando un livello di registrazione unificato.
La registrazione selettiva usa l'azione script per disabilitare/abilitare le tabelle e i relativi tipi di log. Poiché non apre nuove porta né modifica impostazioni di sicurezza esistenti, non ci sono modifiche alla sicurezza.
L'azione script viene eseguita in parallelo in tutti i nodi specificati e modifica i file di configurazione per disabilitare/abilitare le tabelle e i relativi tipi di log.
Log Analytics integrato con Azure HDInsight che esegue OMS versione 13 richiede un aggiornamento a OMS 14 per applicare gli ultimi aggiornamenti della sicurezza.
I clienti che usano la versione precedente del cluster con OMS 13 devono installare OMS versione 14 per soddisfare i requisiti di sicurezza. (Come controllare la versione corrente e installare la 14)
Evitare di leggere la tabella come ACID quando il nome della tabella inizia con "delta", ma la tabella non è transazionale e viene usata la strategia di suddivisione BI
HDInsight è compatibile con Apache HIVE 3.1.2. A causa di un bug in questa versione, la versione di Hive viene visualizzata come 3.1.0 nelle interfacce hive. Non c'è però alcun impatto sulle funzionalità.
Data di rilascio: 03/06/2022
Questa versione si applica a HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Principali caratteristiche della versione
Hive Warehouse Connector (HWC) in Spark v3.1.2
Hive Warehouse Connector (HWC) consente di sfruttare le funzionalità esclusive di Hive e Spark per creare potenti applicazioni Big Data. HWC è attualmente supportato solo per Spark v2.4. Questa funzionalità aggiunge valore aziendale consentendo transazioni ACID nelle tabelle Hive tramite Spark. Questa funzionalità è utile per i clienti che usano sia Hive che Spark nel proprio patrimonio di dati.
Per altre informazioni, vedere Apache Spark e Hive - Hive Warehouse Connector - Azure HDInsight | Microsoft Docs
Ambari
Modifiche al ridimensionamento e al provisioning
HDI Hive è ora compatibile con la versione del software open source 3.1.2
La versione 3.1 di HDI Hive è aggiornata alla versione del software open source Hive 3.1.2. Questa versione include tutte le correzioni e le funzionalità disponibili nella versione open source Hive 3.1.2.
Nota
Spark
Se si usa l'interfaccia utente di Azure per creare un cluster Spark per HDInsight, nell'elenco a discesa verrà visualizzata un'altra versione di Spark 3.1. (HDI 5.0) insieme alle versioni precedenti. Questa versione è una versione rinominata di Spark 3.1. (HDI 4.0). Si tratta solo di una modifica a livello di interfaccia utente, che non influisce in alcun modo sugli utenti esistenti e sugli utenti che usano già il modello di Resource Manager.
Nota
Interactive Query
Se si crea un cluster Interactive Query, nell'elenco a discesa verrà visualizzata un'altra versione denominata Interactive Query 3.1 (HDI 5.0).
Se si intende usare Spark 3.1 insieme a Hive, per cui è occorre il supporto ACID, è necessario selezionare la versione Interactive Query 3.1 (HDI 5.0).
Correzioni di bug TEZ
Correzioni di bug
Apache JIRA
TezUtils.createConfFromByteString in configurazione più grande di 32 MB genera l'eccezione com.google.protobuf.CodedInputStream
Implementare una funzione definita dall'utente per interpretare i valori data/timestamp usando la relativa rappresentazione interna e il calendario ibrido gregoriano-giuliano
MultiDelimitSerDe restituisce risultati errati nell'ultima colonna quando il file caricato contiene più colonne di quelle presenti nello schema della tabella
Il nome della colonna con parola chiave riservata non ha caratteri di escape quando una query che include un join su una tabella con colonna mask viene riscritta (Zoltan Matyus tramite Zoltan Haindrich)
Per ALTER TABLE t SET TBLPROPERTIES ('EXTERNAL'='TRUE'); le modifiche dell'attributo TBL_TYPE non vengono riglesse riflettono per il testo senza maiuscole
Questa versione si applica a HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Le versioni del sistema operativo per questa versione sono:
HDInsight 4.0: Ubuntu 18.04.5
Spark 3.1 è ora disponibile a livello generale
Spark 3.1 è ora disponibile a livello generale nella versione HDInsight 4.0. Questa versione include
Esecuzione adattiva di query,
Conversione di merge join di ordinamento in hash join di trasmissione,
Spark Catalyst Optimizer,
Eliminazione dinamica delle partizioni,
I clienti potranno creare nuovi cluster Spark 3.1 e non cluster Spark 3.0 (anteprima).
Per altre informazioni, vedere Apache Spark 3.1 è ora disponibile a livello generale in HDInsight - Microsoft Tech Community.
Kafka 2.4.1 è ora disponibile a livello generale. Per altre informazioni, vedere le note sulla versione di Kafka 2.4.1. Altre funzionalità includono la disponibilità di MirrorMaker 2, una nuova categoria di metriche AtMinIsr per le partizioni dei topic, il miglioramento del tempo di avvio del broker attraverso mmap lazy su richiesta dei file di indice e un numero maggiore di metriche di consumer per osservare il comportamento di polling degli utenti.
Il tipo di dati Map in HWC è ora supportato in HDInsight 4.0
Questa versione include il supporto del tipo di dati Map per HWC 1.0 (Spark 2.4) tramite l'applicazione spark-shell e tutti gli altri client Spark supportati da HWC. Sono inclusi i miglioramenti seguenti, come per qualsiasi altro tipo di dati:
Un utente può
Creare una tabella Hive con qualsiasi colonna contenente il tipo di dati Map, inserirvi dati e leggere i risultati.
Creare un dataframe Apache Spark con tipo di mappa ed eseguire operazioni di lettura e scrittura in batch/flusso.
Nuove aree
HDInsight ha ampliato la sua presenza geografica a due nuove aree: Cina orientale 3 e Cina settentrionale 3.
Modifiche di backport del software open source
Backport del software open source inclusi in Hive, tra cui HWC 1.0 (Spark 2.4) che supporta il tipo di dati Map.
Di seguito sono riportati i problemi JIRA di Apache per backport del software open source di questa versione:
Funzionalità interessata
Apache JIRA
Le query SQL dirette del metastore con IN/(NOT IN) devono essere suddivise in base ai parametri massimi consentiti dal database SQL
Set di scalabilità di macchine virtuali di Azure in HDInsight
HDInsight non userà più i set di scalabilità di macchine virtuali di Azure per effettuare il provisioning dei cluster. Non è prevista alcuna modifica che causa un'interruzione. I cluster HDInsight esistenti in set di scalabilità di macchine virtuali non subiscono alcun impatto, i nuovi cluster nelle immagini più recenti non useranno più i set di scalabilità di macchine virtuali.
Il ridimensionamento dei carichi di lavoro HBase di Azure HDInsight sarà ora supportato solo usando la scalabilità manuale
A partire dal 01 marzo 2022, HDInsight supporterà solo la scalabilità manuale per HBase, senza alcun impatto sui cluster in esecuzione. I nuovi cluster HBase non saranno in grado di abilitare la scalabilità automatica basata sulla pianificazione. Per altre informazioni su come ridimensionare manualmente i cluster HBase, vedere la documentazione relativa al ridimensionamento manuale dei cluster Azure HDInsight
Data di rilascio: 27/12/2021
Questa versione si applica a HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Le versioni del sistema operativo per questa versione sono:
I cluster HDI 4.0 creati dopo le 00:00 UTC del 27 dicembre 2021 vengono creati con una versione aggiornata dell'immagine, che mitiga le vulnerabilità di log4j. Di conseguenza, i clienti non devono applicare patch o riavviare questi cluster.
Per i nuovi cluster HDInsight 4.0 creati tra il 16 dicembre 2021 alle 01:15 UTC e il 27 dicembre 2021 alle 00:00 UTC, in HDInsight 3.6 o nelle sottoscrizioni aggiunte dopo il 16 dicembre 2021 la patch viene applicata automaticamente entro l'ora in cui viene creato il cluster. Tuttavia i clienti devono riavviare i nodi per il completamento dell'applicazione della patch (ad eccezione dei nodi di gestione Kafka, che vengono riavviati automaticamente).
Data di rilascio: 27/07/2021
Questa versione si applica a HDInsight 3.6 e HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Le versioni del sistema operativo per questa versione sono:
HDInsight 3.6: Ubuntu 16.04.7 LTS
HDInsight 4.0: Ubuntu 18.04.5 LTS
Nuove funzionalità
Il supporto di Azure HDInsight per la connettività pubblica con restrizioni è disponibile a livello generale dal 15 ottobre 2021
Azure HDInsight supporta ora la connettività pubblica con restrizioni in tutte le aree. Di seguito sono riportate alcune delle principali caratteristiche di questa funzionalità:
Possibilità di invertire la comunicazione tra provider di risorse e cluster in modo che sia in uscita dal cluster verso il provider di risorse
Supporto dell'uso di risorse abilitate per il collegamento privato (ad esempio archiviazione, SQL, Key Vault) per il cluster HDInsight in modo da accedere alle risorse solo tramite rete privata
Non viene effettuato il provisioning di indirizzi IP pubblici
Usando questa nuova funzionalità è anche possibile ignorare le regole dei tag del servizio del gruppo di sicurezza di rete (NSG) in ingresso per gli indirizzi IP di gestione di HDInsight. Altre informazioni sulla limitazione della connettività pubblica
Il supporto di Azure HDInsight per il collegamento privato di Azure è disponibile a livello generale dal 15 ottobre 2021
È ora possibile usare endpoint privati per connettersi ai cluster HDInsight tramite collegamento privato. Il collegamento privato può essere usato negli scenari tra reti virtuali in cui il peering reti virtuali non è disponibile o abilitato.
Collegamento privato di Azure consente di accedere ai servizi PaaS di Azure, ad esempio Archiviazione di Azure e Database SQL, nonché ai servizi di proprietà di clienti/partner ospitati in Azure tramite un endpoint privato nella rete virtuale.
Il traffico tra la rete virtuale e il servizio attraversa la rete del backbone Microsoft. L'esposizione del servizio sulla rete Internet pubblica non è più necessaria.
Nuova esperienza di integrazione di Monitoraggio di Azure (anteprima)
La nuova esperienza di integrazione di Monitoraggio di Azure sarà disponibile in anteprima negli Stati Uniti orientali e nell'Europa occidentale con questa versione. Informazioni dettagliate sulla nuova esperienza di Monitoraggio di Azure sono disponibili qui.
Deprecazione
La versione 3.6 di HDInsight è deprecata a partire dal 01 ottobre 2022.
Modifiche del comportamento
HDInsight Interactive Query supporta solo la scalabilità automatica basata su pianificazione
Man mano che gli scenari dei clienti si fanno più maturi e diversificati, sono state identificate alcune limitazioni relative alla scalabilità automatica basata sul carico di Interactive Query (LLAP). Queste limitazioni sono dovute alla natura della dinamica delle query LLAP, ai futuri problemi di accuratezza della stima del carico e ai problemi nella ridistribuzione delle attività dell'utilità di pianificazione LLAP. A causa di queste limitazioni, gli utenti potrebbero vedere che le query vengono eseguite più lentamente nei cluster LLAP quando è abilitata la scalabilità automatica. L'effetto sulle prestazioni può superare i vantaggi in termini di costi della scalabilità automatica.
A partire da luglio 2021, il carico di lavoro Interactive Query in HDInsight supporta solo la scalabilità automatica basata su pianificazione. Nei nuovi cluster Interactive Query non è più possibile abilitare la scalabilità automatica basata sul carico. I cluster in esecuzione esistenti possono continuare a essere eseguiti con le limitazioni note descritte in precedenza.
Microsoft consiglia di passare alla scalabilità automatica basata su pianificazione per LLAP. È possibile analizzare il modello di utilizzo corrente del cluster tramite il dashboard Hive Grafana. Per altre informazioni, vedere Ridimensionare automaticamente i cluster Azure HDInsight.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
Il componente LLAP predefinito nel cluster ESP Spark verrà rimosso
Il cluster ESP Spark di HDInsight 4.0 include componenti LLAP predefiniti in esecuzione in entrambi i nodi head. I componenti LLAP nel cluster ESP Spark sono stati originariamente aggiunti per Spark ESP di HDInsight 3.6, ma non hanno un caso d'uso reale per Spark ESP di HDInsight 4.0. Nella prossima versione, pianificata per settembre 2021, HDInsight rimuoverà il componente LLAP predefinito dal cluster ESP Spark di HDInsight 4.0. Questa modifica consente di eseguire l'offload del carico di lavoro del nodo head ed evitare confusione tra il tipo di cluster ESP Spark ed ESP Interactive Hive.
Nuova area
Stati Uniti occidentali 3
Jio India occidentale
Australia centrale
Modifica della versione dei componenti
In questa versione è stata modificata la versione del componente seguente:
Versione di ORC dalla 1.5.1 alla 1.5.9
Le attuali versioni dei componenti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento.
Backport di JIRA
Di seguito sono riportati i problemi JIRA di Apache per backport di questa versione:
Correzione dei prezzi per le macchine virtuali HDInsight Dv2
Il 25 aprile 2021 è stato corretto un errore relativo ai prezzi per la serie di macchine virtuali Dv2 in HDInsight. L'errore relativo ai prezzi ha prodotto un addebito inferiore sulle fatture di alcuni clienti prima del 25 aprile. Con la correzione, i prezzi corrispondono ora a quelli annunciati nella pagina dei prezzi di HDInsight e nel calcolatore dei prezzi di HDInsight. L'errore relativo ai prezzi ha interessato i clienti che usavano macchine virtuali Dv2 nelle aree seguenti:
Canada centrale
Canada orientale
Asia orientale
Sudafrica settentrionale
Asia sud-orientale
Emirati Arabi Uniti centrali
A partire dal 25 aprile 2021, gli account riporteranno l'importo corretto per le macchine virtuali Dv2. Prima della modifica, notifiche per i clienti sono state inviate ai proprietari delle sottoscrizioni. È possibile usare il calcolatore prezzi, la pagina prezzi di HDInsight o il pannello Crea cluster HDInsight nel portale di Azure per visualizzare i costi corretti per le VM Dv2 nella propria area.
Non è richiesto alcun altro intervento. La correzione dei prezzi verrà applicata solo per l'utilizzo a partire dal giorno 25 aprile 2021 compreso nelle aree specificate e non per l'utilizzo anteriore a questa data. Per assicurarsi di avere la soluzione più efficiente e conveniente, è consigliabile rivedere i prezzi, la VCPU e la RAM per i cluster Dv2 e confrontare le specifiche delle VM Dv2 rispetto alle VM Ev3 per verificare se la soluzione trarrebbe vantaggio dall'uso di una delle serie di macchine virtuali più recenti.
Data di rilascio: 02/06/2021
Questa versione si applica a HDInsight 3.6 e HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Le versioni del sistema operativo per questa versione sono:
HDInsight 3.6: Ubuntu 16.04.7 LTS
HDInsight 4.0: Ubuntu 18.04.5 LTS
Nuove funzionalità
Aggiornamento della versione del sistema operativo
Come indicato nel ciclo di rilascio di Ubuntu, il kernel Ubuntu 16.04 raggiunge la fine del servizio (EOL) nell'aprile 2021. Con questa versione è stata avviata l'implementazione della nuova immagine del cluster HDInsight 4.0 in esecuzione in Ubuntu 18.04. I nuovi cluster HDInsight 4.0 creati vengono eseguiti in Ubuntu 18.04 per impostazione predefinita una volta disponibili. I cluster esistenti in Ubuntu 16.04 vengono eseguiti così come sono con il supporto completo.
HDInsight 3.6 continuerà a essere eseguito in Ubuntu 16.04. Passerà al supporto Basic (dal supporto Standard) a partire dal 1° luglio 2021. Per altre informazioni sulle date e sulle opzioni di supporto, vedere Versioni di Azure HDInsight. Ubuntu 18.04 non sarà supportato per HDInsight 3.6. Se si vuole usare Ubuntu 18.04, è necessario eseguire la migrazione dei cluster a HDInsight 4.0.
Se si vogliono spostare cluster HDInsight 4.0 esistenti in Ubuntu 18.04 è necessario eliminarli e ricrearli. Pianificare la creazione o la ricreazione dei cluster dopo la data di disponibilità del supporto di Ubuntu 18.04.
Dopo aver creato il nuovo cluster, è possibile connettersi tramite SSH al cluster ed eseguire sudo lsb_release -a per verificare che sia eseguito in Ubuntu 18.04. È consigliabile testare le applicazioni nelle sottoscrizioni di test prima di passare all'ambiente di produzione.
Ottimizzazioni del ridimensionamento nei cluster HBase con scritture accelerate
Disabilitare Standard_A5 dimensioni della macchina virtuale come nodo head per HDInsight 4.0
Il nodo head del cluster HDInsight è responsabile dell'inizializzazione e della gestione del cluster. Le dimensioni di VM Standard_A5 presentano problemi di affidabilità come nodo head per HDInsight 4.0. A partire da questa versione, i clienti non potranno creare nuovi cluster con dimensioni di VM Standard_A5 come nodo head. È possibile usare altre macchine virtuali a due core, ad esempio E2_v3 o E2s_v3. I cluster esistenti verranno eseguiti così come sono. Per il nodo head è consigliabile usare una macchina virtuale con almeno 4 core per garantire la disponibilità elevata e l'affidabilità dei cluster HDInsight di produzione.
Risorsa dell'interfaccia di rete non visibile per i cluster in esecuzione nei set di scalabilità di macchine virtuali di Azure
HDInsight sta eseguendo gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. Le interfacce di rete delle macchine virtuali non sono più visibili ai clienti per i cluster che usano set di scalabilità di macchine virtuali di Azure.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
HDInsight Interactive Query supporta solo la scalabilità automatica basata su pianificazione
Man mano che gli scenari dei clienti si fanno più maturi e diversificati, sono state identificate alcune limitazioni relative alla scalabilità automatica basata sul carico di Interactive Query (LLAP). Queste limitazioni sono dovute alla natura della dinamica delle query LLAP, ai futuri problemi di accuratezza della stima del carico e ai problemi nella ridistribuzione delle attività dell'utilità di pianificazione LLAP. A causa di queste limitazioni, gli utenti potrebbero vedere che le query vengono eseguite più lentamente nei cluster LLAP quando è abilitata la scalabilità automatica. L'effetto sulle prestazioni può superare i vantaggi in termini di costi della scalabilità automatica.
A partire da luglio 2021, il carico di lavoro Interactive Query in HDInsight supporta solo la scalabilità automatica basata su pianificazione. Non è più possibile abilitare la scalabilità automatica nei nuovi cluster Interactive Query. I cluster in esecuzione esistenti possono continuare a essere eseguiti con le limitazioni note descritte in precedenza.
Microsoft consiglia di passare alla scalabilità automatica basata su pianificazione per LLAP. È possibile analizzare il modello di utilizzo corrente del cluster tramite il dashboard Hive Grafana. Per altre informazioni, vedere Ridimensionare automaticamente i cluster Azure HDInsight.
La denominazione dell'host macchina virtuale verrà modificata il 1° luglio 2021
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. Il servizio sta eseguendo gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. Questa migrazione modificherà il formato FQDN del nome host del cluster e non ci sono garanzie che i numeri nel nome host saranno in sequenza. Per ottenere i nomi FQDN per ogni nodo, vedere Trovare i nomi host dei nodi del cluster.
Passaggio ai set di scalabilità di macchine virtuali di Azure
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. Il servizio eseguirà gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. L'intero processo potrebbe richiedere mesi. Dopo la migrazione delle aree e delle sottoscrizioni, i nuovi cluster HDInsight creati verranno eseguiti nei set di scalabilità di macchine virtuali senza bisogno di alcun intervento da parte dei clienti. Non è prevista alcuna modifica che causa un'interruzione.
Data di rilascio: 24/03/2021
Nuove funzionalità
Anteprima di Spark 3.0
HDInsight ha aggiunto il supporto di Spark 3.0.0 a HDInsight 4.0 come funzionalità di anteprima.
Anteprima di Kafka 2.4
HDInsight ha aggiunto il supporto di Kafka 2.4.1 a HDInsight 4.0 come funzionalità di anteprima.
Supporto della serie Eav4
In questa versione HDInsight ha aggiunto il supporto della serie Eav4.
Passaggio a set di scalabilità di macchine virtuali
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. Il servizio sta eseguendo gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. L'intero processo potrebbe richiedere mesi. Dopo la migrazione delle aree e delle sottoscrizioni, i nuovi cluster HDInsight creati verranno eseguiti nei set di scalabilità di macchine virtuali senza bisogno di alcun intervento da parte dei clienti. Non è prevista alcuna modifica che causa un'interruzione.
Deprecazione
Nessuna deprecazione in questa versione.
Modifiche del comportamento
La versione predefinita del cluster è cambiata in 4.0
La versione predefinita del cluster HDInsight è cambiata da 3.6 a 4.0. Per altre informazioni sulle versioni disponibili, vedere le versioni supportate. Altre informazioni sulle novità di HDInsight 4.0.
Le dimensioni predefinite delle macchine virtuali del cluster sono cambiate in serie Ev3
Le dimensioni predefinite delle macchine virtuali del cluster sono cambiate da serie D a serie Ev3. Questa modifica si applica ai nodi head e ai nodi di lavoro. Per evitare che questa modifica influisca sui flussi di lavoro testati, specificare le dimensioni della macchina virtuale da usare nel modello di Resource Manager.
Risorsa dell'interfaccia di rete non visibile per i cluster in esecuzione nei set di scalabilità di macchine virtuali di Azure
HDInsight sta eseguendo gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. Le interfacce di rete delle macchine virtuali non sono più visibili ai clienti per i cluster che usano set di scalabilità di macchine virtuali di Azure.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
HDInsight Interactive Query supporta solo la scalabilità automatica basata su pianificazione
Man mano che gli scenari dei clienti si fanno più maturi e diversificati, sono state identificate alcune limitazioni relative alla scalabilità automatica basata sul carico di Interactive Query (LLAP). Queste limitazioni sono dovute alla natura della dinamica delle query LLAP, ai futuri problemi di accuratezza della stima del carico e ai problemi nella ridistribuzione delle attività dell'utilità di pianificazione LLAP. A causa di queste limitazioni, gli utenti potrebbero vedere che le query vengono eseguite più lentamente nei cluster LLAP quando è abilitata la scalabilità automatica. L'impatto sulle prestazioni può superare i vantaggi in termini di costi della scalabilità automatica.
A partire da luglio 2021, il carico di lavoro Interactive Query in HDInsight supporta solo la scalabilità automatica basata su pianificazione. Non è più possibile abilitare la scalabilità automatica nei nuovi cluster Interactive Query. I cluster in esecuzione esistenti possono continuare a essere eseguiti con le limitazioni note descritte in precedenza.
Microsoft consiglia di passare alla scalabilità automatica basata su pianificazione per LLAP. È possibile analizzare il modello di utilizzo corrente del cluster tramite il dashboard Hive Grafana. Per altre informazioni, vedere Ridimensionare automaticamente i cluster Azure HDInsight.
Aggiornamento della versione del sistema operativo
I cluster HDInsight sono attualmente in esecuzione in Ubuntu 16.04 LTS. Come indicato nel ciclo di rilascio di Ubuntu, il kernel Ubuntu 16.04 raggiungerà la fine del servizio (EOL) nell'aprile 2021. Avvieremo l'implementazione della nuova immagine del cluster HDInsight 4.0 in esecuzione in Ubuntu 18.04 a maggio 2021. I nuovi cluster HDInsight 4.0 creati verranno eseguiti in Ubuntu 18.04 per impostazione predefinita una volta disponibili. I cluster esistenti in Ubuntu 16.04 verranno eseguiti così come sono con il supporto completo.
HDInsight 3.6 continuerà a essere eseguito in Ubuntu 16.04. Raggiungerà la fine del supporto tecnico Standard il 30 giugno 2021 e passerà al supporto Basic a partire dal 1° luglio 2021. Per altre informazioni sulle date e sulle opzioni di supporto, vedere Versioni di Azure HDInsight. Ubuntu 18.04 non sarà supportato per HDInsight 3.6. Se si vuole usare Ubuntu 18.04 è necessario eseguire la migrazione dei cluster a HDInsight 4.0.
Se si vogliono spostare cluster esistenti in Ubuntu 18.04 è necessario eliminarli e ricrearli. Pianificare la creazione o la ricreazione del cluster dopo la disponibilità del supporto di Ubuntu 18.04. Quando la nuova immagine diventerà disponibile in tutte le aree invieremo un'altra notifica.
È consigliabile testare in anticipo le azioni script e le applicazioni personalizzate distribuite nei nodi perimetrali in una macchina virtuale Ubuntu 18.04. È possibile creare una macchina virtuale Ubuntu Linux nella versione 18.04-LTS, quindi creare e usare una coppia di chiavi SSH (Secure Shell) nella macchina virtuale per eseguire e testare le azioni script e le applicazioni personalizzate distribuite nei nodi perimetrali.
Disabilitare Standard_A5 dimensioni della macchina virtuale come nodo head per HDInsight 4.0
Il nodo head del cluster HDInsight è responsabile dell'inizializzazione e della gestione del cluster. Le dimensioni di VM Standard_A5 presentano problemi di affidabilità come nodo head per HDInsight 4.0. A partire dalla versione di maggio 2021, i clienti non potranno creare nuovi cluster con dimensioni della macchina virtuale Standard_A5 come nodo head. È possibile usare altre macchine virtuali a 2 core, ad esempio E2_v3 o E2s_v3. I cluster esistenti verranno eseguiti così come sono. Per il nodo head è consigliabile una VM con almeno 4 core per garantire la disponibilità elevata e l'affidabilità dei cluster HDInsight di produzione.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Modifica della versione dei componenti
Aggiunta del supporto per Spark 3.0.0 e Kafka 2.4.1 come anteprima.
Le attuali versioni dei componenti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento.
Data di rilascio: 05/02/2021
Questa versione si applica a HDInsight 3.6 e HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Nuove funzionalità
Supporto della serie Dav4
HDInsight ha aggiunto il supporto della serie Dav4 in questa versione. Altre informazioni sulla serie Dav4 sono disponibili qui.
Disponibilità generale del proxy REST Kafka
Il proxy REST Kafka consente di interagire con il cluster Kafka attraverso un'API REST tramite HTTPS. Il proxy REST Kafka è disponibile a livello generale a partire da questa versione. Altre informazioni sul proxy REST Kafka sono disponibili qui.
Passaggio a set di scalabilità di macchine virtuali
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. Il servizio sta eseguendo gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. L'intero processo potrebbe richiedere mesi. Dopo la migrazione delle aree e delle sottoscrizioni, i nuovi cluster HDInsight creati verranno eseguiti nei set di scalabilità di macchine virtuali senza bisogno di alcun intervento da parte dei clienti. Non è prevista alcuna modifica che causa un'interruzione.
Deprecazione
Dimensioni di VM disabilitate
A partire dal 9 gennaio 2021, HDInsight bloccherà tutti i clienti che creano cluster usando standard_A8, standard_A9, standard_A10 e standard_A11 dimensioni delle macchine virtuali. I cluster esistenti verranno eseguiti così come sono. Prendere in considerazione il passaggio a HDInsight 4.0 per evitare potenziali interruzioni di sistema/del supporto.
Modifiche del comportamento
Modifica delle dimensioni predefinite delle macchine virtuali del cluster in serie Ev3
Le dimensioni predefinite delle macchine virtuali del cluster saranno modificate da serie D a serie Ev3. Questa modifica si applica ai nodi head e ai nodi di lavoro. Per evitare che questa modifica influisca sui flussi di lavoro testati, specificare le dimensioni della macchina virtuale da usare nel modello di Resource Manager.
Risorsa dell'interfaccia di rete non visibile per i cluster in esecuzione nei set di scalabilità di macchine virtuali di Azure
HDInsight sta eseguendo gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. Le interfacce di rete delle macchine virtuali non sono più visibili ai clienti per i cluster che usano set di scalabilità di macchine virtuali di Azure.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
La versione predefinita del cluster verrà modificata in 4.0
A partire da febbraio 2021, la versione predefinita del cluster HDInsight verrà modificata da 3.6 a 4.0. Per altre informazioni sulle versioni disponibili, vedere le versioni supportate. Altre informazioni sulle novità di HDInsight 4.0.
Aggiornamento della versione del sistema operativo
HDInsight sta aggiornando la versione del sistema operativo da Ubuntu 16.04 a 18.04. L'aggiornamento verrà completato prima di aprile 2021.
Fine del supporto di HDInsight 3.6 il 30 giugno 2021
HDInsight 3.6 raggiungerà la fine del supporto. A partire dal 30 giugno 2021, i clienti non possono creare nuovi cluster HDInsight 3.6. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Prendere in considerazione il passaggio a HDInsight 4.0 per evitare potenziali interruzioni di sistema/del supporto.
Modifica della versione dei componenti
Questa release non prevede alcuna modifica della versione dei componenti. Le attuali versioni dei componenti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento.
Data di rilascio: 18/11/2020
Questa versione si applica a HDInsight 3.6 e HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Nuove funzionalità
Rotazione automatica delle chiavi per la crittografia dei dati inattivi con chiave gestita dal cliente
A partire da questa versione, i clienti possono usare gli URL delle chiavi di crittografia senza versione di Azure KeyVault per la crittografia dei dati inattivi della chiave gestita dal cliente. HDInsight ruoterà automaticamente le chiavi quando scadono o vengono sostituite con nuove versioni. Altre informazioni sono disponibili qui.
Possibilità di selezionare diverse dimensioni di macchine virtuali Zookeeper per Spark, Hadoop e ML Services
HDInsight in precedenza non supportava la personalizzazione delle dimensioni dei nodi Zookeeper per i tipi di cluster Spark, Hadoop e ML Services. Il valore predefinito sono le dimensioni di macchina virtuale A2_v2/A2, che vengono fornite gratuitamente. Da questa versione è possibile selezionare una macchina virtuale Zookeeper delle dimensioni più appropriate per il proprio scenario. I nodi Zookeeper con dimensioni della macchina virtuale diverse da A2_v2/A2 verranno addebitati. Le macchine virtuali A2_v2 e A2 sono ancora disponibili gratuitamente.
Passaggio a set di scalabilità di macchine virtuali
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. A partire da questa versione, il servizio eseguirà gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. L'intero processo potrebbe richiedere mesi. Dopo la migrazione delle aree e delle sottoscrizioni, i nuovi cluster HDInsight creati verranno eseguiti nei set di scalabilità di macchine virtuali senza bisogno di alcun intervento da parte dei clienti. Non è prevista alcuna modifica che causa un'interruzione.
Deprecazione
Deprecazione del cluster ML Services di HDInsight 3.6
Il tipo di cluster ML Services di HDInsight 3.6 raggiungerà la fine del supporto il 31 dicembre 2020. I clienti non potranno creare nuovi cluster ML Services 3.6 dopo il 31 dicembre 2020. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Controllare la scadenza del supporto per le versioni e i tipi di cluster HDInsight qui.
Dimensioni di VM disabilitate
A partire dal 16 novembre 2020, HDInsight bloccherà i nuovi clienti che creano cluster usando standard_A8, standard_A9, standard_A10 e standard_A11 dimensioni delle macchine virtuali. I clienti esistenti che hanno usato queste dimensioni delle macchine virtuali negli ultimi tre mesi non saranno interessati. A partire dal 9 gennaio 2021, HDInsight bloccherà tutti i clienti che creano cluster usando standard_A8, standard_A9, standard_A10 e standard_A11 dimensioni delle macchine virtuali. I cluster esistenti verranno eseguiti così come sono. Prendere in considerazione il passaggio a HDInsight 4.0 per evitare potenziali interruzioni di sistema/del supporto.
Modifiche del comportamento
Aggiunta del controllo delle regole del gruppo di sicurezza di rete prima dell'operazione di ridimensionamento
HDInsight ha aggiunto il controllo dei gruppi di sicurezza di rete (NSG) e delle route definite dall'utente con l'operazione di ridimensionamento. La stessa convalida viene eseguita per il ridimensionamento dei cluster oltre che per la creazione. Questa convalida consente di evitare errori imprevedibili. Se la convalida non viene superata, il ridimensionamento ha esito negativo. Altre informazioni su come configurare correttamente gruppi di sicurezza di rete e route definite dall'utente, vedere Indirizzi IP di gestione di HDInsight.
Modifica della versione dei componenti
Questa release non prevede alcuna modifica della versione dei componenti. Le attuali versioni dei componenti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento.
Data di rilascio: 09/11/2020
Questa versione si applica a HDInsight 3.6 e HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Nuove funzionalità
Il broker di ID di HDInsight (HIB) è ora disponibile a livello generale
Il broker di ID di HDInsight (HIB) che abilita l'autenticazione OAuth per i cluster ESP è ora disponibile a livello generale con questa versione. I cluster HIB creati dopo questa versione avranno le funzionalità HIB più recenti:
Disponibilità elevata
Supporto dell'autenticazione a più fattori (MFA)
Gli utenti federati accedono senza sincronizzazione dell'hash delle password con AAD-DS Per altre informazioni, vedere la documentazione di HIB.
Passaggio a set di scalabilità di macchine virtuali
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. A partire da questa versione, il servizio eseguirà gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. L'intero processo potrebbe richiedere mesi. Dopo la migrazione delle aree e delle sottoscrizioni, i nuovi cluster HDInsight creati verranno eseguiti nei set di scalabilità di macchine virtuali senza bisogno di alcun intervento da parte dei clienti. Non è prevista alcuna modifica che causa un'interruzione.
Deprecazione
Deprecazione del cluster ML Services di HDInsight 3.6
Il tipo di cluster ML Services di HDInsight 3.6 raggiungerà la fine del supporto il 31 dicembre 2020. I clienti non potranno creare nuovi cluster ML Services 3.6 dopo il 31 dicembre 2020. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Controllare la scadenza del supporto per le versioni e i tipi di cluster HDInsight qui.
Dimensioni di VM disabilitate
A partire dal 16 novembre 2020, HDInsight bloccherà i nuovi clienti che creano cluster usando standard_A8, standard_A9, standard_A10 e standard_A11 dimensioni delle macchine virtuali. I clienti esistenti che hanno usato queste dimensioni delle macchine virtuali negli ultimi tre mesi non saranno interessati. A partire dal 9 gennaio 2021, HDInsight bloccherà tutti i clienti che creano cluster usando standard_A8, standard_A9, standard_A10 e standard_A11 dimensioni delle macchine virtuali. I cluster esistenti verranno eseguiti così come sono. Prendere in considerazione il passaggio a HDInsight 4.0 per evitare potenziali interruzioni di sistema/del supporto.
Modifiche del comportamento
Nessuna modifica funzionale per questa versione.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
Possibilità di selezionare diverse dimensioni di macchine virtuali Zookeeper per Spark, Hadoop e ML Services
HDInsight attualmente non supporta la personalizzazione delle dimensioni dei nodi Zookeeper per i tipi di cluster Spark, Hadoop e ML Services. Il valore predefinito sono le dimensioni di macchina virtuale A2_v2/A2, che vengono fornite gratuitamente. Nella prossima versione sarà possibile selezionare una macchina virtuale Zookeeper delle dimensioni più appropriate per il proprio scenario. I nodi Zookeeper con dimensioni della macchina virtuale diverse da A2_v2/A2 verranno addebitati. Le macchine virtuali A2_v2 e A2 sono ancora disponibili gratuitamente.
La versione predefinita del cluster verrà modificata in 4.0
A partire da febbraio 2021, la versione predefinita del cluster HDInsight verrà modificata da 3.6 a 4.0. Per altre informazioni sulle versioni disponibili, vedere le versioni supportate. Altre informazioni sulle novità di HDInsight 4.0
Fine del supporto di HDInsight 3.6 il 30 giugno 2021
HDInsight 3.6 raggiungerà la fine del supporto. A partire dal 30 giugno 2021, i clienti non possono creare nuovi cluster HDInsight 3.6. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Prendere in considerazione il passaggio a HDInsight 4.0 per evitare potenziali interruzioni di sistema/del supporto.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Correzione del problema di riavvio delle macchine virtuali nel cluster
Questa release non prevede alcuna modifica della versione dei componenti. Le attuali versioni dei componenti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento.
Data di rilascio: 08/10/2020
Questa versione si applica a HDInsight 3.6 e HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Nuove funzionalità
Cluster privati HDInsight senza indirizzo IP pubblico e con collegamento privato (anteprima)
Ora HDInsight supporta la creazione di cluster senza IP pubblico e con accesso tramite collegamento privato ai cluster, in anteprima. I clienti possono usare le nuove impostazioni di rete avanzate per creare un cluster completamente isolato senza IP pubblico e usare i propri endpoint privati per accedere al cluster.
Passaggio a set di scalabilità di macchine virtuali
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. A partire da questa versione, il servizio eseguirà gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. L'intero processo potrebbe richiedere mesi. Dopo la migrazione delle aree e delle sottoscrizioni, i nuovi cluster HDInsight creati verranno eseguiti nei set di scalabilità di macchine virtuali senza bisogno di alcun intervento da parte dei clienti. Non è prevista alcuna modifica che causa un'interruzione.
Deprecazione
Deprecazione del cluster ML Services di HDInsight 3.6
Il tipo di cluster ML Services di HDInsight 3.6 raggiungerà la fine del supporto il 31 dicembre 2020. Dopo tale data, i clienti non potranno creare nuovi cluster ML Services 3.6. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Controllare la scadenza del supporto per le versioni e i tipi di cluster HDInsight qui.
Modifiche del comportamento
Nessuna modifica funzionale per questa versione.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
Possibilità di selezionare diverse dimensioni di macchine virtuali Zookeeper per Spark, Hadoop e ML Services
HDInsight attualmente non supporta la personalizzazione delle dimensioni dei nodi Zookeeper per i tipi di cluster Spark, Hadoop e ML Services. Il valore predefinito sono le dimensioni di macchina virtuale A2_v2/A2, che vengono fornite gratuitamente. Nella prossima versione sarà possibile selezionare una macchina virtuale Zookeeper delle dimensioni più appropriate per il proprio scenario. I nodi Zookeeper con dimensioni della macchina virtuale diverse da A2_v2/A2 verranno addebitati. Le macchine virtuali A2_v2 e A2 sono ancora disponibili gratuitamente.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Modifica della versione dei componenti
Questa release non prevede alcuna modifica della versione dei componenti. Le attuali versioni dei componenti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento.
Data di rilascio: 28/09/2020
Questa versione si applica a HDInsight 3.6 e HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Nuove funzionalità
La scalabilità automatica per Interactive Query con HDInsight 4.0 è ora disponibile a livello generale
La scalabilità automatica per il tipo di cluster Interactive Query è ora disponibile a livello generale per HDInsight 4.0. Tutti i cluster Interactive Query 4.0 creati dopo il 27 agosto 2020 avranno il supporto in disponibilità generale per la scalabilità automatica.
Il cluster HBase supporta ADLS Gen2 Premium
HDInsight supporta ora ADLS Gen2 Premium come account di archiviazione primario per i cluster HDInsight HBase 3.6 e 4.0. Insieme alle scritture accelerate, questo consente di ottenere prestazioni migliori per i cluster HBase.
Distribuzione delle partizioni Kafka nei domini di errore di Azure
Un dominio di errore è un raggruppamento logico dell'hardware sottostante in un data center di Azure. Ogni dominio di errore condivide una fonte di alimentazione e un commutatore di rete comuni. In precedenza HDInsight Kafka poteva archiviare tutte le repliche di partizione nello stesso dominio di errore. A partire da questa versione, HDInsight supporta la distribuzione automatica delle partizioni di Kafka in base ai domini di errore di Azure.
Crittografia dei dati in transito
I clienti possono abilitare la crittografia in transito tra nodi del cluster usando la crittografia IPsec con chiavi gestite dalla piattaforma. Questa opzione può essere abilitata al momento della creazione del cluster. Vedere altri dettagli su come abilitare la crittografia in transito.
Crittografia a livello di host
Quando si abilita la crittografia nell'host, i dati archiviati nell'host della macchina virtuale vengono crittografati quando inattivi e i flussi vengono crittografati nel servizio di archiviazione. In questa versione è possibile abilitare la crittografia nell'host nel disco dati temporaneo durante la creazione del cluster. La crittografia nell'host è supportata solo in determinati SKU di macchine virtuali in aree limitate. HDInsight supporta la configurazione del nodo e gli SKU seguenti. Vedere altri dettagli su come abilitare la crittografia nell'host.
Passaggio a set di scalabilità di macchine virtuali
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. A partire da questa versione, il servizio eseguirà gradualmente la migrazione ai set di scalabilità di macchine virtuali di Azure. L'intero processo potrebbe richiedere mesi. Dopo la migrazione delle aree e delle sottoscrizioni, i nuovi cluster HDInsight creati verranno eseguiti nei set di scalabilità di macchine virtuali senza bisogno di alcun intervento da parte dei clienti. Non è prevista alcuna modifica che causa un'interruzione.
Deprecazione
Nessuna deprecazione per questa versione.
Modifiche del comportamento
Nessuna modifica funzionale per questa versione.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
Possibilità di selezionare diversi SKU di Zookeeper per Spark, Hadoop e ML Services
HDInsight attualmente non supporta la modifica dello SKU di Zookeeper per i tipi di cluster Spark, Hadoop e ML Services. Usa lo SKU A2_v2/A2 per i nodi Zookeeper e ai clienti non vengono addebitati costi. Nella prossima versione i clienti possono modificare lo SKU di Zookeeper per Spark, Hadoop e ML Services in base alle esigenze. Verranno addebitati i nodi Zookeeper con SKU diversi da A2_v2/A2. Lo SKU predefinito sarà comunque A2_V2/A2 e gratuito.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Modifica della versione dei componenti
Questa release non prevede alcuna modifica della versione dei componenti. Le attuali versioni dei componenti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento.
Data di rilascio: 09/08/2020
Questa versione si applica solo a HDInsight 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Nuove funzionalità
Supporto per SparkCruise
SparkCruise è un sistema di riutilizzo automatico del calcolo per Spark. Seleziona sottoespressioni comuni da materializzare in base al carico di lavoro di query precedente. SparkCruise materializza queste sottoespressioni durante l'elaborazione delle query e il riutilizzo del calcolo viene applicato automaticamente in background. È possibile usufruire di SparkCruise senza apportare modifiche al codice Spark.
Supporto della vista Hive per HDInsight 4.0
La vista Hive di Apache Ambari è progettata per creare, ottimizzare ed eseguire facilmente query Hive dal Web browser. La vista Hive è supportata in modo nativo per i cluster HDInsight 4.0 a partire da questa versione. Non si applica ai cluster esistenti. È necessario eliminare e ricreare il cluster per ottenere la vista Hive predefinita.
Supporto della vista Tez per HDInsight 4.0
La vista Apache Tez viene usata per tenere traccia ed eseguire il debug dell'esecuzione del processo Hive Tez. La vista Tez è supportata in modo nativo per HDInsight 4.0 a partire da questa versione. Non si applica ai cluster esistenti. È necessario eliminare e ricreare il cluster per ottenere la vista Tez predefinita.
Deprecazione
Deprecazione di Spark 2.1 e 2.2 in un cluster Spark HDInsight 3.6
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Spark con Spark 2.1 e 2.2 su HDInsight 3.6. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Spark 2.3 in HDInsight 3.6 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Deprecazione di Spark 2.3 nel cluster Spark HDInsight 4.0
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Spark con Spark 2.3 su HDInsight 4.0. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Spark 2.4 in HDInsight 4.0 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Deprecazione di Kafka 1.1 nel cluster Kafka di HDInsight 4.0
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Kafka con Kafka 1.1 in HDInsight 4.0. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Kafka 2.1 in HDInsight 4.0 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Modifiche del comportamento
Modifica della versione dello stack Ambari
In questa versione, la versione di Ambari cambia da 2.x.x.x a 4.1. È possibile verificare la versione dello stack (HDInsight 4.1) in Ambari: Ambari >Utente > Versioni.
Modifiche imminenti
Nessuna imminente modifica che causa un'interruzione a cui occorra prestare attenzione.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Questa release non prevede alcuna modifica della versione dei componenti. Le attuali versioni dei componenti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento.
Problemi noti
È stato risolto un problema nel portale di Azure per cui gli utenti riscontravano un errore durante la creazione di un cluster di Azure HDInsight tramite un tipo di autenticazione SSH della chiave pubblica. Facendo clic su Rivedi e crea, gli utenti visualizzavano l'errore "Non deve contenere alcuna sequenza di tre caratteri consecutivi del nome utente SSH". Questo problema è stato risolto, ma potrebbe essere necessario aggiornare la cache del browser premendo CTRL+F5 per caricare la vista corretta. La soluzione alternativa a questo problema consiste nel creare un cluster con un modello di Resource Manager.
Data di rilascio: 13/07/2020
Questa versione è valida per HDInsight 3.6 e 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Nuove funzionalità
Supporto di Customer Lockbox per Microsoft Azure
Azure HDInsight supporta ora Customer Lockbox di Azure. Fornisce un'interfaccia per la revisione e l'approvazione oppure il rifiuto delle richieste di accesso ai dati da parte dei clienti. Viene usato nei casi in cui un tecnico Microsoft deve accedere ai dati dei clienti durante una richiesta di supporto. Per altre informazioni, vedere Customer Lockbox per Microsoft Azure.
Criteri per gli endpoint servizio per l'archiviazione
I clienti possono ora usare i criteri per gli endpoint servizio nella subnet del cluster HDInsight. Altre informazioni sui criteri per gli endpoint servizio.
Deprecazione
Deprecazione di Spark 2.1 e 2.2 in un cluster Spark HDInsight 3.6
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Spark con Spark 2.1 e 2.2 su HDInsight 3.6. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Spark 2.3 in HDInsight 3.6 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Deprecazione di Spark 2.3 nel cluster Spark HDInsight 4.0
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Spark con Spark 2.3 su HDInsight 4.0. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Spark 2.4 in HDInsight 4.0 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Deprecazione di Kafka 1.1 nel cluster Kafka di HDInsight 4.0
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Kafka con Kafka 1.1 in HDInsight 4.0. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Kafka 2.1 in HDInsight 4.0 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Modifiche del comportamento
Nessuna modifica funzionale a cui è necessario prestare attenzione.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
Possibilità di selezionare diversi SKU di Zookeeper per Spark, Hadoop e ML Services
HDInsight attualmente non supporta la modifica dello SKU di Zookeeper per i tipi di cluster Spark, Hadoop e ML Services. Usa lo SKU A2_v2/A2 per i nodi Zookeeper e ai clienti non vengono addebitati costi. Nella prossima versione i clienti potranno modificare lo SKU di Zookeeper per Spark, Hadoop e ML Services in base alle esigenze. Verranno addebitati i nodi Zookeeper con SKU diversi da A2_v2/A2. Lo SKU predefinito sarà comunque A2_V2/A2 e gratuito.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Correzione del problema di Hive Warehouse Connector
Nella versione precedente c'era un problema di usabilità di Hive Warehouse Connector. Il problema è stato risolto.
Correzione del problema relativo agli zeri iniziali troncati del notebook Zeppelin
Zeppelin troncava erroneamente gli zeri iniziali nell'output della tabella per il formato stringa. Il problema è stato risolto in questa versione.
Modifica della versione dei componenti
Questa release non prevede alcuna modifica della versione dei componenti. Le attuali versioni dei componenti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento.
Data di rilascio: 11/06/2020
Questa versione è valida per HDInsight 3.6 e 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Nuove funzionalità
Passaggio a set di scalabilità di macchine virtuali
Ora HDInsight usa macchine virtuali di Azure per eseguire il provisioning del cluster. Da questa versione, i cluster HDInsight creati iniziano a usare il set di scalabilità di macchine virtuali di Azure. La modifica viene implementata gradualmente. Non è prevista alcuna modifica che causa un'interruzione. Leggere altre informazioni sui set di scalabilità di macchine virtuali di Azure.
Riavvio delle macchine virtuali nel cluster HDInsight
In questa versione è supportato il riavvio delle macchine virtuali nel cluster HDInsight per riavviare i nodi che non rispondono. Attualmente è possibile farlo solo tramite API, il supporto di PowerShell e dell'interfaccia della riga di comando è in arrivo. Per altre informazioni sull'API, vedere questo documento.
Deprecazione
Deprecazione di Spark 2.1 e 2.2 in un cluster Spark HDInsight 3.6
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Spark con Spark 2.1 e 2.2 su HDInsight 3.6. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Spark 2.3 in HDInsight 3.6 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Deprecazione di Spark 2.3 nel cluster Spark HDInsight 4.0
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Spark con Spark 2.3 su HDInsight 4.0. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Spark 2.4 in HDInsight 4.0 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Deprecazione di Kafka 1.1 nel cluster Kafka di HDInsight 4.0
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Kafka con Kafka 1.1 in HDInsight 4.0. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Kafka 2.1 in HDInsight 4.0 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Modifiche del comportamento
Modifica delle dimensioni del nodo head del cluster ESP Spark
Le dimensioni minime del nodo head consentite per il cluster ESP Spark sono cambiate in Standard_D13_V2.
Le macchine virtuali con pochi core e poca memoria come nodo head potrebbero causare problemi del cluster ESP a causa della capacità di CPU e memoria relativamente bassa. A partire da questa versione, usare SKU superiori a Standard_D13_V2 e Standard_E16_V3 come nodo head per i cluster Spark ESP.
Per il nodo Head è necessaria una macchina virtuale con almeno 4 core
Per il nodo Head è necessaria una macchina virtuale con almeno 4 core per garantire la disponibilità elevata e l'affidabilità dei cluster HDInsight. A partire dal 6 aprile 2020, i clienti possono scegliere solo macchine virtuali con 4 core o più come nodo head per i nuovi cluster HDInsight. I cluster esistenti continueranno a funzionare come previsto.
Modifica del provisioning dei nodi di lavoro del cluster
Quando l'80% dei nodi di lavoro è pronto, il cluster entra in fase operativa. In questa fase i clienti possono eseguire tutte le operazioni del piano dati, ad esempio l'esecuzione di script e processi. Tuttavia, i clienti non possono eseguire alcuna operazione del piano di controllo, ad esempio l'aumento/riduzione. È supportata solo l'eliminazione.
Dopo la fase operativa, il cluster attende altri 60 minuti per il 20% rimanente dei nodi di lavoro. Alla fine di questo periodo di 60 minuti, il cluster passa alla fase di esecuzione, anche se non tutti i nodi di lavoro sono ancora disponibili. Quando un cluster entra nella fase di esecuzione, è possibile usarlo come di consueto. Vengono accettate sia le operazioni del piano di controllo, ad esempio l'aumento/riduzione delle prestazioni, sia le operazioni del piano dati, come l'esecuzione di script e processi. Se alcuni dei nodi di lavoro richiesti non sono disponibili, il cluster verrà contrassegnato con l'indicazione di operazione riuscita parzialmente. Vengono addebitati i costi per i nodi distribuiti correttamente.
Creazione di una nuova entità servizio tramite HDInsight
Nelle versioni precedenti, con la creazione del cluster i clienti possono creare una nuova entità servizio per accedere all'account ADLS Gen 1 connesso nel portale di Azure. A partire dal 15 giugno 2020, la creazione di una nuova entità servizio non è possibile nel flusso di lavoro di creazione di HDInsight ed è supportata solo l'entità servizio esistente. Vedere Creare un'entità servizio e certificati con Azure Active Directory.
Timeout per le azioni script con la creazione del cluster
HDInsight supporta l'esecuzione di azioni script con la creazione del cluster. Da questa versione, tutte le azioni script con la creazione del cluster devono essere completate entro 60 minuti o raggiungono il timeout. Le azioni script inviate ai cluster in esecuzione non sono interessate. Altre informazioni sono disponibili qui.
Modifiche imminenti
Nessuna imminente modifica che causa un'interruzione a cui occorra prestare attenzione.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Modifica della versione dei componenti
HBase da 2.0 a 2.1.6
Aggiornamento di HBase dalla versione 2.0 alla versione 2.1.6.
Spark da 2.4.0 a 2.4.4
Aggiornamento di Spark dalla versione 2.4.0 alla versione2.4.4.
Kafka da 2.1.0 a 2.1.1
Aggiornamento di Kafka dalla versione 2.1.0 alla versione 2.1.1.
Le versioni dei componenti correnti per HDInsight 4.0 e HDInsight 3.6 sono disponibili in questo documento
Problemi noti
Problema di Hive Warehouse Connector
In questa versione c'è un problema relativo a Hive Warehouse Connector. La correzione verrà inclusa nella prossima versione. I cluster esistenti creati prima di questa versione non sono interessati. Evitare di eliminare e ricreare il cluster, se possibile. Aprire un ticket di supporto se è necessaria ulteriore assistenza.
Data di rilascio: 09/01/2020
Questa versione è valida per HDInsight 3.6 e 4.0. La versione di HDInsight è resa disponibile per tutte le aree in diversi giorni. La data di release riportata indica la data di rilascio di release della prima area. Se non vengono visualizzate le modifiche seguenti, attendere che la versione venga rilasciata nella propria area per alcuni giorni.
Nuove funzionalità
Imposizione di TLS 1.2
Transport Layer Security (TLS) e Secure Sockets Layer (SSL) sono protocolli di crittografia che consentono di proteggere le comunicazioni su una rete di computer. Altre informazioni su TLS. HDInsight usa TLS 1.2 sugli endpoint HTTPS pubblici, ma TLS 1.1 è ancora supportato per la compatibilità con le versioni precedenti.
Con questa versione, i clienti possono scegliere TLS 1.2 solo per tutte le connessioni tramite l'endpoint del cluster pubblico. Per supportare questa operazione, è stata introdotta la nuova proprietà minSupportedTlsVersion, che può essere specificata durante la creazione del cluster. Se la proprietà non è impostata, il cluster supporterà comunque TLS 1.0, 1.1 e 1.2, come avviene attualmente. I clienti possono impostare il valore di questa proprietà su "1.2", il che significa che il cluster supporterà solo TLS 1.2 e versioni successive. Per altre informazioni, vedere Transport Layer Security.
Bring your own key per la crittografia su disco
Tutti i dischi gestiti in HDInsight sono protetti con Crittografia del servizio di archiviazione di Azure. Per impostazione predefinita, i dati su tali dischi vengono crittografati usando chiavi gestite da Microsoft. A partire da questa versione, è possibile usare Bring Your Own Key (BYOK) per la crittografia del disco e gestirla con Azure Key Vault. La crittografia BYOK è un processo di configurazione costituito da un singolo passaggio durante la creazione del cluster senza altri costi. È sufficiente registrare HDInsight come identità gestita con Azure Key Vault e aggiungere la chiave di crittografia quando si crea il cluster. Per altre informazioni, vedere Crittografia dischi con chiavi gestite dal cliente.
Deprecazione
Nessuna deprecazione per questa versione. Per prepararsi a deprecazioni future, vedere Prossime modifiche.
Modifiche del comportamento
Nessuna modifica del comportamento per questa versione. Per prepararsi a modifiche future, vedere Prossime modifiche.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
Deprecazione di Spark 2.1 e 2.2 in un cluster Spark HDInsight 3.6
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Spark con Spark 2.1 e 2.2 in HDInsight 3.6. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Spark 2.3 in HDInsight 3.6 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Deprecazione di Spark 2.3 nel cluster Spark HDInsight 4.0
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Spark con Spark 2.3 in HDInsight 4.0. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Spark 2.4 in HDInsight 4.0 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto.
Deprecazione di Kafka 1.1 nel cluster Kafka di HDInsight 4.0
A partire dal 1° luglio 2020, i clienti non possono creare nuovi cluster Kafka con Kafka 1.1 in HDInsight 4.0. I cluster esistenti verranno eseguiti così come sono, senza il supporto di Microsoft. Valutare il passaggio a Kafka 2.1 in HDInsight 4.0 entro il 30 giugno 2020 per evitare potenziali interruzioni del sistema o del supporto. Per altre informazioni, vedere Eseguire la migrazione di carichi di lavoro di Apache Kafka ad Azure HDInsight 4.0.
HBase da 2.0 a 2.1.6
Nella prossima release di HDInsight 4.0, la versione di HBase verrà aggiornata dalla 2.0 alla 2.1.6
Spark da 2.4.0 a 2.4.4
Nella prossima release di HDInsight 4.0, la versione di Spark verrà aggiornata dalla 2.4.0 alla 2.4.4
Kafka da 2.1.0 a 2.1.1
Nella prossima release di HDInsight 4.0, la versione di Kafka verrà aggiornata dalla 2.1.0 alla 2.1.1
Per il nodo Head è necessaria una macchina virtuale con almeno 4 core
Per il nodo Head è necessaria una macchina virtuale con almeno 4 core per garantire la disponibilità elevata e l'affidabilità dei cluster HDInsight. A partire dal 6 aprile 2020, i clienti possono scegliere solo macchine virtuali con 4 core o più come nodo head per i nuovi cluster HDInsight. I cluster esistenti continueranno a funzionare come previsto.
Modifica delle dimensioni del nodo del cluster ESP Spark
Nella prossima release, le dimensioni minime del nodo consentite per il cluster ESP Spark verranno modificate in Standard_D13_V2.
Le macchine virtuali della serie A possono causare problemi con il cluster ESP a causa di una capacità di CPU e memoria relativamente bassa. Le macchine virtuali della serie A saranno deprecate per la creazione di nuovi cluster ESP.
Passaggio a set di scalabilità di macchine virtuali
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. Nella prossima release, HDInsight userà invece set di scalabilità di macchine virtuali di Azure. Altre informazioni sui set di scalabilità di macchine virtuali di Azure.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Modifica della versione dei componenti
Questa release non prevede alcuna modifica della versione dei componenti. Le versioni dei componenti correnti per HDInsight 4.0 e HDInsight 3.6 sono consultabili qui.
Data di rilascio: 17/12/2019
Questa versione è valida per HDInsight 3.6 e 4.0.
Nuove funzionalità
Tag di servizio
I tag del servizio semplificano la sicurezza per le macchine virtuali di Azure e le reti virtuali di Azure, consentendo di limitare facilmente l'accesso di rete ai servizi di Azure. È possibile usare i tag del servizio nelle regole del gruppo di sicurezza di rete (NSG) per consentire o negare il traffico verso uno specifico servizio di Azure a livello globale o per area di Azure. La gestione degli indirizzi IP per ogni tag viene eseguita da Azure. I tag del servizio HDInsight per i gruppi di sicurezza di rete (NSG) sono gruppi di indirizzi IP per i servizi di integrità e gestione. Questi gruppi consentono di ridurre al minimo la complessità per la creazione delle regole di sicurezza. I clienti di HDInsight possono abilitare i tag del servizio tramite il portale di Azure, PowerShell e l'API REST. Per altre informazioni, vedere Tag del servizio del gruppo di sicurezza di rete (NSG) per Azure HDInsight.
Database Ambari personalizzato
HDInsight consente ora di usare il proprio database SQL per Apache Ambari. È possibile configurare questo database Ambari personalizzato dal portale di Azure o tramite un modello di Resource Manager. Questa funzionalità consente di scegliere il database SQL appropriato per le proprie esigenze di elaborazione e capacità. È anche possibile eseguire facilmente l'aggiornamento per soddisfare i requisiti di crescita aziendale. Per altre informazioni, vedere Configurare cluster HDInsight con un database Ambari personalizzato.
Deprecazione
Nessuna deprecazione per questa versione. Per prepararsi a deprecazioni future, vedere Prossime modifiche.
Modifiche del comportamento
Nessuna modifica del comportamento per questa versione. Per prepararsi per le future modifiche funzionali, vedere Modifiche imminenti.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
Imposizione di TLS (Transport Layer Security) 1.2
Transport Layer Security (TLS) e Secure Sockets Layer (SSL) sono protocolli di crittografia che consentono di proteggere le comunicazioni su una rete di computer. Per altre informazioni, vedere Transport Layer Security. Mentre i cluster Azure HDInsight accettano connessioni TLS 1.2 su endpoint HTTPS pubblici, TLS 1.1 è ancora supportato per compatibilità con le versioni precedenti per i client meno recenti.
A partire dalla prossima versione, sarà possibile acconsentire esplicitamente e configurare i nuovi cluster HDInsight in modo da accettare solo connessioni TLS 1.2.
Più avanti nell'anno, a partire dal 30/6/2020, Azure HDInsight imporrà l'uso di TLS 1.2 o versioni successive per tutte le connessioni HTTPS. Ti consigliamo di assicurarti che tutti i client siano pronti per gestire TLS 1.2 o versioni successive.
Passaggio a set di scalabilità di macchine virtuali
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. A partire da febbraio 2020 (la data esatta verrà comunicata in un secondo momento), HDInsight userà invece i set di scalabilità di macchine virtuali di Azure. Leggere altre informazioni sui set di scalabilità di macchine virtuali di Azure.
Modifica delle dimensioni del nodo del cluster ESP Spark
Nella prossima versione:
Le dimensioni minime del nodo consentite per il cluster ESP Spark verranno modificate in Standard_D13_V2.
Le macchine virtuali serie A saranno deprecate per la creazione di nuovi cluster ESP, in quanto potrebbero causare problemi del cluster ESP a causa di una capacità di CPU e memoria relativamente bassa.
HBase da 2.0 a 2.1
Nella prossima release di HDInsight 4.0, la versione di HBase verrà aggiornata dalla 2.0 alla 2.1.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Nessuna modifica della versione dei componenti per HDInsight 4.0.
Apache Zeppelin in HDInsight 3.6: 0.7.0-->0.7.3.
In questo documento sono elencate le versioni dei componenti più aggiornate.
Nuove aree
Emirati Arabi Uniti settentrionali
Gli indirizzi IP di gestione degli Emirati Arabi Uniti settentrionali sono: 65.52.252.96 e 65.52.252.97.
Data di rilascio: 07/11/2019
Questa versione è valida per HDInsight 3.6 e 4.0.
Nuove funzionalità
Broker di ID di HDInsight (HIB) (anteprima)
Il broker di ID di HDInsight (HIB) consente agli utenti di accedere ad Apache Ambari usando l'autenticazione a più fattori (MFA) e ottenere i ticket Kerberos necessari senza bisogno di hash delle password in Azure Active Directory Domain Services (AAD-DS). Attualmente HIB è disponibile solo per i cluster distribuiti tramite un modello di Azure Resource Management (ARM).
Proxy dell'API REST Kafka (anteprima)
Il proxy dell'API REST Kafka offre una distribuzione con un clic del proxy REST a disponibilità elevata con il cluster Kafka tramite l'autorizzazione di Azure AD protetta e il protocollo OAuth.
Scalabilità automatica
La scalabilità automatica per Azure HDInsight è ora disponibile a livello generale in tutte le aree per i tipi di cluster Apache Spark e Hadoop. Questa funzionalità consente di gestire i carichi di lavoro di analisi dei Big Data in modo più conveniente e produttivo. È ora possibile ottimizzare l'uso dei cluster HDInsight e pagare solo per le risorse necessarie.
In base ai requisiti specifici, puoi scegliere tra la scalabilità automatica basata su carico e basata su pianificazione. La scalabilità automatica basata sul carico consente di aumentare e ridurre le dimensioni del cluster in base alle esigenze di risorse correnti, mentre la scalabilità automatica basata sulla pianificazione può modificare le dimensioni del cluster in base a una pianificazione predefinita.
HDInsight offre ora una nuova capacità per consentire ai clienti di usare il proprio database SQL per Ambari. Ora i clienti possono scegliere il database SQL appropriato per Ambari e aggiornarlo facilmente in base ai propri requisito di crescita aziendale. La distribuzione viene eseguita con un modello di Azure Resource Manager. Per altre informazioni, vedere Configurare cluster HDInsight con un database Ambari personalizzato.
Le macchine virtuali serie F sono ora disponibili con HDInsight
Le macchine virtuali (VM) serie F sono una buona scelta per iniziare a usare HDInsight con requisiti di elaborazione leggeri. Con un prezzo di listino orario più basso, la serie F presenta il miglior rapporto prezzo-prestazioni nel portfolio Azure basato sull'unità di calcolo di Azure (ACU, Azure Compute Unit) per ogni vCPU. Per altre informazioni, vedere Selezione delle dimensioni della macchina virtuale appropriate per il cluster Azure HDInsight.
Deprecazione
Deprecazione delle macchine virtuali serie G
Da questa versione, le macchine virtuali serie G non sono più disponibili in HDInsight.
Deprecazione delle macchine virtuali Dv1
Da questa versione, l'uso delle VM Dv1 con HDInsight è deprecato. Qualsiasi richiesta dei clienti per Dv1 sarà soddisfatta automaticamente con Dv2. Non esiste alcuna differenza di prezzo tra le VM Dv1 e Dv2.
Modifiche del comportamento
Modifica delle dimensioni del disco gestito del cluster
HDInsight offre spazio su disco gestito con il cluster. Da questa versione, le dimensioni del disco gestito di ogni nodo di un nuovo cluster creato passano a 128 GB.
Modifiche imminenti
Nelle versioni future verranno apportate le modifiche seguenti.
Passaggio a set di scalabilità di macchine virtuali
HDInsight usa ora macchine virtuali di Azure per eseguire il provisioning del cluster. A partire da dicembre, HDInsight userà invece set di scalabilità di macchine virtuali di Azure. Leggere altre informazioni sui set di scalabilità di macchine virtuali di Azure.
HBase da 2.0 a 2.1
Nella prossima release di HDInsight 4.0, la versione di HBase verrà aggiornata dalla 2.0 alla 2.1.
Deprecazione delle macchine virtuali serie A per il cluster ESP
Le macchine virtuali della serie A possono causare problemi con il cluster ESP a causa di una capacità di CPU e memoria relativamente bassa. Nella prossima versione, le macchine virtuali della serie A saranno deprecate per la creazione di nuovi cluster ESP.
Correzioni di bug
HDInsight continua a migliorare l'affidabilità e le prestazioni del cluster.
Modifica della versione dei componenti
Questa release non prevede alcuna modifica della versione dei componenti. Le versioni dei componenti correnti per HDInsight 4.0 e HDInsight 3.6 sono consultabili qui.
Data di rilascio: 07/08/2019
Versioni dei componenti
Di seguito sono elencate le versioni Apache ufficiali di tutti i componenti di HDInsight 4.0. I componenti elencati sono le versioni stabili più recenti disponibili.
Apache Ambari 2.7.1
Apache Hadoop 3.1.1
Apache HBase 2.0.0
Apache Hive 3.1.0
Apache Kafka 1.1.1, 2.1.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.3.1, 2.4.0
Apache Sqoop 1.4.7
Apache TEZ 0.9.1
Apache Zeppelin 0.8.0
Apache ZooKeeper 3.4.6
Le versioni successive dei componenti di Apache vengono talvolta aggregate nella distribuzione HDP in aggiunta alle versioni elencate in precedenza. In questo caso, queste versioni successive sono elencate nella tabella Anteprime tecniche e non dovrebbero sostituire le versioni del componente Apache dell'elenco precedente in un ambiente di produzione.
Informazioni sulle patch di Apache
Per altre informazioni sulle patch disponibili in HDInsight 4.0, vedere l'elenco delle patch per ogni prodotto nella tabella seguente.
Phoenix Sqlline smette di funzionare dopo la migrazione del cluster HBase a HDInsight 4.0
Effettua i passaggi seguenti:
Eliminare le tabelle Phoenix seguenti:
SYSTEM.FUNCTION
SYSTEM.SEQUENCE
SYSTEM.STATS
SYSTEM.MUTEX
SYSTEM.CATALOG
Se non è possibile eliminare alcune delle tabelle, riavviare HBase per cancellare le connessioni alle tabelle.
Eseguire di nuovo sqlline.py. Phoenix creerà di nuovo tutte le tabelle eliminate nel passaggio 1.
Rigenerare le viste e le tabelle Phoenix per i dati HBase.
Phoenix Sqlline smette di funzionare dopo la replica dei metadati di HBase Phoenix da HDInsight 3.6 a 4.0
Effettua i passaggi seguenti:
Prima di eseguire la replica, passare al cluster 4.0 di destinazione ed eseguire sqlline.py. Questo comando genererà tabelle Phoenix come SYSTEM.MUTEX e SYSTEM.LOG che esistono solo nella versione 4.0.
Eliminare le tabelle seguenti:
SYSTEM.FUNCTION
SYSTEM.SEQUENCE
SYSTEM.STATS
SYSTEM.CATALOG
Avviare la replica HBase
Deprecazione
Apache Storm e ML Services non sono disponibili in HDInsight 4.0.
Data di rilascio: 14/04/2019
Nuove funzionalità
Le funzionalità e i nuovi aggiornamenti rientrano nelle seguenti categorie:
Aggiornamento di Hadoop e altri progetti open source: oltre alla correzione di più di un migliaio di bug in oltre 20 progetti open source, questo aggiornamento contiene una nuova versione di Spark, la 2.3, e di Kafka, la 1.0.
Aggiornamento di R Server 9.1 a Machine Learning Services 9.3: con questa versione vengono offerti a tecnici e scienziati dei dati i migliori progetti open source, ottimizzati con innovazioni degli algoritmi e operazionalizzazione semplificata, tutti disponibili nella loro lingua preferita, con la velocità di Apache Spark. Questa versione amplia le funzionalità offerte da R Server con supporto aggiuntivo per Python, con conseguente modifica del nome del cluster da R Server a Machine Learning Services.
Supporto per l'archiviazione di Azure Data Lake Gen2: HDInsight supporterà la versione di anteprima dell'archiviazione di Azure Data Lake Gen2. Nelle aree disponibili i clienti potranno scegliere un account di ADLS Gen2 come archivio Primario o Secondario per i cluster HDInsight.
Aggiornamenti di HDInsight Enterprise Security Package (anteprima): supporto degli endpoint servizio di rete virtuale per Archiviazione BLOB di Azure, ADLS Gen1, Cosmos DB e database di Azure.
Versioni dei componenti
Di seguito sono elencate le versioni Apache ufficiali di tutti i componenti di HDInsight 3.6. Tutti i componenti elencati di seguito sono le versioni stabili ufficiali più recenti disponibili di Apache.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ-0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
Le versioni successive di alcuni componenti di Apache vengono talvolta aggregate nella distribuzione HDP in aggiunta alle versioni elencate in precedenza. In questo caso, queste versioni successive sono elencate nella tabella Anteprime tecniche e non dovrebbero sostituire le versioni del componente Apache dell'elenco precedente in un ambiente di produzione.
Informazioni sulle patch di Apache
Hadoop
Questa versione fornisce Hadoop Common 2.7.3 e le patch di Apache seguenti:
HADOOP-13190: riferimento a LoadBalancingKMSClientProvider nella documentazione del server di gestione delle chiavi a disponibilità elevata.
HADOOP-13227: AsyncCallHandler deve usare un'architettura basata sugli eventi per gestire le chiamate asincrone.
HADOOP-14104: il client deve richiedere sempre namenode per il percorso del provider del server di gestione delle chiavi.
HADOOP-14799: aggiornamento di nimbus-jose-jwt alla versione 4.41.1.
HADOOP-14814: correzione modifica API non compatibile su FsServerDefaults in HADOOP-14104.
HADOOP-14903: aggiunto json-smart in modo esplicito a POM.xml.
HADOOP-15042: Azure PageBlobInputStream.skip() può restituire un valore negativo quando numberOfPagesRemaining è 0.
HADOOP-15255: supporto per la conversione maiuscole/minuscole per i nomi dei gruppi in LdapGroupsMapping.
HADOOP-15265: esclusione in modo esplicito di json-smart da hadoop-auth pom.xm.
HDFS-7922: ShortCircuitCache#close non rilascia ScheduledThreadPoolExecutors.
HDFS-8496: la chiamata a stopWriter() con mantenimento del blocco FSDatasetImpl potrebbe bloccare altri thread (cmccabe).
HDFS-10267: "sincronizzazione" extra su FsDatasetImpl#recoverAppend e FsDatasetImpl#recoverClose.
HDFS 10489: impostazione come deprecato di dfs.encryption.key.provider.uri per le zone di crittografia di Hadoop Distributed File System.
HDFS 11384: aggiunta dell'opzione del bilanciamento per distribuire le chiamate getBlocks per evitare picchi rpc.CallQueueLength di NameNode.
HDFS-11689: nuova eccezione generata da DFSClient%isHDFSEncryptionEnabled interrompe il codice Hive hacky.
HDFS-11711: il nome di dominio non dovrebbe eliminare il blocco sull'eccezione "Troppi file aperti".
HDFS-12347: TestBalancerRPCDelay#testBalancerRPCDelay ha spesso esito negativo.
HDFS-12781: dopo la chiusura di Datanode, la scheda Namenode dell'interfaccia utente di Datanode sta generando un messaggio di avviso.
HDFS-13054: gestione di PathIsNotEmptyDirectoryException nella chiamata di eliminazione DFSClient.
HDFS 13120: l'aread diff di snapshot potrebbe venire danneggiata dopo la concatenazione.
YARN-3742: YARN RM verrà arrestato in caso di timeout durante la creazione di ZKClient.
YARN 6061: aggiunta di UncaughtExceptionHandler per thread critici in RM.
YARN 7558: il comando per i log YARN non è in grado di ottenere i log per i contenitori in esecuzione se è abilitata l'autenticazione dell'interfaccia utente.
YARN 7697: il recupero dei log per l'applicazione terminata ha esito negativo anche se l'aggregazione dei log è stata completata.
HDP 2.6.4 ha fornito Hadoop Common 2.7.3 e le patch di Apache seguenti:
HADOOP-13700: rimozione di IOException non generata dalle firme TrashPolicy#initialize e #getInstance.
HADOOP-13709: possibilità di eseguire la pulizia dei sotto processi generati da Shell quando il processo viene chiuso.
HADOOP-14059: errore di digitazione nel messaggio di errore s3a rename(self, subdir).
HADOOP-14542: aggiunta di IOUtils.cleanupWithLogger che accetta l'API logger slf4j.
HDFS 9887: i timeout del socket WebHdfs devono essere configurabili.
HDFS 9914: correzione del timeout configurabile di connessione/lettura WebhDFS.
MAPREDUCE 6698: aumento del timeout su TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser.
YARN 4550: alcuni test in TestContainerLanch hanno esito negativo in un ambiente di impostazioni locali non in lingua inglese.
YARN 4717: TestResourceLocalizationService.testPublicResourceInitializesLocalDir ha esito negativo in modo intermittente a causa di IllegalArgumentException dalla pulizia.
YARN 5042: montaggio di /sys/fs/cgroup nei contenitori Docker come montaggio di sola lettura.
YARN-5318: correzione di errori di test intermittenti di TestRMAdminService#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider.
YARN 5641: il localizzatore lascia i file tarball dopo il completamento del contenitore.
YARN-6004: refactoring di TestResourceLocalizationService#testDownloadingResourcesOnContainer in modo che sia inferiore a 150 righe.
YARN 6078: contenitori bloccati in stato Localizzazione.
YARN-6805: NPE in LinuxContainerExecutor a causa di un codice di uscita PrivilegedOperationException nullo.
HBase
Questa versione fornisce HBase 1.1.2 e le patch di Apache seguenti.
HBASE-13376: miglioramenti al bilanciamento del carico Stochastic.
HBASE-13716: interruzione dell'uso di FSConstants di Hadoop.
HBASE-13848: password di accesso SSL a InfoServer tramite l'API del provider di credenziali.
HBASE-13947: uso di MasterServices invece di Server in AssignmentManager.
HBASE-14135: backup/ripristino fase 3 HBase: unione delle immagini di backup.
HBASE-14473: calcolo in parallelo della località della regione.
HBASE-14517: mostrare la versione di regionserver's nella pagina dello stato master.
HBASE-14606: timeout dei test TestSecureLoadIncrementalHFiles nella compilazione trunk su Apache.
HBASE-15210: annullamento della registrazione aggressiva del bilanciamento del carico in decine di righe al millisecondo.
HBASE-15515: miglioramento di LocalityBasedCandidateGenerator nel bilanciamento.
HBASE-15615: tempo di sospensione errato quando RegionServerCallable richiede un altro tentativo.
HBASE-16135: PeerClusterZnode in rs del peer rimosso non può essere mai eliminato.
HBASE-16570: calcolo in parallelo della località della regione all'avvio.
HBASE-16810: il bilanciamento di HBase genera ArrayIndexOutOfBoundsException quando i regionservers si trovano in /hbase/draining znode e sono senza carico.
HBASE-16852: TestDefaultCompactSelection non riuscito nel ramo 1.3.
HBASE-17387: riduzione dell'overhead del report delle eccezioni in RegionActionResult per multi ().
HBASE-17850: utility di backup di ripristino del sistema.
HBASE-17931: assegnazione delle tabelle di sistema ai server con la versione più recente.
HBASE-18083: rende il numero di thread di pulizia dei file di grandi/piccole dimensioni configurabile in HFileCleaner.
HBASE-18084: miglioramento di CleanerChore per eseguire la pulizia della directory che consuma maggiore spazio su disco.
HBASE-18164: funzione di costo località e generatore di candidati più veloci.
HBASE-18212: in modalità autonoma con il file system locale HBase registra il messaggio di avviso: Failed to invoke "unbuffer" method in class org.apache.hadoop.fs.FSDataInputStream. (Impossibile richiamare il metodo "unbuffer" nella classe org.apache.hadoop.fs.FSDataInputStream).
HBASE-18808: archiviazione della configurazione inefficace in BackupLogCleaner#getDeletableFiles().
HBASE-19052: FixedFileTrailer dovrebbe riconoscere la classe CellComparatorImpl in branch-1.x.
HBASE-19065: HRegion#bulkLoadHFiles() dovrebbe attendere Region#flush() simultaneo per terminare.
HBASE-19285: aggiunta di istogrammi di latenza per tabella.
HBASE-19393: head HTTP 413 FULL durante l'accesso all'interfaccia utente di HBase con SSL.
HBASE-19395: [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting ha esito negativo con NPE.
HBASE-19421:-branch-1 non viene compilato in base a Hadoop 3.0.0.
HBASE-19934: HBaseSnapshotException quando è abilitata la replica in lettura e viene eseguito uno snapshot online dopo la suddivisione di un'area.
HBASE-20008: [backport] NullPointerException quando si ripristina uno snapshot dopo la suddivisione di un'area.
Hive
Questa versione fornisce Hive 1.2.1 e Hive 2.1.0 oltre alle patch seguenti:
Patch Hive 1.2.1 Apache:
HIVE-10697: ObjectInspectorConvertors#UnionConvertor esegue una conversione non corretta.
HIVE-11266: risultato errato di count (*) in base alle statistiche di tabella per le tabelle esterne.
HIVE-12245: commenti della colonna Supporto per una tabella di backup HBase.
HIVE-12315: correzione della doppia divisione per zero vettorizzata.
HIVE-12360: ricerca non riuscita in ORC non compressi con la distribuzione dinamica del predicato.
HIVE-12378: eccezione nel campo binario HBaseSerDe.serialize.
HIVE-12785: visualizzazione con tipo di unione e UDF alla struttura interrotta.
HIVE-14013: la tabella di descrizione non mostra i caratteri Unicode in modo corretto.
HIVE-14205: Hive non supporta il tipo di unione con il formato di file AVRO.
HIVE-14421: FS.deleteOnExit include riferimenti ai file _tmp_space.db.
HIVE-15563: ignora l'eccezione di transizione di stato operazione non ammessa in SQLOperation.runQuery per esporre l'eccezione reale.
HIVE-15680: risultati non corretti quando hive.optimize.index.filter=true e viene fatto riferimento due volte alla stessa tabella ORC nella query, in modalità MR.
HIVE-15883: la tabella mappata HBase in Hive insert non riesce per il decimale.
HIVE-16232: supporta il calcolo delle statistiche per le colonne in QuotedIdentifier.
HIVE-16828: quando l'ottimizzazione basata sui costi è abilitata, la query nelle viste partizionate genera IndexOutOfBoundException.
HIVE-17013: elimina una richiesta con una sottoquery basata sulla selezione su una visualizzazione.
HIVE-17063: l'inserimento di una partizione di sovrascrittura su una tabella esterna non riesce quando prima si elimina la partizione.
HIVE-17259: Hive JDBC non riconosce le colonne UNIONTYPE.
HIVE-17419: il comando ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS mostra le statistiche calcolate per le tabelle mascherate.
HIVE-17530: ClassCastException durante la conversione uniontype.
HIVE-17621: le impostazioni Hive-site vengono ignorate durante il calcolo della divisione HCatInputFormat.
HIVE-17636: aggiunta del test multiple_agg.q per blobstores.
HIVE-17729: aggiunta di test Database ed Explain correlati dell'archivio BLOB.
HIVE-17731: aggiunta di un'opzione compat di compatibilità con le versioni precedenti per gli utenti esterni a HIVE-11985.
HIVE-17803: con Pig multi-query due scritture HCatStorers nella stessa tabella sovrascriveranno i rispettivi output.
HIVE-17829: ArrayIndexOutOfBoundsException - tabelle di backup HBASE con schema Avro in Hive2.
HIVE-17845: l'inserimento non riesce se le colonne della tabella non sono in lettere minuscole.
HIVE-17900: l'analisi delle statistiche sulle colonne attivate da Compactor genera SQL malformato con una colonna di partizione >.
HIVE-18026: ottimizzazione della configurazione dell'entità Hive Webhcat.
HIVE-18031: supporto della replica per l'operazione Alter Database.
HIVE-18090: acid heartbeat non riesce quando metastore è connesso tramite le credenziali di hadoop.
HIVE-18189: query di Hive che restituisce risultati errati se hive.groupby.orderby.position.alias viene impostato su true.
HIVE-18258: vettorializzazione: Reduce-Side GROUP BY MERGEPARTIAL con colonne duplicate è danneggiata.
HIVE-18293: Hive non riesce a comprimere le tabelle contenute all'interno di una cartella che non appartiene a identità che eseguono HiveMetaStore.
HIVE-18327: rimuove la dipendenza HiveConf non necessaria per MiniHiveKdc.
HIVE-18341: aggiunge il supporto per il caricamento Repl per l'aggiunta di uno spazio dei nomi "non elaborato" per TDE con le stesse chiavi di crittografia.
HIVE-18352: introduce un'opzione METADATAONLY durante l'esecuzione REPL DUMP per consentire le integrazioni di altri strumenti.
HIVE-18353: CompactorMR deve chiamare jobclient.close() per attivare la pulizia.
HIVE-18390: IndexOutOfBoundsException quando si esegue una query su una vista partizionata in ColumnPruner.
HIVE-18429: compattazione di dati deve gestire un caso quando non viene prodotto alcun output.
HIVE-18447: JDBC: fornisce agli utenti JDBC un modo per trasmettere informazioni sui cookie tramite una stringa di connessione.
HIVE-18460: Compactor non trasmette le proprietà della tabella al writer Orc.
HIVE-18467: supporto di eventi whole warehouse dump / load + create/drop database (Anishek Agarwal, esaminato da Sankar Hariappan).
HIVE-18551: vettorializzazione: VectorMapOperator tenta di scrivere troppe colonne di vettori per Hybrid Grace.
HIVE-18587: l'evento insert DML potrebbe tentare di calcolare un checksum sulle directory.
HIVE-18613: estensione di JsonSerDe per supportare il tipo BINARY.
HIVE-18626: la clausola "with" del caricamento Repl non invia la configurazione alle attività.
HIVE-18660: PCR non distingue tra colonne di partizione e colonne virtuali.
HIVE-18754: REPL STATUS deve supportare la clausola 'with'.
HIVE-18754: REPL STATUS deve supportare la clausola 'with'.
HIVE-18788: pulizia degli input in JDBC PreparedStatement.
HIVE-18794: la clausola "with" del caricamento Repl non invia la configurazione alle attività per le tabelle non di partizione.
HIVE-18808: rende la compattazione più solida quando l'aggiornamento delle statistiche ha esito negativo.
HIVE-18817: eccezione ArrayIndexOutOfBounds durante la lettura della tabella ACID.
HIVE-18833: l'unione automatica non riesce con il comando "insert into directory as orcfile" (Inserimento nella directory come ORCfile).
HIVE-18879: elimina la necessità di un elemento incorporato in UDFXPathUtil di funzionare se xercesImpl.jar si trova in classpath.
HIVE-18907: creazione di utilità per risolvere il problema di indice di chiave acid da HIVE 18817.
Patch Hive 2.1.0 Apache:
HIVE-14013: la tabella di descrizione non mostra i caratteri Unicode in modo corretto.
HIVE-14205: Hive non supporta il tipo di unione con il formato di file AVRO.
HIVE-15563: ignora l'eccezione di transizione di stato operazione non ammessa in SQLOperation.runQuery per esporre l'eccezione reale.
HIVE-15680: risultati non corretti quando hive.optimize.index.filter=true e viene fatto riferimento due volte alla stessa tabella ORC nella query, in modalità MR.
HIVE-15883: la tabella mappata HBase in Hive insert non riesce per il decimale.
HIVE-16757: rimuove le chiamate a AbstractRelNode.getRows deprecato.
HIVE-16828: quando l'ottimizzazione basata sui costi è abilitata, la query nelle viste partizionate genera IndexOutOfBoundException.
HIVE-17063: l'inserimento di una partizione di sovrascrittura su una tabella esterna non riesce quando prima si elimina la partizione.
HIVE-17259: Hive JDBC non riconosce le colonne UNIONTYPE.
HIVE-17530: ClassCastException durante la conversione uniontype.
HIVE-17600: rende configurabile dall'utente enforceBufferSize di OrcFile.
HIVE-17601: migliora la gestione degli errori in LlapServiceDriver.
HIVE-17613: rimuove i pool di oggetti per le allocazioni brevi dello stesso thread.
HIVE-17617: il rollup di un set di risultati vuoto deve contenere il raggruppamento del set di raggruppamento vuoto.
HIVE-17621: le impostazioni Hive-site vengono ignorate durante il calcolo della divisione HCatInputFormat.
HIVE-17629: CachedStore: aggiunta di una configurazione di elementi approvati/non approvati per consentire la memorizzazione selettiva nella cache delle tabelle/partizioni e consentire la lettura durante la configurazione preliminare.
HIVE-17636: aggiunta del test multiple_agg.q per blobstores.
HIVE-17702: gestione isRepeating non corretta nel lettore dei numeri decimali in ORC.
HIVE-17729: aggiunta di test Database ed Explain correlati dell'archivio BLOB.
HIVE-17731: aggiunta di un'opzione compat di compatibilità con le versioni precedenti per gli utenti esterni a HIVE-11985.
HIVE-17803: con Pig multi-query due scritture HCatStorers nella stessa tabella sovrascriveranno i rispettivi output.
HIVE-17845: l'inserimento non riesce se le colonne della tabella non sono in lettere minuscole.
HIVE-17900: l'analisi delle statistiche sulle colonne attivate da Compactor genera SQL malformato con una colonna di partizione >.
HIVE-18006: ottimizzazione del footprint della memoria di HLLDenseRegister.
HIVE-18026: ottimizzazione della configurazione dell'entità Hive Webhcat.
HIVE-18031: supporto della replica per l'operazione Alter Database.
HIVE-18090: acid heartbeat non riesce quando metastore è connesso tramite le credenziali di hadoop.
HIVE-18189: l'ordinamento in base alla posizione non funziona quando cbo è disabilitato.
HIVE-18258: vettorializzazione: Reduce-Side GROUP BY MERGEPARTIAL con colonne duplicate è danneggiata.
HIVE-18269: LLAP: l'I/O llap rapido con pipeline con elaborazione lenta può causare un problema di memoria insufficiente.
HIVE-18293: Hive non riesce a comprimere le tabelle contenute all'interno di una cartella che non appartiene a identità che eseguono HiveMetaStore.
HIVE-18318: il lettore dei record LLAP deve verificare l'interrupt anche quando non causa un blocco.
HIVE-18326: utilità di pianificazione Tez LLAP - può dare la precedenza alle attività solo se esiste una dipendenza tra di esse.
HIVE-18327: rimuove la dipendenza HiveConf non necessaria per MiniHiveKdc.
HIVE-18331: aggiunta di una nuova funzione per ripetere l'accesso alla scadenza del TGT e di alcune registrazioni/lambda.
HIVE-18341: aggiunge il supporto per il caricamento Repl per l'aggiunta di uno spazio dei nomi "non elaborato" per TDE con le stesse chiavi di crittografia.
HIVE-18352: introduce un'opzione METADATAONLY durante l'esecuzione REPL DUMP per consentire le integrazioni di altri strumenti.
HIVE-18353: CompactorMR deve chiamare jobclient.close() per attivare la pulizia.
HIVE-18384: ConcurrentModificationException nella libreria log4j2.x.
HIVE-18390: IndexOutOfBoundsException quando si esegue una query su una vista partizionata in ColumnPruner.
HIVE-18447: JDBC: fornisce agli utenti JDBC un modo per trasmettere informazioni sui cookie tramite una stringa di connessione.
HIVE-18460: Compactor non trasmette le proprietà della tabella al writer Orc.
HIVE-18462: (spiegazione formattazione per query con Map join con columnExprMap con nome di colonna non formattato).
HIVE-18488: i lettori LLAP ORC non hanno alcuni controlli null.
HIVE-18490: una query con EXISTS e NOT EXISTS con predicato non-equi può produrre un risultato errato.
HIVE-18506: LlapBaseInputFormat - indice di matrice negativo.
HIVE-18517: vettorializzazione: correggere VectorMapOperator per accettare VRB e controllare correttamente il flag vettorializzato affinché supporti la memorizzazione nella cache LLAP.
HIVE-18523: corregge la riga di riepilogo nel caso in cui non siano presenti input.
HIVE-18528: le statistiche di aggregazione in ObjectStore hanno un risultato errato.
HIVE-18530: la replica deve ignorare la tabella MM (per il momento).
HIVE-18551: vettorializzazione: VectorMapOperator tenta di scrivere troppe colonne di vettori per Hybrid Grace.
HIVE-18577: SemanticAnalyzer.validate ha alcune chiamate metastore inutili.
HIVE-18587: l'evento insert DML potrebbe tentare di calcolare un checksum sulle directory.
HIVE-18597: LLAP: creare sempre il pacchetto JAR dell'API log4j2 per org.apache.log4j.
HIVE-18613: estensione di JsonSerDe per supportare il tipo BINARY.
HIVE-18626: la clausola "with" del caricamento Repl non invia la configurazione alle attività.
HIVE-18643: non controlla le partizioni archiviate per le operazioni ACID.
HIVE-18660: PCR non distingue tra colonne di partizione e colonne virtuali.
HIVE-18754: REPL STATUS deve supportare la clausola 'with'.
HIVE-18788: pulizia degli input in JDBC PreparedStatement.
HIVE-18794: la clausola "with" del caricamento Repl non invia la configurazione alle attività per le tabelle non di partizione.
HIVE-18808: rende la compattazione più solida quando l'aggiornamento delle statistiche ha esito negativo.
HIVE-18815: rimuove le funzionalità inutilizzate in HPL/SQL.
HIVE-18817: eccezione ArrayIndexOutOfBounds durante la lettura della tabella ACID.
HIVE-18833: l'unione automatica non riesce con il comando "insert into directory as orcfile" (Inserimento nella directory come ORCfile).
HIVE-18879: elimina la necessità di un elemento incorporato in UDFXPathUtil di funzionare se xercesImpl.jar si trova in classpath.
HIVE-18944: la posizione dei set di raggruppamento è impostata in modo non corretto durante il DPP.
Kafka
Questa versione fornisce Kafka 1.0.0 e le patch di Apache seguenti.
KAFKA-4827: connessione Kafka: errore con i caratteri speciali nel nome del connettore.
KAFKA-6118: errore temporaneo in kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials.
KAFKA-6156: JmxReporter non è in grado di gestire i percorsi di directory stile Windows.
KAFKA-6164: i thread ClientQuotaManager impediscono l'arresto quando viene rilevato un errore durante il caricamento dei log.
KAFKA-6167: il timestamp nella directory dei flussi contiene un segno di due punti, che è un carattere non valido.
KAFKA-6179: RecordQueue.clear() non effettua la cancellazione dell'elenco gestito di MinTimestampTracker.
KAFKA-6185: perdita di memoria del selettore con alta probabilità di memoria insufficiente in caso di conversione verso il basso.
KAFKA-6190: GlobalKTable non completa il ripristino quando si usano i messaggi transazionali.
KAFKA-6210: IllegalArgumentException se 1.0.0 viene usato per inter.broker.protocol.version o log.message.format.version.
KAFKA-6214: l'uso delle repliche Standby con un archivio di stati in memoria causa l'arresto anomalo di Streams.
KAFKA-6215: KafkaStreamsTest causa errori nel trunk.
KAFKA-6238: problemi di versione del protocollo quando si applica un aggiornamento in sequenza a 1.0.0.
KAFKA-6260: AbstractCoordinator non gestisce in modo chiaro l'eccezione NULL.
KAFKA-6261: la registrazione delle richiesta genera un'eccezione se acks=0.
KAFKA-6274: miglioramento dei nomi generati automaticamente dall'archivio di stati KTable Source.
Mahout
In HDP 2.3.x e 2.4.x, invece del rilascio di una specifica versione Apache di Mahout, è stata effettuata la sincronizzazione su un punto di revisione specifico sul trunk di Apache Mahout. Questo punto di revisione è successivo alla versione 0.9.0 ma precedente alla versione 0.10.0. Ciò consente un numero elevato di correzioni di bug e miglioramenti funzionali nella versione 0.9.0, ma fornisce una versione stabile della funzionalità di Mahout prima della conversione completa al nuovo Mahout basato su Spark nella versione 0.10.0.
Il punto di revisione scelto per Mahout in HDP 2.3.x e 2.4.x proviene dal ramo "mahout-0.10.x" di Apache Mahout, a partire dal 19 dicembre 2014, revisione 0f037cb03e77c096 in GitHub.
In HDP 2.5.x e 2.6 la libreria "commons-httpclient" è stata rimossa da Mahout perché è ritenuta una libreria obsoleta, con possibili problemi di sicurezza ed è stato eseguito l'aggiornamento del Client Hadoop in Mahout alla versione 2.7.3, la stessa usata in HDP-2.5. Di conseguenza:
I processi Mahout compilati in precedenza dovranno essere ricompilati in ambiente HDP 2.5 o 2.6.
Esiste una piccola possibilità che alcuni processi Mahout possano riscontrare errori "ClassNotFoundException" o "could not load class" correlati a "org.apache.commons.httpclient", "net.java.dev.jets3t" o a prefissi dei nomi di classe correlati. Se si verificano questi errori si può considerare di installare manualmente i file JAR necessari nel percorso di classe del processo, se il rischio di problemi di sicurezza nella libreria obsoleta è accettabile nel proprio ambiente.
Esiste una possibilità ancora minore che alcuni processi Mahout possano arrestarsi in modo anomalo nelle chiamate del codice hbase-client alle librerie comuni hadoop a causa di problemi di compatibilità binaria. Purtroppo non è possibile risolvere questo problema se non tornando alla versione HDP-2.4.2 di Mahout, che potrebbe presentare problemi di sicurezza. Si tratta comunque di una possibilità remota ed è improbabile che si verifichi in una suite di processi di Mahout.
Oozie
Questa versione fornisce Oozie 4.2.0 e le patch di Apache seguenti.
OOZIE-2571: aggiunge una proprietà Maven spark.scala.binary.version in modo che sia possibile usare Scala 2.11.
OOZIE-2606: imposta spark.yarn.jars per correggere Spark 2.0 con Oozie.
OOZIE-2658:-driver-class-path può sovrascrivere il percorso di classe in SparkMain.
OOZIE-2787: Oozie distribuisce l'applicazione jar due volte causando un errore del processo spark.
OOZIE-2792: l'azione Hive2 non analizza in modo appropriato l'ID dell'applicazione Spark dal file di log quando Hive si trova in Spark.
OOZIE-2799: impostazione del percorso del log per spark sql su hive.
OOZIE-2802: errore dell'azione di Spark su Spark 2.1.0 a causa di sharelibs duplicati.
OOZIE-2923: miglioramento dell'analisi delle opzioni Spark.
OOZIE-3139: Oozie convalida il flusso di lavoro in modo non corretto.
OOZIE-3167: aggiornamento della versione di Tomcat sul ramo di Oozie 4.3.
Phoenix
Questa versione fornisce Phoenix 4.7.0 e le patch di Apache seguenti:
PHOENIX-1751: esecuzione di aggregazioni, ordinamento e così via in preScannerNext anziché in postScannerOpen.
PHOENIX-2714: stima corretta dei byte in BaseResultIterators ed esposizione come interfaccia.
PHOENIX-2724: l'esecuzione di query con un numero elevato di indicatori risulta più lenta rispetto a query senza statistiche.
PHOENIX-2855: soluzione alternativa per l'incremento di TimeRange non serializzata per HBase 1.2.
PHOENIX-3023: prestazioni lente quando le query di limite vengono eseguite in parallelo per impostazione predefinita.
PHOENIX-3040: non vengono usati indicatori per l'esecuzione di query in modo seriale.
PHOENIX-3112: analisi di righe parziale non gestita correttamente.
PHOENIX-3240: ClassCastException dal caricatore Pig.
PHOENIX-3452: NULLS FIRST/NULL LAST non dovrebbero influire se GROUP BY mantiene l'ordine.
PHOENIX 3469: ordinamento errato per la chiave primaria DESC per NULLS LAST/NULLS FIRST.
PHOENIX-3789: esegue le chiamate di manutenzione dell'indice tra aree in postBatchMutateIndispensably.
PHOENIX-3865: IS NULL non restituisce risultati corretti quando la prima famiglia di colonne non viene filtrata.
PHOENIX 4290: scansione completa della tabella eseguita per DELETE con la tabella che contiene indici non modificabili.
PHOENIX-4373: chiave di lunghezza variabile di indice locale può avere i valori null finali durante l'operazione di upserting.
PHOENIX-4466: java.lang.RuntimeException: codice di risposta 500 - esecuzione di un processo spark per la connessione a un server di query Phoenix e caricamento dei dati.
PHOENIX-4489: perdita di connessione HBase nei processi di MR Phoenix.
PHOENIX-4525: overflow numero intero nell'esecuzione GroupBy.
PHOENIX-4560: ORDER BY con GROUP BY non funziona se nella colonna pk è presente WHERE.
PHOENIX-4586: UPSERT SELECT non considera gli operatori di confronto per le sottoquery.
PHOENIX-4588: clonazione dell'espressione anche se i relativi elementi figlio hanno Determinism.PER_INVOCATION.
Pig
Questa versione fornisce Pig 0.16.0 e le patch di Apache seguenti.
PIG-5159: correzione di Pig che non salva la cronologia grunt.
PIG-5175: aggiornamento di jruby alla versione 1.7.26.
Ranger
Questa versione fornisce Ranger 0.7.0 e le patch di Apache seguenti:
RANGER-1805: miglioramento del codice per seguire le procedure consigliate in js.
RANGER-1960: considerare il nome della tabella dello snapshot per l'eliminazione.
RANGER-1982: miglioramento degli errori per Analytics Metric di Ranger Admin e per il Server di gestione delle chiavi Ranger.
RANGER-1984: i record del log di controllo di HBase possono non visualizzare tutti i tag associati alla colonna a cui hanno accesso.
RANGER-1988: correzione della casualità non sicura.
RANGER-1990: aggiunta del supporto unidirezionale SSL MySQL in Ranger Admin.
RANGER-2006: correzione dei problemi rilevati dall'analisi del codice statico in ranger usersync per l'origine di sincronizzazione ldap.
RANGER-2008: la valutazione dei criteri non riesce per le condizioni dei criteri su più righe.
Dispositivo di scorrimento
Questa versione fornisce Slider 0.92.0 senza altre patch di Apache.
Spark
Questa versione fornisce Spark 2.3.0 e le patch di Apache seguenti:
SPARK-19964: evita la lettura dai repository remoti in SparkSubmitSuite.
SPARK-22882: test di Machine Learning per lo streaming strutturato: ml.classification.
SPARK-22915: test di flusso per spark.ml.feature, da N a Z.
SPARK-23020: corregge un altro race nel test dell'utilità di avvio in-process.
SPARK-23040: restituisce l'iteratore interrompibile per il lettore casuale.
SPARK-23173: evita la creazione di file con estensione parquet danneggiati durante il caricamento dei dati da JSON.
SPARK-23264: corregge scala.MatchError in literals.sql.out.
SPARK-23288: corregge le metriche di output con sink parquet.
SPARK-23329: corregge la documentazione delle funzioni trigonometriche.
SPARK-23406: Abilita i self-join stream-stream per il ramo-2.3.
SPARK-23434: Spark non deve inviare avvisi alla directory di metadati per un percorso di file HDFS.
SPARK-23436: dedurre la partizione come Date solo se è possibile eseguirne il cast in Date.
SPARK-23457: registrazione come prima cosa dei listener di completamento delle attività in ParquetFileFormat.
SPARK-23462: miglioramento del messaggio di errore di campo mancante in "StructType".
SPARK-23490: controllo di storage.locationUri con la tabella esistente in CreateTable.
SPARK-23524: i blocchi casuali locali di grandi dimensioni non devono essere verificati per eventuali danneggiamenti.
SPARK-23525: supporto ALTER TABLE CHANGE COLUMN COMMENT per la tabella hive esterna.
SPARK-23553: i test non devono presupporre il valore predefinito di "spark.sql.sources.default".
SPARK-23569: consentire a pandas_udf di operare con le funzioni Python3 con stile type-annotated.
SPARK-23570: aggiunta di Spark 2.3.0 in HiveExternalCatalogVersionsSuite.
SPARK-23598: rendere pubblici i metodi in BufferedRowIterator per evitare errori di runtime in una query di grandi dimensioni.
SPARK-23599: aggiungere un generatore di UUID da Pseudo-Random Numbers.
SPARK-23599: uso di RandomUUIDGenerator nell'espressione Uuid.
SPARK-23601: rimuovere i file .md5 dalla versione.
SPARK-23608: aggiunta della sincronizzazione in SHS tra le funzioni attachSparkUI e detachSparkUI per evitare il problema di modifiche simultanee ai gestori di Jetty.
SPARK-23614: correzione dello scambio non corretto del riutilizzo quando viene usata la memorizzazione nella cache.
SPARK-23623: evita l'uso simultaneo di consumer memorizzati nella cache in CachedKafkaConsumer (ramo-2.3).
SPARK-23624: riesame della documentazione del metodo pushFilters in Datasource V2.
SPARK-23628: calculateParamLength non deve restituire 1 + numero delle espressioni.
SPARK-23630: Consente di rendere effettive le personalizzazioni conf Hadoop dell'utente.
SPARK-23635: la variabile di ambiente dell'executor Spark viene sovrascritta dalla variabile di ambiente AM con lo stesso nome.
SPARK-23637: Yarn può allocare più risorse se lo stesso esecutore viene terminato più volte.
SPARK-23639: ottenere i token prima del client init metastore nella CLI SparkSQL.
SPARK-23642: correzione di scaladoc isZero di per le sottoclassi di AccumulatorV2.
SPARK-23644: Usa il percorso assoluto per la chiamata REST in SHS.
SPARK-23645: aggiunta di argomenti sulle parole chiave nella documentazione relativa a "pandas_udf".
SPARK-23649: ignora i caratteri non consentiti in UTF-8.
SPARK-23658: InProcessAppHandle usa una classe errata in getLogger.
SPARK-23660: correzione eccezione in modalità cluster yarn quando l'applicazione termina rapidamente.
SPARK-23670: correzione di perdita di memoria su SparkPlanGraphWrapper.
SPARK-23671: correzione della condizione per abilitare il pool di thread SHS.
SPARK-23691: uso dell'utilità sql_conf nei test PySpark laddove possibile.
SPARK-23695: correzione del messaggio di errore per i test di streaming di Kinesis.
SPARK-23706: spark.conf.get(value, default=None) deve produrre None in PySpark.
SPARK-23728: correzione dei test ML con le eccezioni previste nell'esecuzione dei test di streaming.
SPARK-23729: rispetto della frammentazione URI durante le risoluzione dei glob.
SPARK-23759: Impossibile eseguire l'associazione dell'interfaccia utente di Spark al nome host / IP specifico.
SPARK-23760: CodegenContext.withSubExprEliminationExprs deve salvare/ripristinare lo stato CSE in modo corretto.
SPARK-23769: rimuovere i commenti che disabilitano inutilmente il controllo Scalastyle.
SPARK-23788: correzione di race in StreamingQuerySuite.
SPARK-23802: PropagateEmptyRelation può lasciare il piano di query in uno stato non risolto.
SPARK-23806: Broadcast.unpersist può causare un'eccezione irreversibile quando usato con l'allocazione dinamica.
SPARK-23808: impostare la sessione Spark predefinita nelle sessioni Spark a solo scopo di test.
SPARK-23809: SparkSession attivo deve essere impostato da getOrCreate.
SPARK-23816: le attività terminate devono ignorare FetchFailures.
SPARK-23822: miglioramento del messaggio di errore di mancata corrispondenza dello schema Parquet.
SPARK-23823: mantiene l'origine in transformExpression.
SPARK-23827: StreamingJoinExec deve assicurare che i dati di input siano partizionati in un numero specifico di partizioni.
SPARK-23838: l'esecuzione della query SQL viene visualizzata come "completata" nella scheda SQL.
SPARK-23881: correzione del test inattendibile JobCancellationSuite."interruptible iterator of shuffle reader".
Sqoop
Questa versione fornisce Sqoop 1.4.6 senza altre patch di Apache.
Storm
Questa versione fornisce Storm 1.1.1 e le patch di Apache seguenti:
STORM-2652: eccezione generata nel metodo Open JmsSpout.
STORM-2841: testNoAcksIfFlushFails UT ha esito negativo con NullPointerException.
STORM-2854: esposizione di IEventLogger per rendere la registrazione degli eventi collegabile.
STORM-2870: FileBasedEventLogger non registra ExecutorService non daemon che impedisce di portare a termine il processo.
STORM-2960: sottolineare l'importanza dell'impostazione appropriata di un account del sistema operativo per i processi Storm.
Tez
Questa versione fornisce Tez 0.7.0 e le patch di Apache seguenti:
TEZ-1526: LoadingCache per TezTaskID rallentata per i processi di grandi dimensioni.
Zeppelin
Questa versione fornisce Zeppelin 0.7.3 senza altre patch di Apache.
ZEPPELIN-3072: l'interfaccia utente di Zeppelin si rallenta/non risponde se sono presenti troppi notebook.
ZEPPELIN-3129: l'interfaccia utente di Zeppelin non si disconnette in Internet Explorer.
Questa versione fornisce ZooKeeper 3.4.6 e le patch di Apache seguenti:
ZOOKEEPER-1256: ClientPortBindTest ha esito negativo in macOS X.
ZOOKEEPER-1901: [JDK8] ordinamento degli elementi figlio per il confronto nei test AsyncOps.
ZOOKEEPER-2423: aggiornamento della versione Netty a causa di vulnerabilità di sicurezza (CVE-2014-3488).
ZOOKEEPER-2693: attacco DOS su parole di quattro lettere wchp/wchc (4lw).
ZOOKEEPER-2726: la patch introduce una possibile race condition.
Vulnerabilità comuni ed esposizioni risolte
Questa sezione descrive tutte le CVE (Common Vulnerabilities and Exposures) che vengono risolte in questa versione.
CVE-2017-7676
Riepilogo: la valutazione dei criteri di Apache Ranger ignora i caratteri dopo il carattere jolly "*"
Gravità: Critica
Fornitore: Hortonworks
Versioni interessate: versioni di HDInsight 3.6 incluse le versioni 0.5.x/0.6.x/0.7.0 di Apache Ranger
Utenti interessati: ambienti che usano i criteri Ranger con i caratteri dopo il carattere jolly "*" ad esempio my*test, test*.txt
Impatto: il matcher della risorsa criteri ignora i caratteri dopo il carattere jolly "*", il che può causare comportamenti imprevisti.
Dettaglio della correzione: il matcher della risorsa criteri Ranger è stato aggiornato per gestire correttamente le corrispondenze con i caratteri jolly.
Riepilogo: Apache Ranger Hive Authorizer deve controllare l'autorizzazione RWX quando viene specificato un percorso esterno
Gravità: Critica
Fornitore: Hortonworks
Versioni interessate: versioni di HDInsight 3.6 incluse le versioni 0.5.x/0.6.x/0.7.0 di Apache Ranger
Utenti interessati: ambienti che usano una posizione esterna per le tabelle hive
Impatto: negli ambienti che usano la posizione esterna per le tabelle hive, Apache Ranger Hive Authorizer deve controllare l'autorizzazione per il percorso esterno specificato per creare una tabella.
Dettaglio della correzione: Ranger Hive Authorizer è stato aggiornato per poter gestire correttamente il controllo delle autorizzazioni con la posizione esterna.
Azione consigliata: gli utenti devono eseguire l'aggiornamento a HDI 3.6 (con Apache Ranger 0.7.1+).
CVE-2017-9799
Riepilogo: potenziale esecuzione di codice come utente non corretto in Apache Storm
Utenti interessati: gli utenti che usano Storm in modalità protetta e usano l'archivio BLOB per distribuire elementi basati sulla topologia o che usano l'archivio BLOB per distribuire le risorse di topologia.
Impatto: in alcune situazioni e configurazioni di Storm è teoricamente possibile per il proprietario di una topologia ingannare il supervisore in modo che avvii un ruolo di lavoro come utente diverso, non ROOT. Nel peggiore dei casi, questo potrebbe causare la compromissione delle credenziali protette dell'altro utente. Questa vulnerabilità si applica solo alle installazioni di Apache Storm con la sicurezza abilitata.
Mitigazione dei rischi: eseguire l'aggiornamento a HDP 2.6.2.1 in quanto non esistono attualmente soluzioni.
CVE-2016-4970
Riepilogo: handler/ssl/OpenSslEngine.java in Netty 4.0.x prima della versione 4.0.37. Finale e 4.1.x prima della versione 4.1.1. La versione finale consente a utenti malintenzionati remoti di causare un attacco Denial of Service (ciclo infinito)
Gravità: Moderata
Fornitore: Hortonworks
Versioni interessate: HDP 2.x.x dopo 2.3.x
Utenti interessati: tutti gli utenti che usano HDFS.
Impatto: impatto basso poiché Hortonworks non usa OpenSslEngine.java direttamente nella codebase di Hadoop.
Azione consigliata: eseguire l'aggiornamento a HDP 2.6.3.
CVE-2016-8746
Riepilogo: problema di corrispondenza percorso Apache Ranger nella valutazione dei criteri
Gravità: Normale
Fornitore: Hortonworks
Versioni interessate: tutte le versioni di HDP 2.5 incluse le versioni 0.6.0/0.6.1/0.6.2 di Apache Ranger
Utenti interessati: tutti gli utenti dello strumento di amministrazione di criteri di Ranger.
Impatto: il motore dei criteri di Ranger mette in corrispondenza in modo non corretto i percorsi in determinate condizioni quando un criterio contiene caratteri jolly e flag ricorsivi.
Dettaglio della correzione: corretta la logica di valutazione dei criteri
Azione consigliata: gli utenti devono eseguire l'aggiornamento a HDP 2.5.4+ (con Apache Ranger 0.6.3+) o a HDP 2.6+ (con Apache Ranger 0.7.0+)
CVE-2016-8751
Riepilogo: problema di Apache Ranger di scripting archiviato tra siti
Gravità: Normale
Fornitore: Hortonworks
Versioni interessate: tutte le versioni di HDP 2.3/2.4/2.5 incluse le versioni 0.5.x/0.6.0/0.6.1/0.6.2 di Apache Ranger
Utenti interessati: tutti gli utenti dello strumento di amministrazione di criteri di Ranger.
Impatto: Apache Ranger è vulnerabile a uno scripting archiviato tra siti quando si immettono le condizioni dei criteri personalizzati. Gli utenti amministratori possono archiviare alcune esecuzioni di codice JavaScript arbitrario quando gli utenti normali si collegano e accedono ai criteri.
Dettaglio della correzione: aggiunta di logica per purificare l'input dell'utente.
Azione consigliata: gli utenti devono eseguire l'aggiornamento a HDP 2.5.4+ (con Apache Ranger 0.6.3+) o a HDP 2.6+ (con Apache Ranger 0.7.0+)
Problemi risolti per il supporto
I problemi risolti rappresentano problemi selezionati registrati in precedenza tramite il supporto di Hortonworks, ma che sono ora risolti nella versione corrente. Questi problemi potrebbero essere stati segnalati nelle versioni precedenti all'interno della sezione Problemi noti, vale a dire che sono stati segnalati dai clienti o identificati dal team tecnico di qualità di Hortonworks.
Interfaccia utente: eliminazione di un tag che alla posizione 25+ dell'elenco di tag nella struttura piatta e in quella ad albero necessita di un aggiornamento per rimuovere il tag dall'elenco.
Il thread di ReplicationMonitor può restare bloccato per molto tempo a causa di race tra la replica e la cancellazione dello stesso file in un cluster di grandi dimensioni.
Ripristino di "If kerberos is enabled while HTTP SPNEGO is not configured, some links cannot be accessed" (Se Kerberos è abilitato mentre SPNEGO HTTP non è configurato, alcuni collegamenti non sono accessibili)
Non è possibile ottenere mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException della tabella: tabella non trovata durante l'esecuzione dell'analisi della tabella sulle colonne in LLAP
Vettorializzazione: correggere VectorMapOperator per accettare VRB e controllare correttamente il flag vettorializzato affinché supporti la memorizzazione nella cache LLAP
Il thread di ReplicationMonitor thread può restare bloccato per molto tempo a causa di race tra la replica e la cancellazione dello stesso file in un cluster di grandi dimensioni.
La ricerca salvata preferita viene visualizzata solo dopo l'operazione di aggiornamento dopo la creazione quando sono presenti più di 25 ricerche preferite.
Interfaccia utente: eliminazione di un tag che alla posizione 25+ dell'elenco di tag nella struttura piatta e in quella ad albero necessita di un aggiornamento per rimuovere il tag dall'elenco.
Interfaccia utente: Eseguire la ricerca usando gli attributi di entità e dei tratti: l'interfaccia utente non esegue la verifica di intervallo e consente di fornire valori fuori dai limiti per tipi di dati integrali e float.
In modalità autonoma con il file system locale HBase registra il messaggio di avviso: Failed to invoke 'unbuffer' method in class org.apache.hadoop.fs.FSDataInputStream. (Impossibile richiamare il metodo 'unbuffer' nella classe org.apache.hadoop.fs.FSDataInputStream)
Il processo Spark viene completato correttamente, ma si verifica un errore di quota disco HDFS esaurita
Scenario: esecuzione di insert overwrite quando è impostata una quota nella cartella Cestino dell'utente che esegue il comando.
Comportamento precedente: il processo ha esito positivo anche se non riesce a spostare i dati nel Cestino. Il risultato può erroneamente contenere alcuni dei dati presenti in precedenza nella tabella.
Nuovo comportamento: quando il trasferimento nella cartella Cestino ha esito negativo, i file vengono eliminati definitivamente.
Kafka 1.0
N/D
Modifiche come documentato nelle Note sulla versione di Apache Spark
Sono richiesti dei criteri Ranger Hive aggiuntivi per INSERT OVERWRITE
Scenario: sono richiesti dei criteri Ranger Hive aggiuntivi per INSERT OVERWRITE
Comportamento precedente: le query INSERT OVERWRITE Hive completate correttamente come di consueto.
Nuovo comportamento: le query INSERT OVERWRITE Hive hanno esito negativo in modo imprevisto dopo l'aggiornamento a HDP 2.6 con l'errore:
Errore durante la compilazione dell'istruzione: FAILED: HiveAccessControlException Permission denied: user jdoe does not have WRITE privilege on /tmp/*(state=42000,code=40000)
A partire da HDP-2.6.0, le query INSERT OVERWRITE Hive richiedono un criterio URI Ranger per consentire operazioni di scrittura, anche se l'utente dispone del privilegio di scrittura concesso tramite il criterio HDFS.
Soluzione alternativa/Azione prevista del cliente:
1. Creare un nuovo criterio nel repository di Hive. 2. Nell'elenco a discesa in cui si visualizza Database, selezionare URI. 3. Aggiornare il percorso (esempio: /tmp/*) 4. Aggiungere gli utenti e il gruppo e salvare. 5. Riprovare a eseguire la query di inserimento.
HDFS
N/D
HDFS deve supportare più KMS Uris
Comportamento precedente: la proprietà dfs.encryption.key.provider.uri era usata per configurare il percorso del provider del Server di gestione delle chiavi.
Nuovo comportamento: la proprietà dfs.encryption.key.provider.uri è deprecata a favore di hadoop.security.key.provider.path per la configurazione del percorso del provider del Server di gestione delle chiavi.
Opzione per la disabilitazione dell'utilità di pianificazione
Componente interessato: Server Zeppelin
Comportamento precedente: nelle versioni precedenti di Zeppelin, non era presente alcuna opzione per la disabilitazione dell'utilità di pianificazione.
Nuovo comportamento: per impostazione predefinita, gli utenti non visualizzeranno più l'utilità di pianificazione, perché è disabilitata per impostazione predefinita.
Soluzione alternativa/Azione prevista del cliente: se si desidera abilitare l'utilità di pianificazione, è necessario aggiungere azeppelin.notebook.cron.enable con valore true nel sito Zeppelin personalizzato nelle impostazioni di Zeppelin da Ambari.
Problemi noti
Integrazione di HDInsight con ADLS Gen 2 I cluster ESP HDInsight che usano Azure Data Lake Storage Gen 2 con autorizzazioni e directory utente presentano due problemi:
Le home directory per gli utenti non vengono create nel nodo head 1. Per risolvere il problema, creare le directory manualmente e modificare la proprietà con l'UPN del rispettivo utente.
Le autorizzazioni per la directory /hdp non sono attualmente impostate su 751. È necessario impostare i valori seguenti:
chmod 751 /hdp
chmod –R 755 /hdp/apps
Spark 2.3
[SPARK-23523][SQL] Risultato non corretto a causa della regola OptimizeMetadataOnlyQuery
I notebook di esempio di Spark non sono disponibili quando Azure Data Lake Storage (Gen2) è l'archivio predefinito del cluster.
Enterprise Security Package
Il server Spark Thrift non accetta connessioni dai client ODBC.
Passaggi della soluzione alternativa:
Attendere circa 15 minuti dopo la creazione del cluster.
Controllare l'interfaccia utente Ranger per verificare l'esistenza di hivesampletable_policy.
Riavviare il servizio Spark.
A questo punto la connessione del servizio token di sicurezza dovrebbe funzionare.
Soluzione alternativa per l'errore del controllo del servizio Ranger
RANGER-1607: soluzione alternativa per l'errore del controllo del servizio Ranger durante l'aggiornamento a HDP 2.6.2 dalle precedenti versioni HDP.
Nota
Solo quando Ranger è abilitato per SSL.
Questo problema si verifica quando si prova a eseguire l'aggiornamento a HDP 2.6.1 dalle precedenti versioni HDP tramite Ambari. Ambari usa una chiamata Curl eseguire una verifica del servizio Ranger in Ambari. Se la versione JDK usata da Ambari è JDK 1.7, la chiamata Curl avrà esito negativo con l'errore seguente:
La causa di questo errore è che la versione di Tomcat usata in Ranger è Tomcat-7.0.7*. L'uso di JDK 1.7 è in conflitto con crittografie predefinite fornite in Tomcat-7.0.7*.
È possibile risolvere questo problema in due modi:
Aggiornare il pacchetto JDK usato in Ambari di JDK 1.7 a JDK 1.8 (vedere la sezione Change the JDK Version (modificare la versione di JDK) nella Guida di riferimento di Ambari).
Se si desidera continuare a supportare un ambiente JDK 1.7:
Aggiungere la proprietà ranger.tomcat.ciphers nella sezione ranger-admin-site nella configurazione Ambari Ranger con il valore seguente:
Se l'ambiente è configurato per il Server di gestione delle chiavi Ranger, aggiungere la proprietà ranger.tomcat.ciphers nella sezione theranger-kms-site nella configurazione di Ambari Ranger con il valore seguente:
I valori annotati sono esempi e potrebbero non essere indicativi dell'ambiente. Assicurarsi che il modo in cui si impostano queste proprietà corrisponda al modo in cui è configurato l'ambiente.
RangerUI: Escape del testo della condizione dei criteri immesso nel modulo criteri
Componente interessato: Ranger
Descrizione del problema
Se un utente desidera creare criteri con condizioni personalizzate e l'espressione o il testo contiene caratteri speciali, l'imposizione dei criteri non funzionerà. I caratteri speciali vengono convertiti in caratteri ASCII prima di salvare il criterio nel database.
Caratteri speciali: e <> " ` '
La condizione tags.attributes['type']='abc' ad esempio verrebbe convertita nel modo seguente dopo il salvataggio dei criteri.
tags.attds['dsds']='cssdfs'
È possibile visualizzare la condizione del criterio con questi caratteri aprendo il criterio in modalità di modifica.
Soluzione alternativa
Opzione 1: creare/aggiornare i criteri tramite l'API REST di Ranger
L'esempio seguente creerà criteri con tag come "tag-test" e li assegnerà al gruppo "public" con la condizione "astags.attr['type']=='abc" selezionando tutte le autorizzazioni dei componenti Hive, ad esempio selezione, aggiornamento, creazione, rilascio, modifica, indicizzazione, blocco, tutto.
Aggiornamento di criteri esistenti con condizioni:
L'esempio seguente aggiornerà i criteri con tag come "tag-test" e li assegnerà al gruppo public con la condizione "astags.attr'type'=='abc" selezionando tutte le autorizzazioni dei componenti Hive, ad esempio selezione, aggiornamento, creazione, rilascio, modifica, indicizzazione, blocco, tutto.
Trovare il file PermissionList.js in /usr/hdp/current/ranger-admin
Trovare la definizione della funzione renderPolicyCondtion (N. riga: 404).
Rimuovere la riga seguente da tale funzione, ovvero sotto la funzione di visualizzazione (riga n. 434)
val = _.escape(val);//Line No:460
Dopo aver rimosso la riga precedente, l'interfaccia utente di Ranger consentirà di creare criteri con condizione che possano contenere caratteri speciali e la valutazione del criterio sarà corretta.
Integrazione di HDInsight con ADLS Gen 2: problema di autorizzazioni e directory utente con i cluster ESP 1. Le home directory per gli utenti non vengono create nel nodo head 1. Per risolvere il problema, creare le directory manualmente e modificare la proprietà con l'UPN del rispettivo utente.
2. Le autorizzazioni per /hdp non sono attualmente impostate su 751. Deve essere impostato su: a. chmod 751 /hdp b. chmod –R 755 /hdp/apps
Deprecazione
Portale di OMS: è stato rimosso il collegamento dalla pagina delle risorse HDInsight che puntava al portale di OMS. In precedenza Monitoraggio di Azure usava il proprio portale, denominato portale di OMS, per gestire la configurazione e l'analisi dei dati raccolti. Tutte le funzionalità di questo portale sono state spostate al portale di Azure in cui continueranno a essere sviluppate. HDInsight ha deprecato il supporto per il portale di OMS. I clienti useranno l'integrazione dei log di Monitoraggio di Azure in HDInsight nel portale di Azure.
Tutte queste funzionalità sono disponibili in HDInsight 3.6. Per ottenere la versione più recente di Spark, Kafka e R Server (Machine Learning Services), scegliere la versione di Spark, Kafka e ML Services quando si crea un cluster HDInsight 3.6. Per ottenere il supporto per ADLS, è possibile scegliere il tipo di archiviazione ADLS come un'opzione. I cluster esistenti non verranno aggiornati automaticamente a queste versioni.
Tutti i nuovi cluster creati dopo giugno 2018 otterranno automaticamente le correzioni di più di 1000 bug in tutti i progetti open source. Seguire questa guida per le procedure consigliate per l'aggiornamento a una versione più recente di HDInsight.
Dimostrare di possedere le competenze necessarie per implementare i controlli di sicurezza, gestire la postura di sicurezza di un'organizzazione e identificare e correggere le vulnerabilità della sicurezza.
 Presto disponibile
Presto disponibile Novità
Novità