Gestire la sessione di calcolo del prompt flow in studio di Azure Machine Learning
Una sessione di calcolo del prompt flow fornisce le risorse di calcolo necessarie per l'esecuzione dell'applicazione, inclusa un'immagine Docker contenente tutti i pacchetti di dipendenza necessari. Questo ambiente affidabile e scalabile consente al prompt flow di eseguire in modo efficiente le attività e le funzioni, per un'esperienza utente ottimale.
Autorizzazioni e ruoli per la gestione delle sessioni di calcolo
Per assegnare ruoli, è necessario avere l'autorizzazione owner o Microsoft.Authorization/roleAssignments/write per la risorsa.
Per gli utenti della sessione di calcolo, assegnare il ruolo AzureML Data Scientist nell'area di lavoro. Per altre informazioni, vedere Gestire l'accesso a un'area di lavoro di Azure Machine Learning.
L'assegnazione di ruolo può richiedere alcuni minuti.
Avviare una sessione di calcolo in studio
Prima di avviare una sessione di calcolo con studio di Azure Machine Learning, assicurarsi che:
- Il ruolo
AzureML Data Scientistè disponibile nell'area di lavoro. - L'archivio dati predefinito (in genere
workspaceblobstore) nell'area di lavoro è di tipo BLOB. - La directory di lavoro (
workspaceworkingdirectory) è presente nell'area di lavoro. - Se si usa una rete virtuale per il prompt flow, è necessario comprendere quanto descritto in Isolamento rete nel prompt flow.
Avviare una sessione di calcolo in una pagina del flusso
Un flusso si associa a una sessione di calcolo. È possibile avviare una sessione di calcolo in una pagina del flusso.
Selezionare Inizio. Avviare una sessione di calcolo usando l'ambiente definito in
flow.dag.yamlnella cartella del flusso, viene eseguito sulla dimensione della macchina virtuale (VM) dell’elaborazione serverless con una quota sufficiente nell'area di lavoro.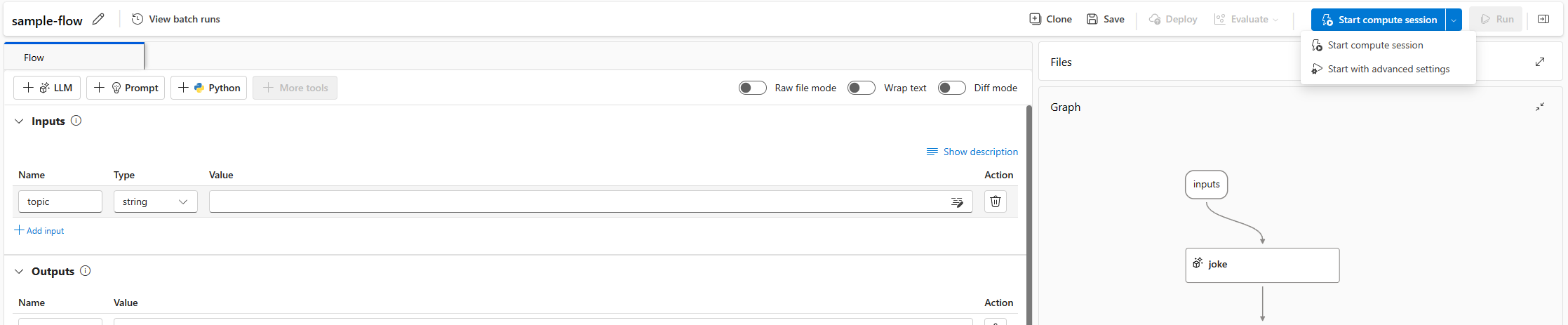
Selezionare Inizia con le impostazioni avanzate. Le impostazioni avanzate consentono di:
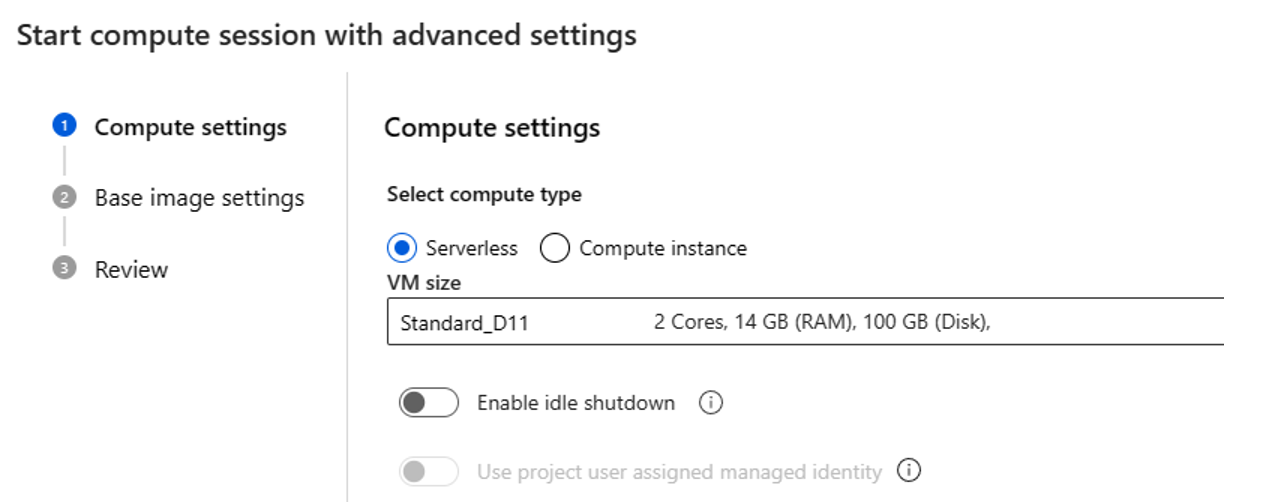
- Selezionare il tipo di ambiente di calcolo. È possibile scegliere tra elaborazione serverless e l'istanza di ambiente di calcolo.
Se si sceglie un ambiente di calcolo serverless, è possibile configurare le impostazioni seguenti:
- Personalizzare le dimensioni VM usate dalla sessione di calcolo. Scegliere VM della serie D e successive. Per altre informazioni, vedere la sezione Serie e dimensioni delle di macchine virtuali supportate
- Personalizzare il tempo di inattività: elimina automaticamente la sessione di calcolo se non è in uso per un periodo di tempo.
- Impostare l'identità gestita assegnata dall'utente. La sessione di calcolo usa questa identità per eseguire il pull di un'immagine di base, l'autenticazione con connessione e l'installazione dei pacchetti. Accertare che l'identità gestita assegnata dall'utente disponga di autorizzazioni sufficienti. Se non si imposta questa identità, per impostazione predefinita viene usata l'identità utente.
- Il comando dell'interfaccia della riga di comando seguente consente di assegnare l'identità gestita assegnata dall'utente per l'area di lavoro. Informazioni su come creare e aggiornare le identità assegnate dall'utente per un'area di lavoro.
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>I cui contenuti di workspace_update_with_multiple_UAIs.yml sono i seguenti:
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}Suggerimento
Le seguenti assegnazioni di ruolo Controllo degli accessi in base al ruolo di Azure sono richieste sull'identità gestita assegnata dall'utente affinché l'area di lavoro di Azure Machine Learning possa accedere ai dati sulle risorse associate all'area di lavoro.
Conto risorse Autorizzazione Azure Machine Learning workspace (Area di lavoro di Azure Machine Learning) Collaboratore Archiviazione di Azure Collaboratore (piano di controllo) + Collaboratore dati del BLOB di archiviazione + Collaboratore con privilegi dei dati del file di archiviazione (piano dati, bozza di flusso di consumo nella condivisione file e nei dati nel BLOB) Azure Key Vault (quando si utilizza il modello di autorizzazioni Criteri di accesso) Collaboratore e qualsiasi autorizzazione per i criteri di accesso escluse le operazioni di rimozione definitiva, ovvero la modalità predefinita per Azure Key Vault collegato. Azure Key Vault (quando si utilizza il modello di autorizzazioni Controllo degli accessi in base al ruolo) Collaboratore (piano di controllo) + Amministratore Key Vault (piano dati) Registro Azure Container Collaboratore Azure Application Insights Collaboratore Nota
La persona che invia la richiesta del processo deve disporre dell'autorizzazione
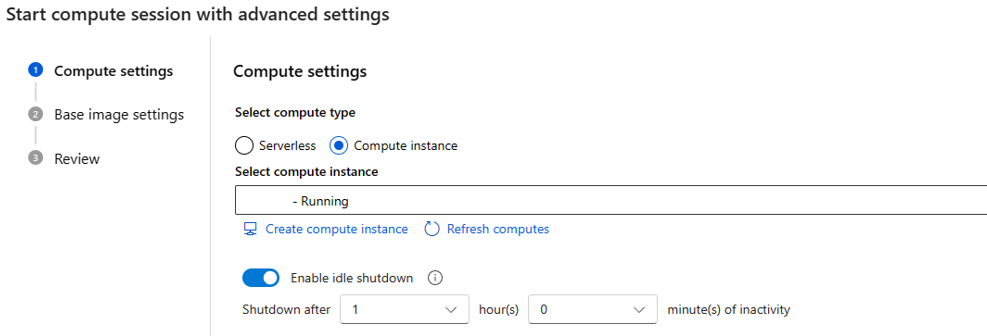
assignsull'identità gestita assegnata dall'utente, è possibile assegnare il ruoloManaged Identity Operator, in modo che ogni volta in cui viene creata una sessione di calcolo serverless, assegnerà l'identità gestita assegnata dall'utente per il calcolo.Se come tipo di calcolo si sceglie l'istanza di ambiente di calcolo, è possibile impostare solo l'ora di arresto inattivo.
Poiché è in esecuzione in un'istanza di ambiente di calcolo esistente, le dimensioni VM sono fisse e non possono cambiare sul lato sessione.
L'identità usata per questa sessione viene definita anche nell'istanza di ambiente di calcolo. Per impostazione predefinita usa l'identità utente. Altre informazioni su come assegnare l'identità all'istanza di ambiente di calcolo
Per il tempo di arresto inattivo usato per definire il ciclo di vita della sessione di calcolo, se la sessione rimane inattiva per il tempo impostato, viene eliminata automaticamente. E se nell’istanza di ambiente di calcolo è abilitato l'arresto inattivo, diventa effettivo dal livello di calcolo.
Altre informazioni su come creare e gestire un'istanza di ambiente di calcolo
- Selezionare il tipo di ambiente di calcolo. È possibile scegliere tra elaborazione serverless e l'istanza di ambiente di calcolo.



Usare una sessione di calcolo per inviare un'esecuzione del flusso nell'interfaccia della riga di comando/SDK
Quando si invia un'esecuzione del flusso, oltre a studio, è possibile specificare la sessione di calcolo nell'interfaccia della riga di comando/SDK.
Inoltre è possibile specificare il tipo di istanza o il nome dell'istanza di ambiente di calcolo nella parte della risorsa. Se non si specifica il tipo di istanza o il nome dell’istanza di ambiente di calcolo, Azure Machine Learning sceglie un tipo di istanza (dimensioni VM) in base a fattori quali quota, costo, prestazioni e dimensioni del disco. Altre informazioni su elaborazione serverless.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
Inviare l'esecuzione tramite l'interfaccia della riga di comando:
pfazure run create --file run.yml
Nota
L'arresto inattivo ha la durata di un'ora se si usa l'interfaccia della riga di comando/SDK per inviare un'esecuzione del flusso. È possibile passare alla pagina di calcolo e rilasciare il calcolo.
File di riferimento esterno alla cartella del flusso
In alcuni casi, è possibile fare riferimento a un file requirements.txt esterno alla cartella del flusso. Si potrebbe ad esempio avere un progetto complesso che include più flussi che condividono lo stesso file requirements.txt. A tale scopo, è possibile aggiungere questo campo additional_includes in flow.dag.yaml. Il valore di questo campo è un elenco del percorso di file/cartella relativo alla cartella del flusso. Se ad esempio il file requirements.txt si trova nella cartella padre della cartella del flusso, è possibile aggiungere ../requirements.txt al campo additional_includes.
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
Il file requirements.txt viene copiato nella cartella del flusso, e lo usa per avviare la sessione di calcolo.
Aggiornare una sessione di calcolo nella pagina del flusso in studio
In una pagina del flusso è possibile gestire una sessione di calcolo mediante le opzioni seguenti :
- Modificare le impostazioni della sessione di calcolo, si modificano le impostazioni di calcolo, ad esempio le dimensioni VM e l'identità gestita assegnata dall'utente per l’elaborazione serverless. Se si usa l'istanza di ambiente di calcolo, è possibile modificare per usare un'altra istanza. Inoltre è possibile modificare
- l'identità gestita assegnata dall'utente per l’elaborazione serverless. Se si modificano le dimensioni VM, la sessione di calcolo viene reimpostata con le nuove dimensioni della macchina virtuale. Se…
- Installare i pacchetti da requirements.txt Aprire
requirements.txtnell'interfaccia utente del prompt flow, in cui è possibile aggiungerli. - Visualizza pacchetti installati mostra i pacchetti installati nella sessione di calcolo. Include i pacchetti installati per l'immagine di base e i pacchetti specificati nel file
requirements.txtnella cartella del flusso. - Reimposta la sessione di calcolo elimina la sessione di calcolo corrente e ne crea una nuova con lo stesso ambiente. Se si verifica un problema di conflitto dei pacchetti, è possibile provare a usare questa opzione.
- Arrestare la sessione di calcolo elimina la sessione di calcolo corrente. Se nel calcolo sottostante non è presente alcuna sessione di calcolo attiva, verrà eliminata anche la risorsa di elaborazione serverless.

È anche possibile personalizzare l'ambiente usato per eseguire il flusso aggiungendo pacchetti nel file requirements.txt nella cartella del flusso. Dopo aver aggiunto altri pacchetti in questo file, è possibile scegliere una di queste opzioni:
- Salva e installa: attiva
pip install -r requirements.txtnella cartella del flusso. Il processo può richiedere alcuni minuti, a seconda dei pacchetti installati. - Salva solamente: esegue solo il salvataggio del file
requirements.txt. È possibile installare i pacchetti manualmente in un secondo momento.

Nota
È possibile modificare il percorso e anche il nome file di requirements.txt, ma assicurarsi di apportare le modifiche anche nel file flow.dag.yaml nella cartella del flusso.
Non aggiungere la versione di promptflow e promptflow-tools in requirements.txt: le versioni sono già incluse nell'immagine di base della sessione.
requirements.txt non supporterà i file dei wheel locali. Compilarli nell'immagine e aggiornare l'immagine di base personalizzata in flow.dag.yaml. Altre informazioni su come compilare un'immagine di base personalizzata.
Aggiungere pacchetti in un feed privato in Azure DevOps
Se si vuole usare un feed privato in Azure DevOps, seguire questa procedura:
Assegnare l'identità gestita all'area di lavoro o all'istanza di ambiente di calcolo.
Per usare l’elaborazione serverless come sessione di calcolo, è necessario assegnare all'area di lavoro l'identità gestita assegnata dall'utente.
Creare un'identità gestita assegnata dall'utente e aggiungerla nell'organizzazione Azure DevOps. Per altre informazioni, vedere Usare entità servizio e identità gestite.
Nota
Se il pulsante Aggiungi utenti non è visibile, probabilmente non si dispone delle autorizzazioni necessarie per eseguire questa azione.
Aggiungere o aggiornare le identità assegnate dall'utente in un'area di lavoro.
Nota
Accertare che l'identità gestita assegnata dall'utente abbia
Microsoft.KeyVault/vaults/readnel keyvault collegato all'area di lavoro.
Per usare l'istanza di ambiente di calcolo come sessione di calcolo, è necessario assegnare un'identità gestita assegnata dall'utente a un'istanza di ambiente di calcolo.
Aggiungere
{private}all'URL del feed privato. Se ad esempio si vuole installaretest_packagedatest_feedin Azure DevOps, aggiungere-i https://{private}@{test_feed_url_in_azure_devops}inrequirements.txt:-i https://{private}@{test_feed_url_in_azure_devops} test_packageSpecificare l'uso dell'identità gestita assegnata dall'utente nella configurazione della sessione di calcolo.
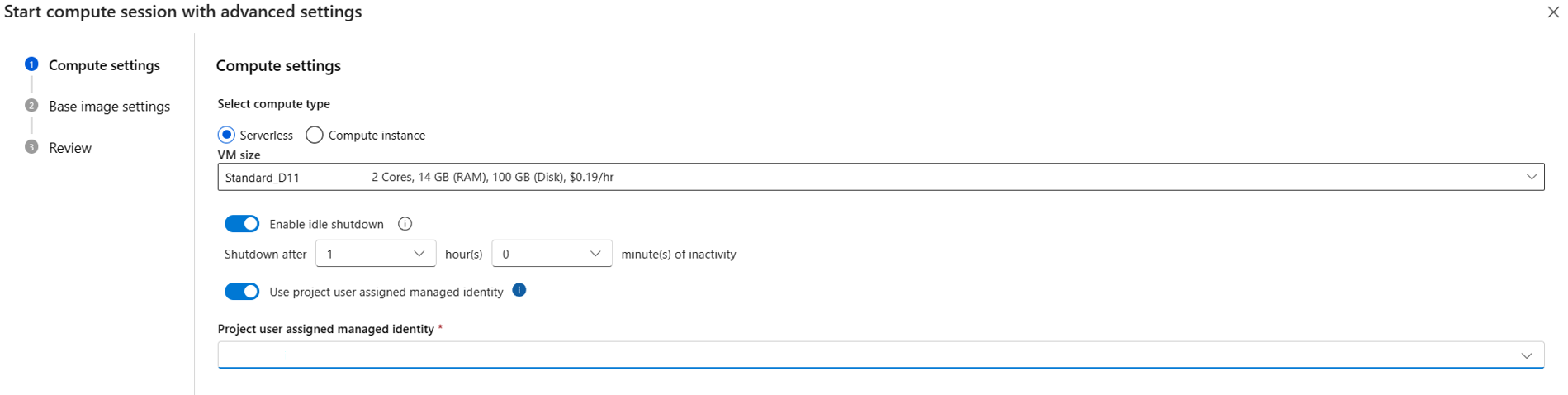
Se si usa l’elaborazione serverless, specificare l'identità gestita assegnata dall'utente in Iniziare con le impostazioni avanzate se la sessione di calcolo non è in esecuzione; altrimenti usare il pulsante Modifica impostazioni sessione di calcolo se la sessione di calcolo è in esecuzione.
Se si usa l'istanza di ambiente di calcolo, usa l'identità gestita assegnata dall'utente che è stata assegnata all'istanza di calcolo.

Nota
Questo approccio è incentrato principalmente sui test rapidi nella fase di sviluppo del flusso. Se si vuole distribuire questo flusso come endpoint, compilare questo feed privato nell'immagine e aggiornare la personalizzazione dell'immagine di base in flow.dag.yaml. Altre informazioni su come compilare un'immagine di base personalizzata
Modificare l'immagine di base per la sessione di calcolo
Per impostazione predefinita, viene usata l'immagine di base prompt flow più recente. Se si vuole usare un'immagine di base diversa, è possibile creare un'immagine personalizzata.
- In studio è possibile modificare l'immagine di base nelle impostazioni dell'immagine di base, in impostazioni della sessione di calcolo.

È anche possibile specificare la nuova immagine di base in
environmentnel fileflow.dag.yaml, nella cartella del flusso.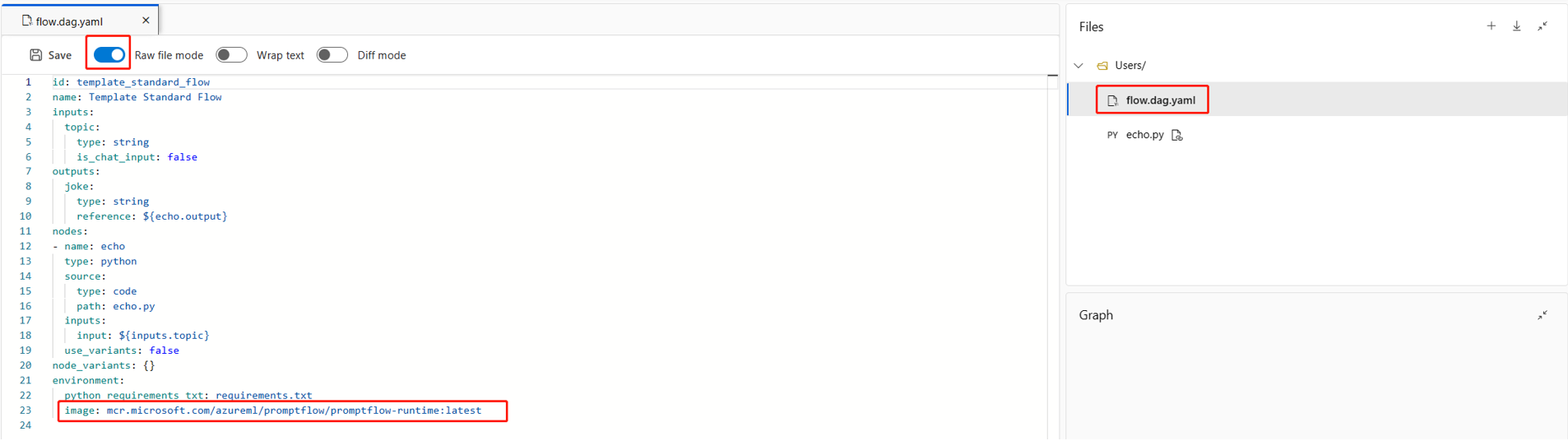
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

Per usare la nuova immagine di base, è necessario reimpostare la sessione di calcolo. Questo processo richiede alcuni minuti perché esegue il pull della nuova immagine di base e reinstalla i pacchetti.
Gestire l'istanza serverless usata dalla sessione di calcolo
L’uso dell’elaborazione serverless come sessione di calcolo, consente di gestire l'istanza serverless. Visualizzare l'istanza serverless nella scheda elenco delle sessioni di calcolo nella pagina di calcolo.

Inoltre nella scheda Flussi ed esecuzioni attivi, è possibile accedere ai flussi e alle esecuzioni eseguite nel calcolo. L'eliminazione dell'istanza influisce sul flusso e viene eseguita in nello stesso.

Relazione tra la sessione di calcolo, la risorsa di calcolo, il flusso e l’utente
- Un singolo utente può avere più risorse di calcolo (istanza di ambiente di calcolo o serverless). Date le diverse esigenze, un singolo utente può avere più risorse di calcolo. Ad esempio, un utente può avere più risorse di calcolo con dimensioni VM o identità gestita assegnata dall'utente diverse.
- Una risorsa di calcolo può essere usata solo da un singolo utente. Una risorsa di calcolo viene usata come box di sviluppo privato di un singolo utente. Più utenti non possono condividere le stesse risorse di calcolo.
- Una risorsa di calcolo può ospitare più sessioni di calcolo. Una sessione di calcolo è un contenitore in esecuzione in una risorsa di calcolo sottostante. Ad esempio, la creazione del prompt flow non richiede troppe risorse di calcolo, quindi una sola risorsa di calcolo può ospitare più sessioni di calcolo dello stesso utente.
- Una sessione di calcolo appartiene a una singola risorsa di calcolo alla volta. Tuttavia è possibile eliminare o arrestare una sessione di calcolo, e allocarla di nuovo in un'altra risorsa di calcolo.
- Un flusso può avere una sola sessione di calcolo. Ogni flusso è indipendente e definisce l'immagine di base e i pacchetti Python necessari, nella cartella del flusso per la sessione di calcolo.
Passare tra runtime e sessione di calcolo
Rispetto ai runtime dell'istanza di ambiente di calcolo, le sessioni di calcolo presentano i vantaggi seguenti:
- Gestione automatica del ciclo di vita della sessione e del calcolo sottostante. Non è più necessario eseguire manualmente le attività di creazione e gestione.
- Semplice personalizzazione dei pacchetti tramite l'aggiunta di pacchetti nel file
requirements.txtnella cartella del flusso, senza che sia necessario creare un ambiente personalizzato.
Passare da un runtime dell’istanza di ambiente di calcolo a una sessione di calcolo attenendosi alla procedura seguente:
- Preparare il file
requirements.txtnella cartella del flusso. Assicurarsi di non aggiungere la versione dipromptflowepromptflow-toolsinrequirements.txt, perché le versioni sono già incluse nell'immagine di base. All’avvio, la sessione di calcolo installa i pacchetti nel filerequirements.txt. - Se si crea un ambiente personalizzato per il runtime dell’istanza di ambiente di calcolo, è anche possibile ottenere l'immagine dalla pagina dei dettagli dell'ambiente e specificarla nel file
flow.dag.yaml, nella cartella del flusso. Per altre informazioni, vedere Modificare l'immagine di base per la sessione di calcolo. Assicurarsi che l'identità gestita assegnata dall'utente correlato nell'area di lavoro abbia l’autorizzazioneacr pullper l'immagine.

- Per la risorsa di calcolo, è possibile continuare a usare l'istanza di ambiente di calcolo esistente, se si desidera gestire manualmente il ciclo di vita. Altrimenti provare a eseguire l’elaborazione serverless il cui ciclo di vita è gestito dal sistema.