Identificazione di informazioni riservate e classificate per la sicurezza per la conformità del governo australiano con PSPF
Questo articolo fornisce indicazioni per le organizzazioni governative australiane sull'uso di Microsoft Purview per identificare informazioni riservate e classificate per la sicurezza. Il suo scopo è quello di aiutare tali organizzazioni a rafforzare il loro approccio alla sicurezza dei dati e la loro capacità di soddisfare i requisiti descritti in Protective Security Policy Framework (PSPF) e Information Security Manual (ISM).
La chiave per proteggere le informazioni e proteggerle dalla perdita di dati è innanzitutto comprendere quali sono le informazioni. Questo articolo illustra i metodi per identificare le informazioni in un ambiente Microsoft 365 delle organizzazioni. Questi approcci sono spesso definiti aspetti noti dei dati di Microsoft Purview. Una volta identificate, le informazioni possono quindi essere protette sia tramite l'etichettatura automatica di riservatezza che la prevenzione della perdita dei dati(DLP).
Tipi di informazioni riservate
I tipi di informazioni sensibili (SIT) sono classificatori basati su pattern. Rilevano informazioni sensibili tramite espressioni regolari (RegEx) o parole chiave.
Esistono molti tipi diversi di SIT rilevanti per le organizzazioni governative australiane:
- SIED predefinito creato da Microsoft, molti dei quali sono allineati con i tipi di dati australiani comuni.
- I SIT personalizzati vengono creati in base ai requisiti dell'organizzazione.
- I SIT di entità denominate includono identificatori complessi basati su dizionario, ad esempio indirizzi fisici australiani.
- I SIT exact data match (EDM) vengono generati in base ai dati sensibili effettivi.
- I SIT di impronta digitale dei documenti si basano sul formato dei documenti anziché sul relativo contenuto.
- I SIT rilevanti per la sicurezza della rete o delle informazioni , anche se tecnicamente predefiniti, hanno particolare rilevanza per i team informatici che lavorano per le organizzazioni governative australiane, e così sono degni della propria categoria.
Tipi di informazioni riservate predefiniti
I tipi di informazioni sensibili predefiniti si basano su tipi comuni di informazioni che i clienti considerano in genere sensibili. Questi possono essere generici e avere rilevanza globale (ad esempio, numeri di carta di credito) o avere rilevanza locale (ad esempio, numeri di conto bancario australiani).
L'elenco completo di SIT predefiniti di Microsoft è disponibile nelle definizioni di entità del tipo di informazioni riservate
I SIT specifici dell'Australia includono:
- Numero di conto bancario australiano
- Numero di patente australiano
- Numero di passaporto australiano
- Indirizzi fisici australiani
- Numero di file fiscale australiano
- Numero di azienda australiano
- Numero della società australiana
- Numero di conto medico australiano
Questi SIT sono disponibili nel portale di classificazione dei dati di Microsoft Purview in Tipidi informazioni sensibiliper classificatori>.
I SIT predefiniti sono utili per le organizzazioni che iniziano il percorso di Information Protection o governance, perché offrono un vantaggio verso l'abilitazione di funzionalità come la prevenzione della perdita dei dati e l'etichettatura automatica. I due modi più semplici per usare questi SIT sono:
Uso di SIT predefiniti tramite modelli di criteri DLP
Alcuni SIT predefiniti sono inclusi nei modelli di criteri DLP creati da Microsoft in linea con le normative australiane. I modelli di criteri DLP seguenti, allineati ai requisiti australiani, sono disponibili per l'uso:
- Australia Privacy Act migliorato
- Dati finanziari Australia
- PCI Data Security Standard (PCI DSS)
- Dati di identificazione personale (PII) in Australia
L'abilitazione dei criteri DLP basati su questi modelli consente il monitoraggio iniziale degli eventi di perdita dei dati, che costituiscono un ottimo punto di partenza per le organizzazioni che introducono Microsoft 365 DLP. Una volta distribuiti, questi criteri forniscono informazioni dettagliate sull'entità di un problema di perdita di dati delle organizzazioni e possono contribuire a prendere decisioni sui passaggi successivi.
L'uso di questi modelli di criteri viene ulteriormente esaminato per limitare la distribuzione di informazioni riservate.
Uso di SIT predefiniti nell'etichettatura automatica di riservatezza
Se viene rilevato che un elemento contiene un numero di conto medico australiano, una o più condizioni mediche e un nome completo, potrebbe essere giusto presumere che l'elemento contenga informazioni mediche personali e possa costituire un registro sanitario. In base a questo presupposto, è possibile suggerire a un utente di etichettare l'elemento come "OFFICIAL: Sensitive Personal Privacy" o qualsiasi etichetta più appropriata nell'organizzazione per l'identificazione e la protezione dei record sanitari.
Per altre informazioni su come questa funzionalità può aiutare le organizzazioni governative a soddisfare la conformità PSPF, vedere applicazione automatica di etichette di riservatezza e scenari di etichettatura automatica basati su client per il governo australiano.
Tipi di informazioni sensibili personalizzati
Oltre ai SIT predefiniti, le organizzazioni possono creare SIT in base alle proprie definizioni di informazioni riservate. Esempi di informazioni rilevanti per le organizzazioni governative australiane che potrebbero essere identificate tramite SIT personalizzato sono:
- Contrassegni protettivi
- ID di autorizzazione o ID applicazione di autorizzazione
- Classificazioni da altri stati o territori
- Classificazioni che non devono essere visualizzate nella piattaforma (ad esempio, TOP SECRET)
- Briefing o corrispondenza dei ministri
- Numero richiesta libertà di informazione (FOI)
- Informazioni correlate alla probabilità
- Termini relativi a sistemi, progetti o applicazioni sensibili
- Contrassegni di paragrafo
- Numeri di record trim o objective
I SIT personalizzati sono costituiti da un identificatore primario, che può essere basato su un'espressione regolare o parole chiave, livello di attendibilità e elementi di supporto facoltativi.
Per una spiegazione più dettagliata dei SIT e dei relativi componenti, vedere Informazioni sui tipi di informazioni sensibili.
Espressioni regolari (RegEx)
Le espressioni regolari sono identificatori basati su codice che possono essere usati per identificare i modelli di informazioni. Ad esempio, se un numero foi (Freedom of Information) era costituito dalle lettere FOI seguite da un anno a quattro cifre, un trattino e altre tre cifre (ad esempio, FOI2023-123), potrebbe essere rappresentato in un'espressione regolare di:
[Ff][Oo][Ii]20[01234]\d{1}-\d{3}
Per spiegare questa espressione:
-
[Ff][Oo][Ii]corrisponde a lettere maiuscole o minuscole F, O e I. -
20corrisponde al numero 20 come primo semestre di un anno a quattro cifre. -
[0123]corrisponde a 0, 1, 2 o 3 nella terza cifra del valore dell'anno a quattro cifre, che ci consente di corrispondere ai numeri FOI dall'anno 2000 al 2039. -
-corrisponde a un trattino. -
\d{3}corrisponde a tre cifre.
Consiglio
Copilot è piuttosto adatto alla generazione di espressioni regolari (RegEx). È possibile usare il linguaggio naturale per chiedere a Copilot di generare RegEx automaticamente.
Elenco di parole chiave o dizionario di parole chiave
Gli elenchi di parole chiave e i dizionari sono costituiti da parole, termini o frasi che probabilmente verranno inclusi negli elementi che si sta cercando di identificare. briefing di gabinetto o applicazione di gara sono termini che potrebbero essere utili come parole chiave.
Le parole chiave possono fare distinzione tra maiuscole e minuscole o senza distinzione tra maiuscole e minuscole. Case può essere utile per eliminare i falsi positivi. Ad esempio, la minuscola official è più probabile che venga usata nella conversazione generale, ma maiuscola OFFICIAL ha una maggiore probabilità di far parte di un contrassegno protettivo.
I dizionari di parole chiave contenenti set di dati di grandi dimensioni possono anche essere caricati in formato CSV o TXT . Per altre informazioni sul caricamento di un dizionario di parole chiave, vedere come creare un dizionario di parole chiave.
Livello di probabilità
Alcune parole chiave o espressioni regolari possono fornire una corrispondenza accurata senza necessità di perfezionamento. L'espressione libertà di informazione (FOI) inclusa nell'esempio precedente di un valore è improbabile che venga visualizzata in una conversazione generale e quando appare in corrispondenza, è probabile che corrisponda a informazioni rilevanti. Tuttavia, se stavamo cercando di trovare una corrispondenza con un numero di dipendenti del servizio pubblico australiano, rappresentato come otto cifre numeriche, è probabile che la corrispondenza provocherà numerosi falsi positivi. Il livello di attendibilità consente di assegnare una probabilità che la presenza della parola chiave o del modello in un elemento, ad esempio un messaggio di posta elettronica o un documento, sia effettivamente ciò che si sta cercando. Per altre informazioni sui livelli di attendibilità, vedere Gestione dei livelli di attendibilità.
Elementi primari e di supporto
I SIT personalizzati hanno anche un concetto di elementi primari e di supporto. L'elemento primario è il modello di chiave che si vuole rilevare nel contenuto. Gli elementi di supporto possono essere aggiunti a un elemento primario per compilare un caso per l'occorrenza di un valore come corrispondenza accurata. Ad esempio, se si tenta di trovare una corrispondenza in base a un numero di dipendente di otto cifre numerico, è possibile usare le parole chiave "numero dipendente" o Australian Government Number AGSo Australian Public Service Employee Database APSED come elemento di supporto per aumentare la sicurezza che la corrispondenza sia rilevante. Per altre informazioni su come creare elementi primari e di supporto, vedere Informazioni sugli elementi.
Prossimità dei caratteri
Il valore finale che in genere si configurerebbe in un SIT è la prossimità dei caratteri. Questa è la distanza tra elementi primari e elementi di supporto. Se si prevede che la parola chiave AGS sia vicina al valore numerico di otto cifre, viene configurata una prossimità di 10 caratteri. Se è probabile che gli elementi primari e di supporto non vengano visualizzati uno accanto all'altro, il valore di prossimità viene impostato su un numero maggiore di caratteri. Per altre informazioni su come creare la prossimità dei caratteri, vedere Informazioni sulla prossimità.
SIT per identificare i contrassegni protettivi
Un modo prezioso per le organizzazioni governative australiane di utilizzare i SIT personalizzati consiste nell'identificare i contrassegni protettivi. In un'organizzazione Greenfield, a tutti gli elementi di un ambiente è applicata un'etichetta di riservatezza. Tuttavia, la maggior parte delle organizzazioni governative ha un'etichettatura legacy che richiede la modernizzazione di Microsoft Purview. I SIT vengono usati per identificare e applicare contrassegni a:
- File legacy contrassegnati
- File contrassegnati generati da entità esterne
- Email conversazioni avviate e contrassegnate esternamente
- Messaggi di posta elettronica che hanno perso le informazioni sull'etichetta (intestazioni x)
- Messaggi di posta elettronica che hanno subito un downgrade errato delle etichette
Quando viene identificato un marcatore di questo tipo, l'utente viene informato del rilevamento e viene fornita una raccomandazione per l'etichetta. Se accettano la raccomandazione, le protezioni basate su etichetta si applicano all'elemento. Questi concetti sono ulteriormente illustrati negli scenari di etichettatura automatica basati sul client per il governo australiano.
I SIT basati sulla classificazione sono utili anche in DLP. Alcuni esempi:
- Un utente riceve informazioni e le identifica come sensibili tramite il relativo contrassegno, ma non vuole riclassificarle in quanto non si traduce in una classificazione PSPF (ad esempio, 'OFFICIAL Sensitive WALES Government'). La creazione di un criterio DLP per proteggere le informazioni racchiuse in base al contrassegno anziché all'etichetta applicata significa che è possibile applicare una misura di sicurezza dei dati.
- Un utente copia il testo da una conversazione di posta elettronica, che include un contrassegno protettivo. Incollare le informazioni in una chat di Teams con un partecipante esterno che non deve avere accesso alle informazioni. Tramite un criterio DLP applicato al servizio Teams, è possibile rilevare il contrassegno e impedire la divulgazione.
- Un utente effettua erroneamente il downgrade di un'etichetta di riservatezza in una conversazione di posta elettronica (in modo dannoso o per errore dell'utente). Poiché i contrassegni protettivi sono stati applicati al messaggio di posta elettronica in precedenza sono visibili nel corpo del messaggio di posta elettronica, Microsoft Purview rileva che i contrassegni corrente e precedente sono disallineati. A seconda della configurazione, l'azione registra l'evento, avvisa l'utente o blocca il messaggio di posta elettronica.
- Un messaggio di posta elettronica contrassegnato viene inviato a un destinatario esterno che usa una piattaforma o un client di posta elettronica non aziendale. La piattaforma o il client rimuove i metadati (x-header) del messaggio di posta elettronica, in modo che il messaggio di posta elettronica di risposta del destinatario esterno non abbia un'etichetta di riservatezza applicata quando arriva alla cassetta postale utente dell'organizzazione. Il rilevamento del contrassegno precedente tramite sit consente di riapplicare l'etichetta in modo trasparente o consiglia all'utente di riapplicare l'etichetta alla risposta successiva.
In ognuno di questi scenari, i SIT basati sulla classificazione possono essere usati per rilevare i contrassegni protettivi applicati e attenuare la potenziale violazione dei dati.
Sintassi SIT di esempio per rilevare i contrassegni protettivi
Le espressioni regolari seguenti possono essere usate nei SIT personalizzati per identificare i contrassegni protettivi.
Importante
La creazione di SIT per identificare i contrassegni protettivi facilita la conformità PSPF. I SIT basati sulla classificazione vengono usati anche negli scenari di prevenzione della perdita dei dati e di etichettatura automatica.
| Nome SIT | Espressione regolare |
|---|---|
| REGEX NON UFFICIALE1 | UNOFFICIAL |
| OFFICIAL Regex1,2 | (?<!UN)OFFICIAL |
| OFFICIAL Sensitive Regex1,3,4,5 | OFFICIAL[:- ]\s?Sensitive(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET) |
| OFFICIAL Sensitive Personal Privacy Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| OFFICIAL Sensitive Legal Privilege Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| OFFICIAL Sensitive Legislative Secrecy Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| OFFICIAL Sensitive NATIONAL CABINET Regex1,4,5 | OFFICIAL[:- ]\s?Sensitive(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| PROTECTED Regex1,3,5 | PROTECTED(?!,\sACCESS=)(?!(?:\s\|\/\/\|\s\/\/\s)[Pp]ersonal[- ][Pp]rivacy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egislative[- ][Ss]ecrecy)(?!(?:\s\|\/\/\|\s\/\/\s)[Ll]egal[- ][Pp]rivilege)(?!(?:\s\|\/\/\|\s\/\/\s)NATIONAL[ -]CABINET)(?!(?:\s\|\/\/\|\s\/\/\s)CABINET) |
| PROTECTED Personal Privacy Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Personal[ -]Privacy |
| PROTECTED Legal Privilege Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legal[ -]Privilege |
| PROTECTED Legislative Secrecy Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sACCESS=)Legislative[ -]Secrecy |
| PROTECTED NATIONAL CABINET Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)NATIONAL[ -]CABINET |
| PROTECTED CABINET Regex1,5 | PROTECTED(?:\s\|\/\/\|\s\/\/\s\|,\sCAVEAT=SH:)CABINET |
Quando si valutano gli esempi sit precedenti, prendere nota della logica di espressione seguente:
- 1 Queste espressioni corrispondono ai contrassegni applicati a entrambi i documenti (ad esempio OFFICIAL: SENSITIVE NATIONAL CABINET) e alla posta elettronica (ad esempio, '[SEC=OFFICIAL:Sensitive, CAVEAT=NATIONAL-CABINET]').
-
2 Il lookbehind negativo in OFFICIAL Regex (
(?<!UN)) impedisce che gli elementi NON UFFICIALI vengano abbinati come OFFICIAL. -
3OFFICIAL Sensitive Regex e PROTECTED Regex usano lookahead negativi (
(?!)) per garantire che non vengano applicati indicatori di gestione delle informazioni (IMM) o avvertenza dopo la classificazione di sicurezza. Ciò consente di evitare che gli elementi con IMM o avvertenze vengano identificati come versione non IMM o avvertenza della classificazione. -
4 L'uso di
[:\- ]in OFFICIAL: Sensitive è destinato a consentire flessibilità nel formato di questo contrassegno ed è importante a causa dell'uso di caratteri due punti nelle intestazioni x. -
5
(?:\s\|\/\/\|\s\/\/\s)viene usato per identificare lo spazio tra i componenti di contrassegno e consente uno spazio singolo, uno spazio doppio, una doppia barra in avanti o una doppia barra in avanti con spazi. Questo è progettato per consentire le diverse interpretazioni del formato di contrassegno PSPF che esiste tra le organizzazioni governative australiane.
Tipi di informazioni sensibili alle entità denominate
I SIT di entità denominate sono dizionario complesso e identificatori basati su pattern creati da Microsoft, che possono essere usati per rilevare informazioni come:
- nomi di Persone
- Indirizzi fisici
- Termini e condizioni mediche
I SIT di entità denominate possono essere usati in isolamento, ma possono anche essere utili come elementi di supporto. Ad esempio, un termine medico esistente all'interno di un messaggio di posta elettronica potrebbe non essere utile come indicazione che l'elemento contiene informazioni riservate. Tuttavia, un termine medico se associato a un valore che potrebbe indicare un numero di cliente o paziente e un nome di primo e di famiglia, fornirebbe un'indicazione forte che l'elemento è sensibile.
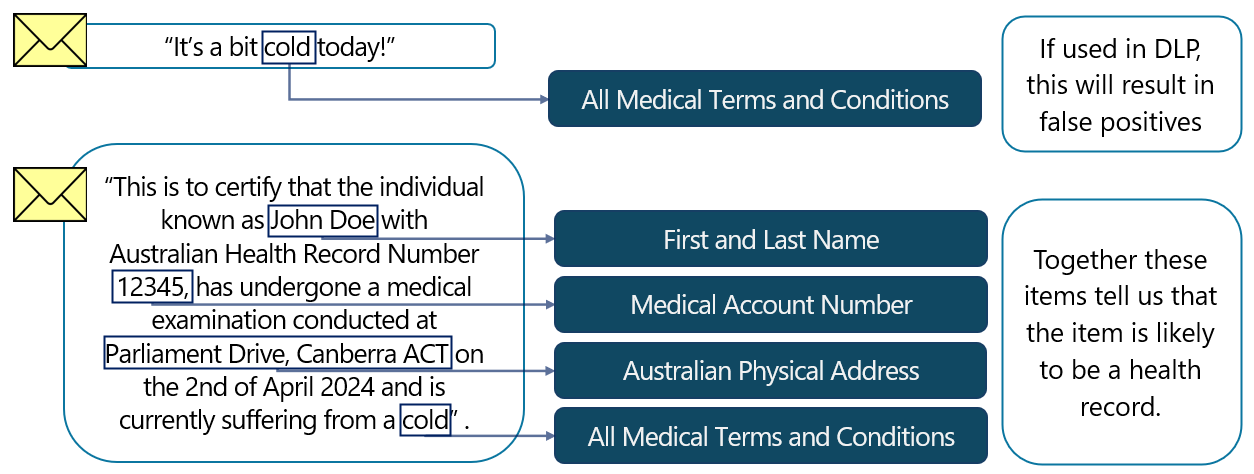
I SIT di entità denominate possono essere associati a SIT personalizzati, usati come elementi di supporto o anche inclusi con altri SIT nei criteri DLP.
Per altre informazioni sui SIT di entità denominate, vedere Informazioni sulle entità denominate.
I dati esatti corrispondono ai tipi di informazioni sensibili
I SIT exact data match (EDM) vengono generati in base ai dati effettivi. I valori numerici, ad esempio gli ID cliente numerici, sono difficili da trovare tramite SIT standard a causa di conflitti con altri valori numerici, ad esempio i numeri di telefono. Gli elementi di supporto migliorano la corrispondenza per ridurre i falsi positivi.
Exact Data Match aiuta le organizzazioni governative australiane che dispongono di sistemi che contengono dati relativi a dipendenti, clienti o cittadini per identificare accuratamente queste informazioni.
Per altre informazioni sull'implementazione di SIT EDM, vedere Informazioni sui tipi di informazioni sensibili basati sulla corrispondenza dei dati esatti.
Creazione impronta digitale documenti
L'impronta digitale del documento è una tecnica di identificazione delle informazioni che, anziché cercare i valori contenuti in un elemento, esamina invece il formato e la struttura dell'elemento. In sostanza, ciò consente di convertire un modulo standard in un tipo di informazioni riservate che può essere usato per identificare le informazioni.
Le organizzazioni governative possono usare il metodo di identificazione del contenuto tramite impronta digitale dei documenti per identificare gli elementi generati tramite un flusso di lavoro o moduli inviati da altre organizzazioni o membri del pubblico.
Per informazioni sull'implementazione dell'impronta digitale dei documenti, vedere Impronta digitale dei documenti.
Tipi di informazioni sensibili correlate alla rete o alla sicurezza
Esistono numerosi usi per i SIT oltre all'identificazione di informazioni riservate o classificate per la sicurezza. Uno di questi usi è il rilevamento delle credenziali. I SIT predefiniti vengono forniti per i tipi di credenziali seguenti:
- Credenziali di accesso utente
- Microsoft Entra ID token di accesso client
- Azure Batch chiavi di accesso condivise
- Firme di accesso condiviso dell'account di archiviazione di Azure
- Segreto client/chiavi API
Questi SIT predefiniti vengono usati in modo indipendente e vengono anche raggruppati in un sit denominato Tutte le credenziali. Tutte le credenziali sit è utile per i team informatici che lo usano in:
- Criteri DLP per identificare e impedire lo spostamento laterale da parte di utenti malintenzionati o utenti malintenzionati esterni.
- Criteri di etichettatura automatica, per applicare la crittografia agli elementi che non devono contenere credenziali, bloccare gli utenti dai file e consentire l'avvio delle azioni correttive.
- Criteri DLP per impedire agli utenti di condividere le proprie credenziali con altri utenti rispetto ai criteri dell'organizzazione.
- Per evidenziare gli elementi archiviati in posizioni di SharePoint o Exchange, che conservano in modo inappropriato le informazioni sulle credenziali.
I SIT predefiniti esistono anche per gli indirizzi di rete (sia IPv4 che IPv6) e sono utili per proteggere gli elementi contenenti informazioni di rete o impedire agli utenti di condividere indirizzi IP tramite posta elettronica, chat di Teams o messaggi di canale.
Classificatori sottoponibili a training
I classificatori sottoponibili a training sono modelli di Machine Learning di cui è possibile eseguire il training per riconoscere le informazioni sensibili. Come per i SIT, Microsoft fornisce classificatori con training preliminare. Un estratto di classificatori con training preliminare rilevanti per le organizzazioni governative australiane è elencato nella tabella seguente:
| Categoria classificatore | Classificatori sottoponibili a training di esempio |
|---|---|
| Finanza | Rendiconti bancari, budget, report di controllo finanziario, rendiconti finanziari, imposte, estratto conto, Stime di budget (BE), Business Activity Statement (BAS). |
| Business | Procedure operative, contratti di non divulgazione, approvvigionamento, parole di codice del progetto, Stime del Senato (SE), Domande su avviso (QoN). |
| Risorse umane | Curriculum, file di azione disciplinare dei dipendenti, contratto di lavoro, autorizzazioni dell'Australian Government Security Vetting Agency (AGSVA), Programma di prestito per l'istruzione superiore (HELP), ID militare, Autorizzazione per il lavoro straniero (FWA). |
| Medico | Assistenza sanitaria, moduli medici, MyHealth Record. |
| Esigenze legali | Affari legali, contratti, contratti di licenza. |
| Tecnico | File di sviluppo software, documenti di progetto, file di progettazione di rete. |
| Comportamentale | linguaggio offensivo, volgarità, minaccia, molestie mirate, discriminazione, complicità normativa, reclamo del cliente. |
Alcuni esempi di come le organizzazioni governative potrebbero usare questi classificatori predefiniti includono:
- Le regole di business potrebbero indicare che alcuni elementi nella categoria risorse umane, ad esempio i curriculum, devono essere contrassegnati come "OFFICIAL: Sensitive Personal Privacy" perché contengono informazioni personali sensibili. Per questi elementi, è possibile configurare una raccomandazione per le etichette tramite l'etichettatura automatica basata su client.
- I file di progettazione di rete, in particolare per le reti sicure, devono essere trattati con attenzione per evitare compromissioni. Questi potrebbero essere degni di un'etichetta PROTECTED o almeno di criteri di prevenzione della perdita dei dati che impediscono la divulgazione non autorizzata a utenti non autorizzati.
- I classificatori comportamentali sono interessanti e, anche se potrebbero non avere una correlazione diretta con i contrassegni protettivi o i requisiti di prevenzione della perdita dei dati, possono comunque avere un valore aziendale elevato. Ad esempio, i team hr potrebbero ricevere notifiche di casi di molestie e/o avere la possibilità di visualizzare la corrispondenza contrassegnata tramite Conformità delle comunicazioni.
Le organizzazioni possono anche eseguire il training dei propri classificatori. È possibile eseguire il training dei classificatori fornendo loro set di campioni positivi e negativi. Il classificatore elabora gli esempi e compila un modello di stima. Al termine del training, i classificatori possono essere usati per l'applicazione di etichette di riservatezza, criteri di conformità delle comunicazioni e criteri di etichettatura di conservazione. L'uso dei classificatori nei criteri DLP è disponibile in anteprima.
Per altre informazioni sui classificatori sottoponibili a training, vedere Informazioni sui classificatori sottoponibili a training.
Uso di informazioni sensibili identificate
Una volta identificate le informazioni tramite SIT o classificatore (tramite gli aspetti noti dei dati di Microsoft Purview), è possibile usare queste informazioni per aiutarci a completare gli altri tre pilastri della gestione delle informazioni di Microsoft 365, vale a dire:
- Proteggere i dati,
- Evitare la perdita di dati e
- Gestire i dati.
La tabella seguente offre vantaggi ed esempi di come la conoscenza di un elemento contenente informazioni sensibili possa facilitare la gestione delle informazioni nella piattaforma Microsoft 365:
| Funzionalità | Esempio di utilizzo |
|---|---|
| Prevenzione della perdita di dati | Assiste la gestione riducendo i rischi di perdita di dati. |
| Etichettatura di riservatezza | Consiglia di applicare un'etichetta di riservatezza appropriata. Una volta etichettate, le protezioni correlate alle etichette si applicano alle informazioni. |
| Etichettatura di conservazione | Applica automaticamente un'etichetta di conservazione, consentendo di soddisfare i requisiti di gestione dell'archivio o dei record. |
| Esplora contenuto | Visualizzare la posizione in cui si trovano gli elementi contenenti informazioni riservate nei servizi di Microsoft 365, tra cui SharePoint, Teams, OneDrive ed Exchange. |
| Gestione dei rischi Insider | Monitorare l'attività degli utenti in base alle informazioni sensibili, stabilire un livello di rischio utente in base al comportamento ed inoltrare comportamenti sospetti ai team pertinenti. |
| Conformità delle comunicazioni | Verifica la corrispondenza ad alto rischio, incluse le chat o i messaggi di posta elettronica contenenti contenuti sensibili o sospetti. La conformità delle comunicazioni può contribuire a garantire che gli obblighi di probità siano soddisfatti dal governo australiano. |
| Microsoft Priva | Rilevare l'archiviazione di informazioni sensibili, inclusi i dati personali in posizioni come OneDrive, e guidare gli utenti sull'archiviazione corretta delle informazioni. |
| eDiscovery | Le informazioni sensibili di Surface nell'ambito dei processi HR o FOI e si applicano alle informazioni che potrebbero far parte di una richiesta o di un'indagine attiva. |
Esplora contenuto
Esplora contenuto di Microsoft 365 consente ai responsabili della conformità, della sicurezza e della privacy di ottenere informazioni rapide ma complete sulla posizione delle informazioni sensibili all'interno di un ambiente Microsoft 365. Questo strumento consente agli utenti autorizzati di esplorare posizioni ed elementi in base al tipo di informazioni. Il servizio indicizza e visualizza gli elementi che risiedono in Exchange, OneDrive e SharePoint. Sono visibili anche gli elementi che si trovano all'interno dei siti del team di SharePoint sottostanti di Teams.
Tramite questo strumento è possibile selezionare un tipo di informazioni sensibili o un'etichetta di riservatezza, visualizzare il numero di elementi che si allineano con esso in ognuno dei servizi di Microsoft 365:
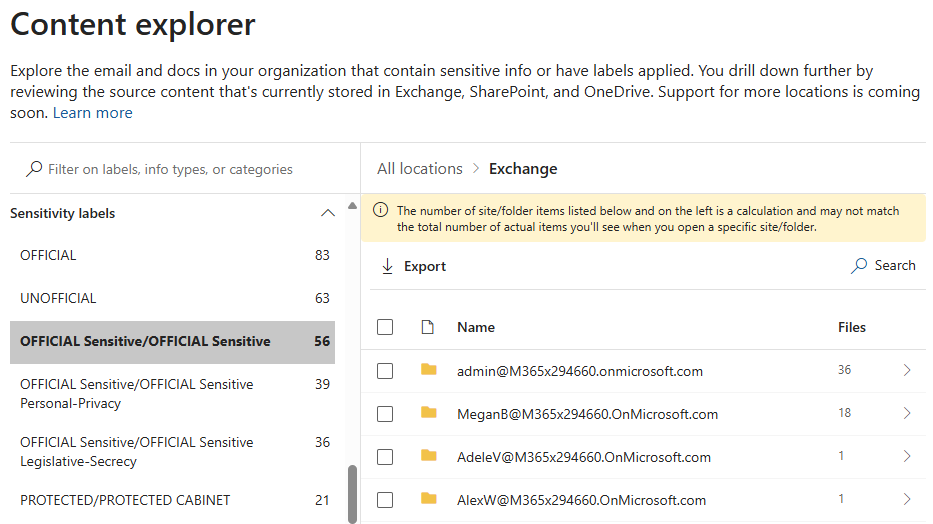
Esplora contenuto può fornire informazioni preziose sulle posizioni in cui gli elementi riservati o classificati per la sicurezza risiedono in un ambiente. È improbabile che una visione consolidata della posizione delle informazioni sia possibile tramite sistemi locali.
Per le organizzazioni che includono etichette non consentite nell'account dell'organizzazione (ad esempio SECRET o TOP SECRET) insieme ai criteri di etichettatura automatica associati per applicare le etichette, Esplora contenuto può trovare informazioni che non devono essere archiviate nella piattaforma. Poiché Esplora contenuto può anche visualizzare i SIT, è possibile ottenere un approccio simile tramite SIT per identificare i contrassegni protettivi.
Per altre informazioni su Esplora contenuto, vedere Introduzione a Esplora contenuto.