Étapes de description et de traitement des pipelines de données RAG
Dans cet article, vous allez découvrir comment préparer des données non structurées à utiliser dans les applications RAG. Les données non structurées font référence à des données sans structure ou organisation spécifique, telles que des documents PDF qui peuvent inclure du texte et des images, ou du contenu multimédia tel que l’audio ou les vidéos.
Les données non structurées ne disposent pas d’un modèle de données ou d’un schéma prédéfini, ce qui rend impossible l’interrogation sur la base de la structure et des métadonnées uniquement. Par conséquent, les données non structurées nécessitent des techniques capables de comprendre et d’extraire la signification sémantique du texte brut, des images, de l’audio ou d’autres contenus.
Pendant la préparation des données, le pipeline de données d’application RAG prend des données brutes non structurées et les transforme en blocs discrets qui peuvent être interrogés en fonction de leur pertinence pour la requête d’un utilisateur. Les étapes clés du prétraitement des données sont décrites ci-dessous. Chaque étape comporte une variété de boutons qui peuvent être paramétrés. Pour une discussion plus approfondie sur ces boutons, consultez Améliorer la qualité de l’application RAG.
Préparer des données non structurées pour la récupération
Dans le reste de cette section, nous décrivons le processus de préparation des données non structurées pour la récupération à l’aide de la recherche sémantique. La recherche sémantique comprend la signification contextuelle et l’intention d’une requête utilisateur pour fournir des résultats de recherche plus pertinents.
La recherche sémantique est l’une des différentes approches qui peuvent être prises lors de l’implémentation du composant de récupération d’une application RAG sur des données non structurées. Ces documents couvrent d’autres stratégies de récupération dans la section boutons de récupération.
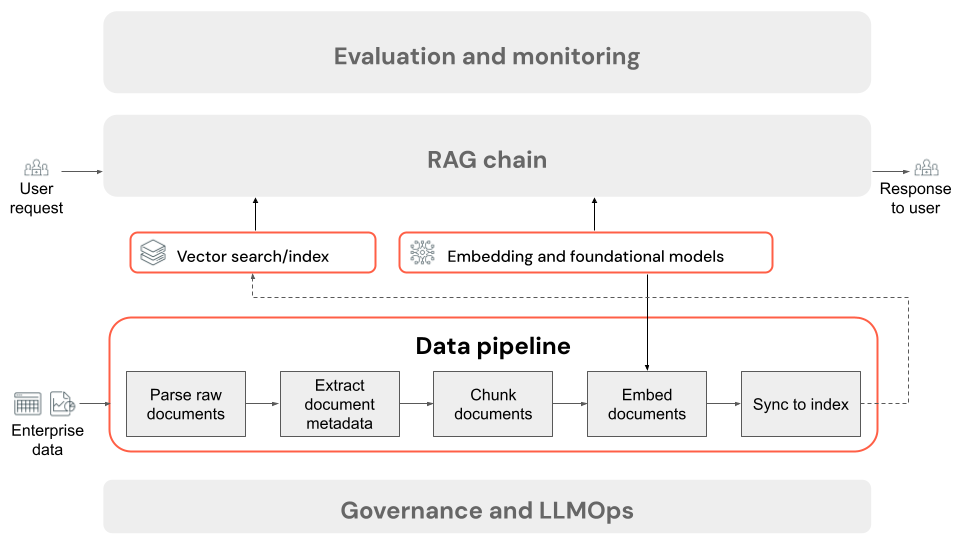
Étapes d’un pipeline de données d’application RAG
Voici les étapes classiques d’un pipeline de données dans une application RAG à l’aide de données non structurées :
- Analyser les documents bruts : l’étape initiale consiste à transformer des données brutes en un format utilisable. Il peut s'agir d'extraire du texte, des tableaux et des images à partir d'une collection de PDF ou d'utiliser des techniques de reconnaissance optique de caractères (OCR) pour extraire du texte à partir d'images.
- Extraire des métadonnées de document (facultatif) : dans certains cas, l’extraction et l’utilisation de métadonnées de document, telles que les titres de document, les numéros de page, les URL ou d’autres informations, peuvent aider l’étape de récupération à interroger plus précisément les données appropriées.
- Documents de segment : pour vous assurer que les documents analysés peuvent s’adapter au modèle d’incorporation et à la fenêtre de contexte de LLM, nous interrompons les documents analysés en blocs plus petits et discrets. L'extraction de ces morceaux ciblés, plutôt que de documents entiers, donne au LLM un contexte plus ciblé à partir duquel il peut générer ses réponses.
- Segments incorporés : dans une application RAG qui utilise la recherche sémantique, un type spécial de modèle de langage appelé modèle d’incorporation transforme chacun des blocs de l’étape précédente en vecteurs numériques, ou des listes de nombres, qui encapsulent la signification de chaque élément de contenu. Ces vecteurs représentent le sens sémantique du texte, et pas seulement des mots-clés de surface. Cela permet de rechercher en fonction de la signification plutôt que des correspondances de texte littéral.
- Segments d’index dans une base de données vectorielle : l’étape finale consiste à charger les représentations vectorielles des blocs, ainsi que le texte du bloc, dans une base de données vectorielle. Une base de données vectorielle est un type spécialisé de base de données conçu pour stocker et rechercher efficacement des données vectorielles comme des incorporations. Pour maintenir les performances avec un grand nombre de blocs, les bases de données vectorielles incluent généralement un index vectoriel qui utilise différents algorithmes pour organiser et mapper les incorporations vectorielles d’une manière qui optimise l’efficacité de la recherche. Au moment de la requête, la requête d’un utilisateur est incorporée dans un vecteur, et la base de données tire parti de l’index vectoriel pour rechercher les vecteurs de blocs les plus similaires, en retournant les blocs de texte d’origine correspondants.
Le processus de similarité informatique peut être coûteux en calcul. Les index vectoriels, tels que Databricks Vector Search, accélèrent ce processus en fournissant un mécanisme permettant d’organiser et de naviguer efficacement les incorporations, souvent par le biais de méthodes d’approximation sophistiquées. Cela permet de classer rapidement les résultats les plus pertinents sans avoir à comparer individuellement chaque intégration à la requête de l'utilisateur.
Chaque étape du pipeline de données implique des décisions techniques qui ont un impact sur la qualité de l'application RAG. Par exemple, le choix de la bonne taille de bloc à l’étape 3 garantit que le LLM reçoit des informations spécifiques mais contextualisées, tandis que la sélection d’un modèle d’incorporation approprié à l’étape 4 détermine l’exactitude des blocs retournés lors de la recherche.
Ce processus de préparation des données est appelé préparation des données hors connexion, car il se produit avant que le système réponde aux requêtes, contrairement aux étapes en ligne déclenchées lorsqu’un utilisateur envoie une requête.