Descrizione ed elaborazione della pipeline di dati RAG
In questo articolo si apprenderà come preparare i dati non strutturati da usare nelle applicazioni RAG. I dati non strutturati fanno riferimento a dati senza una struttura o un'organizzazione specifica, ad esempio documenti PDF che possono includere testo e immagini o contenuti multimediali, ad esempio audio o video.
I dati non strutturati non dispongono di un modello di dati o di uno schema predefinito, rendendo impossibile eseguire query sulla base della sola struttura e dei metadati. Di conseguenza, i dati non strutturati richiedono tecniche che possano comprendere ed estrarre significato semantico da testo non elaborato, immagini, audio o altro contenuto.
Durante la preparazione dei dati, la pipeline di dati dell'applicazione RAG accetta dati non strutturati non elaborati e la trasforma in blocchi discreti su cui è possibile eseguire query in base alla pertinenza della query di un utente. Di seguito sono descritti i passaggi principali della pre-elaborazione dei dati. Ogni passaggio ha una varietà di manopole che possono essere ottimizzate: per una discussione più approfondita su queste manopole, vedere Migliorare la qualità dell'applicazione RAG.
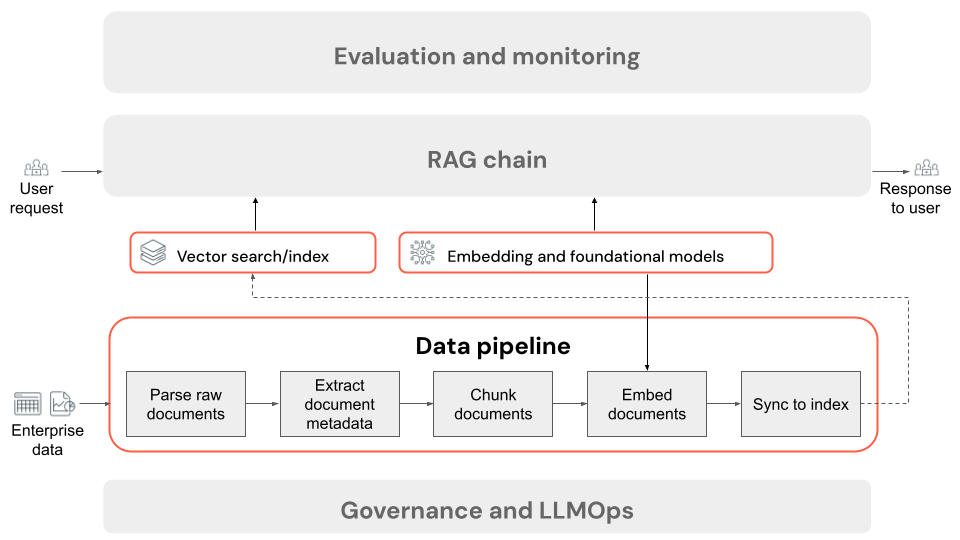
Preparare i dati non strutturati per il recupero
Nella parte restante di questa sezione viene descritto il processo di preparazione dei dati non strutturati per il recupero tramite la ricerca semantica. La ricerca semantica comprende il significato contestuale e la finalità di una query utente per fornire risultati di ricerca più pertinenti.
La ricerca semantica è uno dei diversi approcci che è possibile adottare quando si implementa il componente di recupero di un'applicazione RAG su dati non strutturati. Questi documenti illustrano strategie di recupero alternative nella sezione knobs di recupero.
Passaggi di una pipeline di dati dell'applicazione RAG
Di seguito sono riportati i passaggi tipici di una pipeline di dati in un'applicazione RAG usando dati non strutturati:
- Analizzare i documenti non elaborati: il passaggio iniziale prevede la trasformazione dei dati non elaborati in un formato utilizzabile. Ciò può includere l'estrazione di testo, tabelle e immagini da una raccolta di PDF o l'uso di tecniche di riconoscimento ottico dei caratteri (OCR) per estrarre testo dalle immagini.
- Estrarre i metadati del documento (facoltativo): in alcuni casi, l'estrazione e l'uso dei metadati dei documenti, ad esempio i titoli dei documenti, i numeri di pagina, gli URL o altre informazioni possono aiutare il recupero più precisamente a eseguire query sui dati corretti.
- Blocchi di documenti: per garantire che i documenti analizzati possano essere inseriti nel modello di incorporamento e nella finestra di contesto LLM, i documenti analizzati vengono suddivisi in blocchi più piccoli e discreti. Il recupero di questi blocchi incentrati, anziché interi documenti, fornisce il contesto LLM più mirato da cui generare le risposte.
- Incorporamento di blocchi: in un'applicazione RAG che usa la ricerca semantica, un tipo speciale di modello linguistico denominato modello di incorporamento trasforma ogni blocco del passaggio precedente in vettori numerici o elenchi di numeri, che incapsulano il significato di ogni parte di contenuto. In particolare, questi vettori rappresentano il significato semantico del testo, non solo parole chiave a livello di superficie. Ciò consente la ricerca in base al significato anziché alle corrispondenze di testo letterale.
- Blocchi di indice in un database vettoriale: il passaggio finale consiste nel caricare le rappresentazioni vettoriali dei blocchi, insieme al testo del blocco, in un database vettoriale. Un database vettoriale è un tipo specializzato di database progettato per archiviare e cercare in modo efficiente dati vettoriali come incorporamenti. Per mantenere le prestazioni con un numero elevato di blocchi, i database vettoriali in genere includono un indice vettoriale che usa vari algoritmi per organizzare ed eseguire il mapping degli incorporamenti vettoriali in modo da ottimizzare l'efficienza della ricerca. In fase di query, la richiesta di un utente viene incorporata in un vettore e il database sfrutta l'indice vettoriale per trovare i vettori di blocchi più simili, restituendo i blocchi di testo originali corrispondenti.
Il processo di somiglianza del calcolo può essere dispendioso a livello di calcolo. Gli indici vettoriali, ad esempio Databricks Vector Search, velocizzano questo processo fornendo un meccanismo per organizzare ed esplorare in modo efficiente gli incorporamenti, spesso tramite metodi di approssimazione sofisticati. In questo modo è possibile classificare rapidamente i risultati più rilevanti senza confrontare singolarmente ogni incorporamento con la query dell'utente.
Ogni passaggio della pipeline di dati implica decisioni di progettazione che influiscono sulla qualità dell'applicazione RAG. Ad esempio, se si sceglie la dimensione del blocco corretta nel passaggio 3, l'LLM riceve informazioni specifiche ma contestualizzate, mentre la selezione di un modello di incorporamento appropriato nel passaggio 4 determina l'accuratezza dei blocchi restituiti durante il recupero.
Questo processo di preparazione dei dati viene definito preparazione dei dati offline, come avviene prima che il sistema risponda alle query, a differenza dei passaggi online attivati quando un utente invia una query.