Objet de barrière native GPU
Cet article décrit l'objet de synchronisation de barrière GPU qui peut être utilisé pour une véritable synchronisation GPU-à-GPU dans l'étape 2 de planification matérielle du GPU. Cette fonctionnalité est prise en charge à partir de Windows 11, version 24H2 (WDDM 3.2). Les développeurs de pilotes graphiques doivent être familiarisés avec WDDM 2.0 et l'étape 1 de planification matérielle du GPU.
Comparaison entre les objets de synchronisation de barrière existants et les nouveaux
Objet de synchronisation de barrière surveillée existant
L'objet de synchronisation de barrière supervisée WDDM 2.x prend en charge les opérations suivantes :
- Attente du processeur sur une valeur de barrière surveillée, soit :
- par interrogation, en utilisant une adresse virtuelle (VA) de processeur ;
- par mise en file d'attente bloquante dans Dxgkrnl, signalée lorsque le processeur observe la nouvelle valeur de barrière surveillée.
- Signal du processeur d'une valeur surveillée.
- Signal du GPU d'une valeur surveillée en écrivant à la VA du GPU de la barrière surveillée et en envoyant une interruption signalée par la barrière surveillée pour avertir le processeur de la mise à jour de la valeur.
En revanche, l'attente native sur le GPU pour une valeur de barrière surveillée n'est pas prise en charge. Au lieu de cela, le système d'exploitation retient le travail du GPU qui dépend de la valeur attendue sur le processeur. Il ne fait que libérer ce travail sur le GPU une fois que la valeur est signalée.
Objet de synchronisation de barrière native du GPU
Cet article présente une extension de l'objet de barrière surveillée qui prend en charge les fonctionnalités ajoutées suivantes :
- Attente par le GPU d'une valeur de barrière surveillée, ce qui permet une synchronisation haute performance d'un moteur à l'autre sans besoin d'aller-retour avec le processeur.
- Notification d'interruption conditionnelle uniquement pour les signaux de barrière GPU ayant des objets waiter de processeur. Cette fonctionnalité assure d'importantes économies d'énergie en permettant au processeur d'entrer dans un état de faible consommation lorsque tout le travail du GPU est mis en file d'attente.
- Stockage de la valeur de barrière dans la mémoire locale du GPU (et non pas dans la mémoire système).
Conception de l'objet de synchronisation de barrière native du GPU
Le diagramme suivant illustre l'architecture de base d'un objet de barrière native du GPU, en mettant l'accent sur l'état de l'objet de synchronisation partagé entre le processeur et le GPU.
: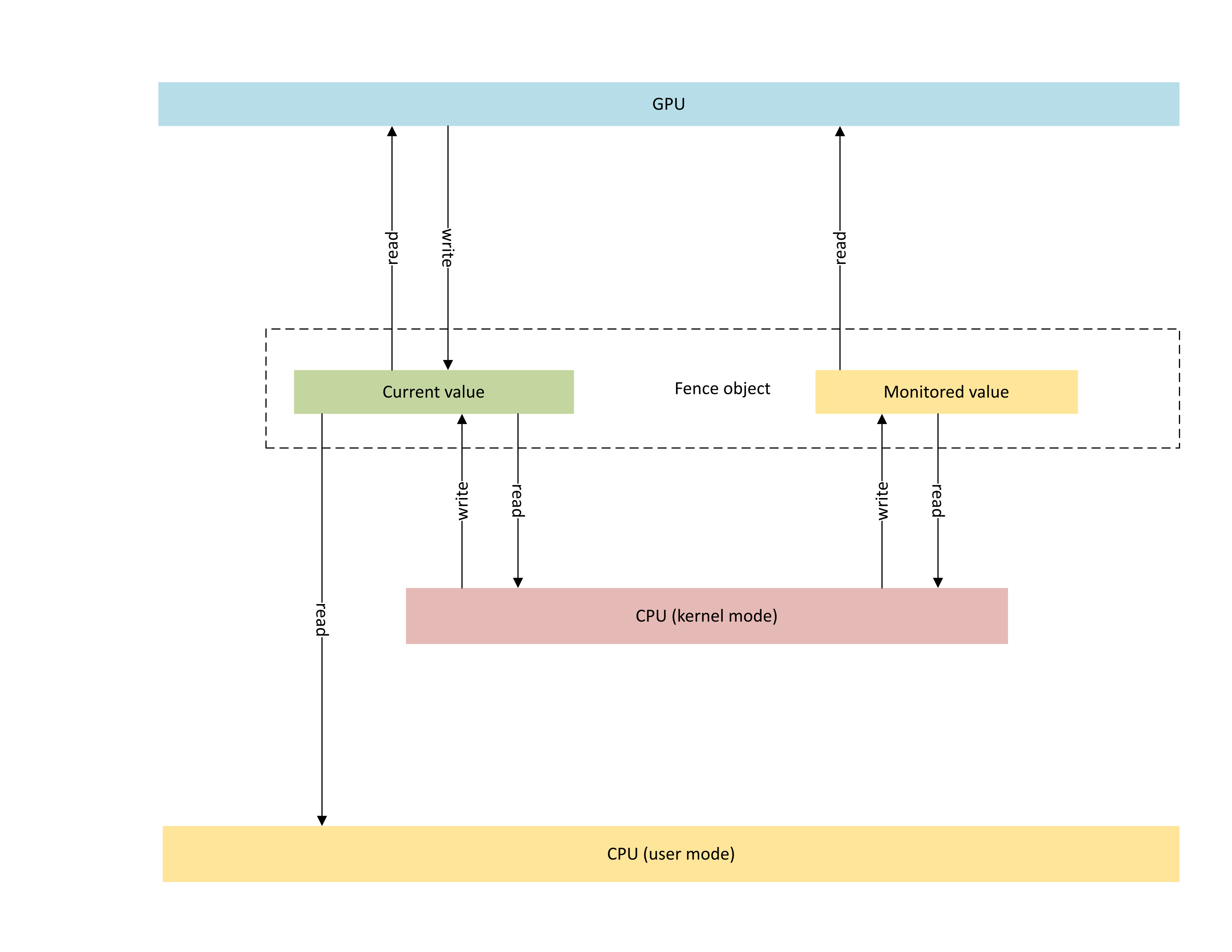
Le diagramme contient deux composantes principales :
La valeur actuelle (dans cet article, CurrentValue). Cet emplacement de mémoire contient la valeur de barrière 64 bits actuellement signalée. CurrentValue est mappée et accessible à la fois au processeur (en écriture à partir du mode noyau, et en lecture aussi bien à partir du mode utilisateur que du mode noyau) et au GPU (en lecture et en écriture à travers l'adresse virtuelle du GPU). CurrentValue nécessite que les écritures 64 bits soient atomiques aussi bien du point de vue du processeur que du GPU. Autrement dit, les mises à jour des 32 bits de poids fort et faible ne peuvent pas être déchirées et doivent être visibles en même temps. Ce concept est déjà présent dans l'objet de barrière surveillée existant.
La valeur surveillée (dans cet article, MonitoringValue). Cet emplacement de mémoire contient la valeur la moins attendue par le processeur, minorée de 1. MonitoredValue est mappée et accessible à la fois au processeur (en lecture et en écriture à partir du mode noyau, aucun accès en mode utilisateur) et au GPU (en lecture à travers la VA du GPU, aucun accès en écriture). Le système d'exploitation tient à jour la liste des waiters de processeur en suspens pour un objet de barrière donné et modifie MonitoredValue à mesure que des waiters sont ajoutés et supprimés. Lorsqu'il n'y a pas de waiter en suspens, la valeur est définie sur UINT64_MAX. Ce concept est nouveau dans l'objet de synchronisation de barrière native du GPU.
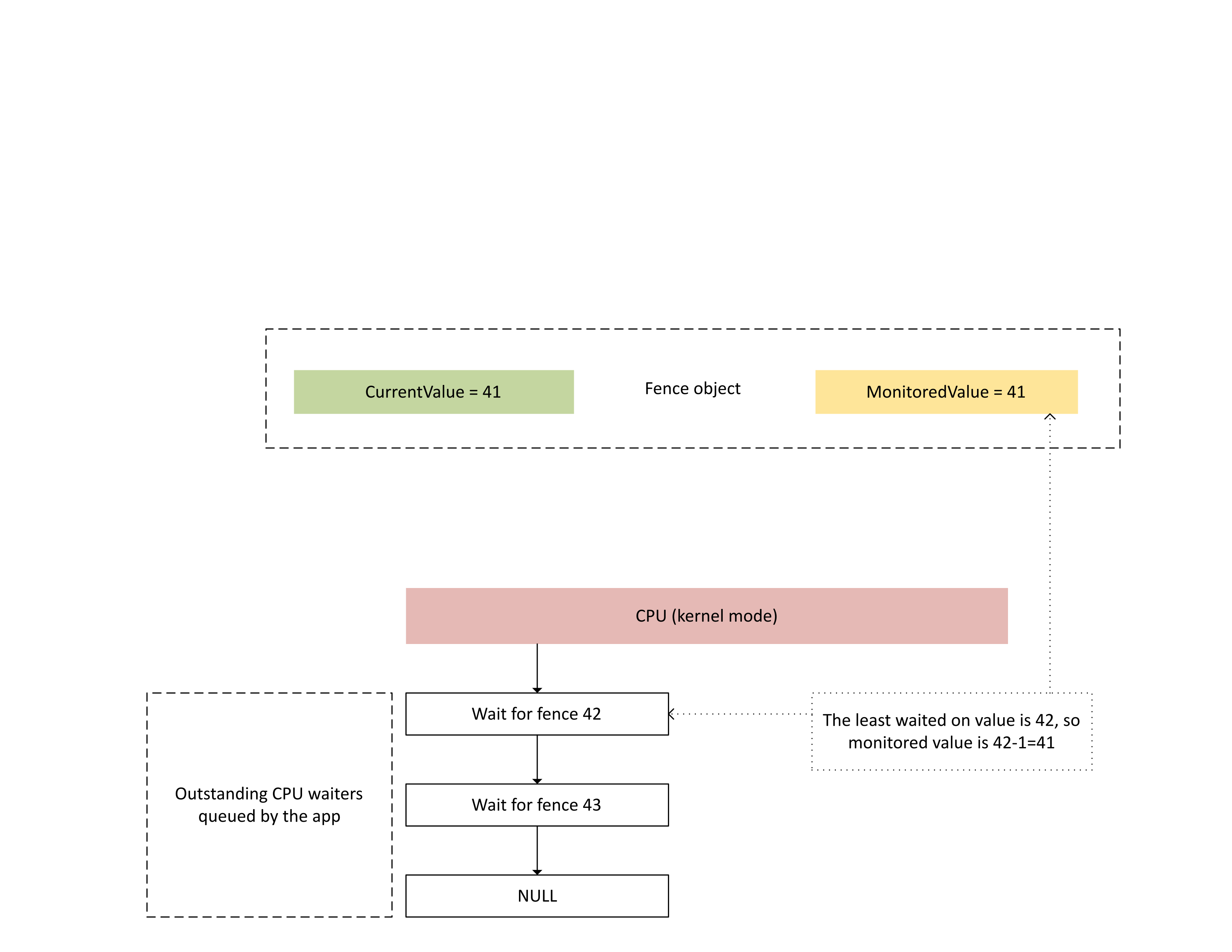
Le diagramme suivant illustre la façon dont Dxgkrnl assure le suivi des waiters de processeur en suspens pour une valeur de barrière surveillée spécifique. Il montre également la valeur de barrière surveillée définie à un instant donné. CurrentValue et MonitoredValue sont toutes deux sur 41, ce qui signifie :
- Que le GPU a effectué toutes les tâches jusqu'à la valeur de barrière de 41.
- Que le processeur n'attend aucune valeur de barrière inférieure ou égale à 41.
:
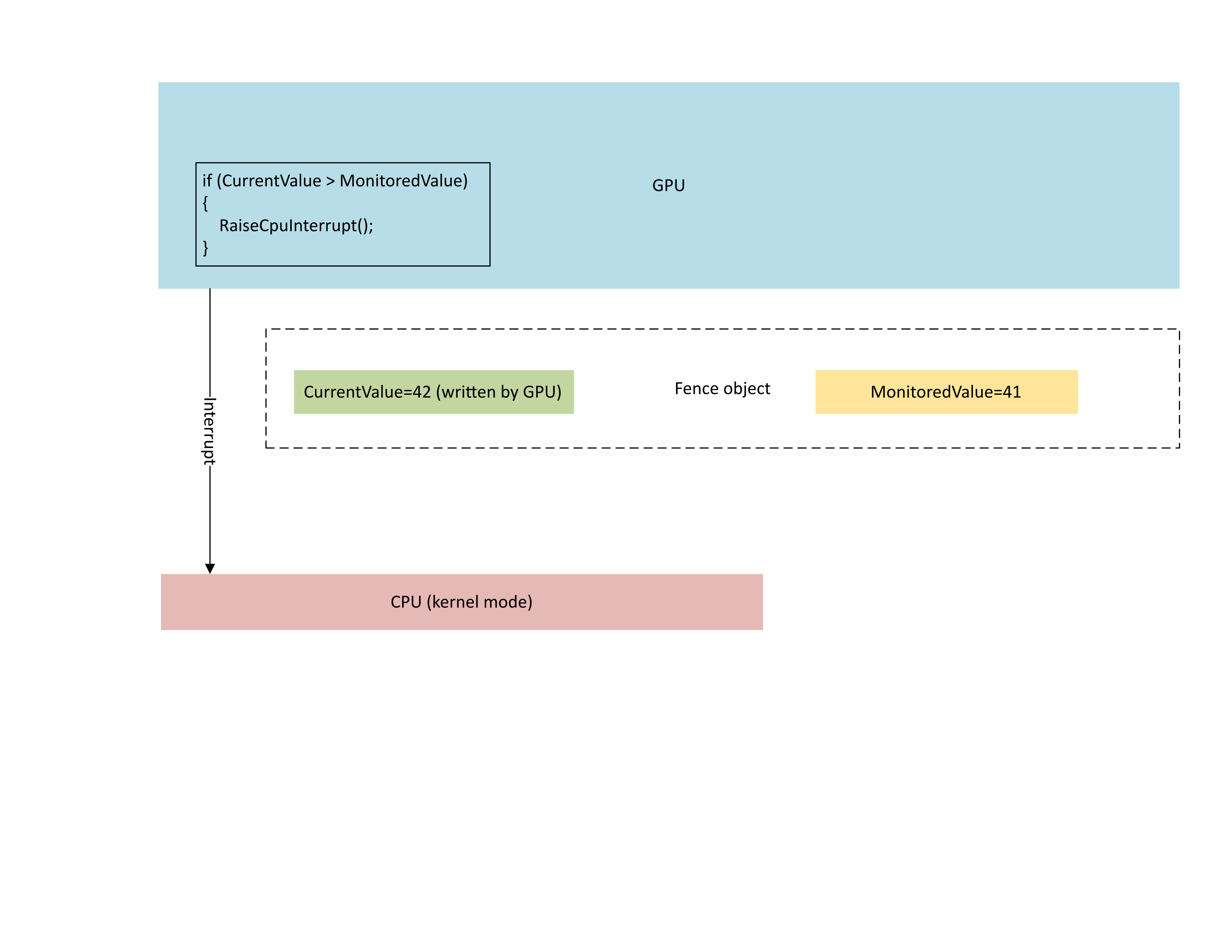
Le diagramme suivant illustre comment le processeur de gestion de contexte (CMP) du GPU déclenche une interruption conditionnelle du processeur uniquement si la nouvelle valeur de barrière est supérieure à la valeur surveillée. Une telle interruption signifie qu'il existe des waiters de processeur en suspens susceptibles d'être satisfaits de la valeur nouvellement écrite.
:
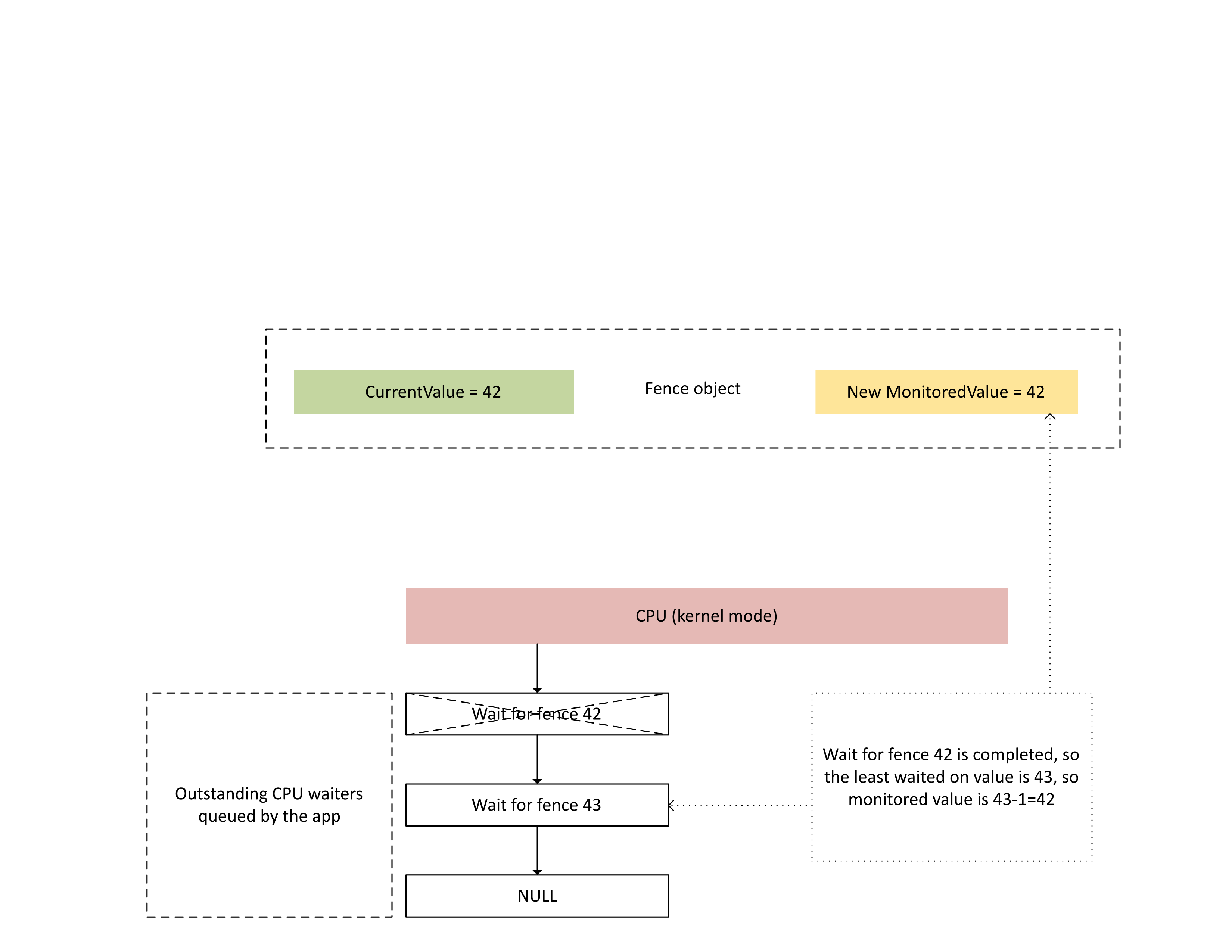
Comme le montre le diagramme suivant, lorsque le processeur traite cette interruption, Dxgkrnl :
- débloque les waiters de processeur satisfaits de la barrière nouvellement écrite ;
- fait avancer la valeur surveillée pour qu'elle corresponde à la valeur la moins attendue en suspens, minorée de 1.
:
Stockage de mémoire physique pour les valeurs de barrière actuelle et surveillée
Pour un objet de barrière donné, CurrentValue et MonitoredValue sont stockées à des emplacements distincts.
Les objets de barrière qui ne sont pas partageables disposent d'un stockage de valeur de barrière pour différents objets de barrière regroupés au sein du même processus, dans la même page de mémoire. Les valeurs sont regroupées en fonction des valeurs de stride spécifiées dans les capacités de barrière native du KMD décrites plus loin dans cet article.
Les objets de barrière qui sont partageables ont leurs valeurs actuelle et surveillée dans des pages de mémoire qui ne sont partagées avec aucun autre objet de barrière.
Valeur actuelle
La valeur actuelle peut résider dans la mémoire système ou dans la mémoire locale du GPU.
Pour les barrières de mémoire système, le système d'exploitation alloue le stockage de la valeur actuelle à partir du pool de mémoire système interne.
Pour les barrières de mémoire locale, le système d'exploitation alloue le stockage de la valeur actuelle à partir d'un ensemble de segments de mémoire locale spécifié dans DXGK_NATIVE_FENCE_CAPS, tel que décrit dans Capacités de barrière native.
Valeur surveillée
La valeur surveillée peut également résider aussi bien dans la mémoire système que dans la mémoire locale du GPU.
Pour les barrières de mémoire système, le système d'exploitation alloue le stockage de la valeur surveillée à partir du pool de mémoire système interne.
Pour les barrières de mémoire locale, le système d'exploitation alloue le stockage de la valeur surveillée à partir d'un ensemble de segments de mémoire locale spécifié dans DXGK_NATIVE_FENCE_CAPS, tel que décrit dans Capacités de barrière native.
Lorsque les conditions d'attente du processeur du système d'exploitation changent, le rappel DxgkDdiUpdateMonitoredValues du KMD est appelé pour mettre à jour la valeur surveillée en lui donnant une valeur spécifiée.
Problèmes de synchronisation
Le mécanisme précédent est associé à une condition inhérente de concurrence entre les lectures et écritures de la valeur actuelle et de la valeur surveillée par le processeur et le GPU. Faute d'une attention particulière, les problèmes suivants peuvent se produire :
- Le GPU peut lire une MonitoredValue obsolète et ne pas déclencher l'interruption attendue par le processeur.
- Un moteur GPU peut écrire une valeur CurrentValue plus récente alors que le CMP est en train de prendre une décision sur la condition d'interruption. Cette CurrentValue plus récente risque de ne pas déclencher l'interruption attendue, ou de ne pas être vue par le processeur au moment de l'extraction de la valeur actuelle.
Synchronisation au sein du GPU entre le moteur et le CMP
Pour plus d'efficacité, de nombreux GPU implémentent la sémantique du signal de barrière surveillée en utilisant l'état parallèle qui réside dans la mémoire locale du GPU entre les zones suivantes :
Le moteur GPU, qui exécute le flux de la mémoire tampon de commande et déclenche de manière conditionnelle un signal matériel vers le CMP.
Le CMP du GPU, qui détermine si une interruption du processeur doit être déclenchée.
Dans ce cas, le CMP doit synchroniser l'accès à la mémoire avec le moteur GPU qui écrit la valeur de barrière dans la mémoire. En particulier, l'opération de mise à jour d'une MonitoredValue parallèle doit être ordonnée du point de vue du CMP en procédant de la manière suivante :
- Écriture d'une nouvelle MonitoredValue (stockage GPU parallèle)
- Exécution d'une barrière de mémoire pour synchroniser l'accès à la mémoire avec le moteur GPU
- Lecture de CurrentValue :
- Si CurrentValue>MonitoredValue, déclenchement d'une interruption processeur.
- Si CurrentValue<= MonitoredValue, pas de déclenchement d'interruption processeur.
Pour que cette condition de concurrence se résolve sans incident, il est impératif que la barrière de mémoire de l'étape 2 fonctionne correctement. Il ne doit pas y avoir d'opération d'écriture en mémoire en suspens dans CurrentValue à l'étape 3 provoquée par une commande n'ayant pas vu la mise à jour de MonitoredValue à l'étape 1. Cette situation génère donc une interruption si la barrière écrite à l'étape 3 est supérieure à la valeur mise à jour à l'étape 1.
Synchronisation entre le GPU et le processeur
Le processeur doit effectuer les mises à jour de Monitored Value et les lectures de CurrentValue de façon à ne pas perdre les notifications d'interruption des signaux en cours.
- Le système d'exploitation doit modifier MonitoredValue lorsqu'un nouveau waiter de processeur est ajouté au système, ou lorsqu'un waiter de processeur existant est mis hors service.
- Le système d'exploitation appelle DxgkDdiUpdateMonitoredValues pour notifier une nouvelle valeur surveillée au GPU.
- DxgkDdiUpdateMonitoredValue s'exécute au niveau d'interruption de l'appareil, et est donc synchronisé avec la routine de de service d'interruption (ISR) signalée par la barrière surveillée.
- DxgkDdiUpdateMonitoredValue doit garantir qu'après son retour, la CurrentValue lue par n'importe quel cœur de processeur a été écrite par le CMP du GPU après avoir observé la nouvelle MonitoredValue.
- Au retour de DxgkDdiUpdateMonitoredValue, le système d'exploitation rééchantillonne CurrentValue et satisfait tous les waiters qui sont débloqués par la nouvelle CurrentValue.
Il est parfaitement acceptable que le processeur observe une valeur CurrentValue plus récente que celle utilisée par le GPU pour décider de déclencher l'interruption. Cette situation pourrait parfois entraîner une notification d'interruption qui ne débloque aucun waiter. Ce qui n'est pas acceptable, c'est que le processeur ne reçoive pas de notification d'interruption pour la mise à jour la plus récente de la valeur CurrentValue qui est surveillée (c'est-à-dire, CurrentValue>MonitoredValue.)
Interrogation d'activation de la fonctionnalité de barrière native dans le système d'exploitation
Les interfaces suivantes sont introduites pour qu'un KMD puisse interroger si le système d'exploitation a activé la fonctionnalité de barrière native :
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
À l'instar des fonctionnalités étape 1 de planification matérielle et file d'attente matérielle des basculements, au moment de leur initialisation, les pilotes doivent interroger si la fonctionnalité de barrière native est activée dans le système d'exploitation. Toutefois, à partir de WDDM 3.2, le système d'exploitation utilise la fonctionnalité d'activation et de prise en charge des fonctionnalités WDDM ajoutée pour contrôler si la fonctionnalité est activée. Par conséquent, les pilotes doivent implémenter cette interface.
Avant que le KMD annonce la prise en charge de barrière native dans DXGK_VIDSCHCAPS, il est censé implémenter l'interface DXGKDDI_FEATURE_INTERFACE et interroger le système d'exploitation pour déterminer s'il a activé la fonctionnalité DXGK_FEATURE_NATIVE_FENCE. Le système d'exploitation fait échouer l'initialisation de l'adaptateur si le KMD annonce la prise en charge de barrière native alors que le système d'exploitation n'a pas activé la fonctionnalité.
Le système d'exploitation implémente la table d'interface DXGKCB_FEATURE_NATIVEFENCE_CAPS_1 ajoutée dédiée à la version 1 de DXGK_FEATURE_NATIVE_FENCE. Le KMD doit interroger cette table d'interface de fonctionnalité pour déterminer les capacités du système d'exploitation. Dans les futures versions du système d'exploitation, celui-ci peut introduire de futures versions de cette table d'interface indiquant la prise en charge de nouvelles capacités.
Exemple de code de pilote pour l'interrogation de prise en charge
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
Capacités de barrière native
Les interfaces suivantes sont mises à jour ou introduites pour interroger les capacités de barrière native :
Le champ NativeGpuFence est ajouté à DXGK_VIDSCHCAPS. Si le système d'exploitation a activé la fonctionnalité DXGK_FEATURE_NATIVE_FENCE, le pilote peut déclarer la prise en charge de la fonctionnalité de barrière native GPU lors de l'initialisation de l'adaptateur en donnant la valeur 1 au bit DXGK_VIDSCHCAPS ::NativeGpuFence.
DXGKQAITYPE_NATIVE_FENCE_CAPS est ajouté à DXGK_QUERYADAPTERINFOTYPE.
Dxgkrnl expose cette fonctionnalité au mode utilisateur via l'ajout de la structure/du bit D3DKMT_WDDM_3_1_CAPS ::NativeGpuFenceSupported correspondant.
KMTQAITYPE_WDDM_3_1_CAPS est ajouté à KMTQUERYADAPTERINFOTYPE.
Les entités suivantes sont ajoutées pour qu'un KMD puisse indiquer ses capacités de prise en charge pour la fonctionnalité de barrière native GPU.
La structure DXGK_NATIVE_FENCE_CAPS décrit les capacités de barrière native du GPU. Lorsque le KMD définit le bit MapToGpuSystemProcess de cette structure, il indique au système d'exploitation de réserver un espace d'adressage virtuel au GPU de processus système pour son utilisation par le CMP et de créer des mappages d'adresses virtuelles de GPU dans cet espace d'adressage pour la barrière native CurrentValue et MonitoredValue. Ces adresses virtuelles de GPU sont transmises ultérieurement au rappel de création de barrière du KMD en tant que DXGKARG_CREATENATIVEFENCE ::CurrentValueSystemProcessGpuVa et MonitoredValueSystemProcessGpuVa.
Lorsque sa fonction DxgkDdiQueryAdapterInfo est appelée, le KMD retourne sa structure DXGK_NATIVE_FENCE_CAPS remplie avec le type d'informations de l'adaptateur de requête DXGKQAITYPE_NATIVE_FENCE_CAPS ajouté.
DDI du KMD pour créer, ouvrir, fermer et détruire un objet de barrière native
Les DDI suivants implémentés par le KMD sont introduits pour créer, ouvrir, fermer et détruire un objet de barrière native. Dxgkrnl appelle ces DDI pour le compte des composants en mode utilisateur. Dxgkrnl les appelle uniquement si le système d'exploitation a activé la fonctionnalité DXGK_FEATURE_NATIVE_FENCE.
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiCreateNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
Les DDI suivants ont été mis à jour pour prendre en charge les objets de barrière native :
Les membres suivants ont été ajoutés à DRIVER_INITIALIZATION_DATA. Les pilotes qui prennent en charge les objets de barrière native GPU doivent implémenter les fonctions et fournir à Dxgkrnl des pointeurs vers ces derniers à travers cette structure.
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (ajouté dans WDDM 3.1)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence (ajouté dans WDDM 3.1)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (ajouté dans WDDM 3.2)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (ajouté dans WDDM 3.2)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (ajouté dans WDDM 3.2)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (ajouté dans WDDM 3.2)
Handles globaux et locaux pour les barrières partagées
Imaginons que le processus A crée une barrière native partagée et que le processus B ouvre ultérieurement cette barrière.
Lorsque le processus A crée la barrière native partagée, Dxgkrnl appelle DxgkDdiCreateNativeFence avec le handle du pilote d'adaptateur sur lequel cette barrière est créée. Le handle de barrière créé et retourné dans hGlobalNativeFence est le handle de la barrière globale.
Dxgkrnl poursuit ensuite avec un appel à DxgkDdiOpenNativeFence pour ouvrir un handle local spécifique au processus A (hLocalNativeFenceA).
Lorsque le processus B ouvre la même barrière native partagée, Dxgkrnl appelle DxgkDdiOpenNativeFence pour ouvrir un handle local spécifique au processus B (hLocalNativeFenceB).
Si le processus A détruit son instance de barrière native partagée, Dxgkrnl voit qu'il existe toujours une référence en suspens pour cette barrière globale, c'est pourquoi il appelle uniquement DxgkDdiCloseNativeFence(hLocalNativeFenceA) pour que le pilote nettoie les structures spécifiques au processus A. Le handle hGlobalNativeFence existe toujours.
Lorsque le processus B détruit son instance de barrière, Dxgkrnl appelle DxgkDdiCloseNativeFence(hLocalNativeFenceB), puis DxgkDdiDestroyNativeFence(hGlobalNativeFence) pour permettre au KMD de détruire les données de la barrière globale.
Mappages d'adresses virtuelles de GPU dans l'espace d'adressage du processus de pagination pour leur utilisation par le CMP
Le KMD définit la capacité DXGK_NATIVE_FENCE_CAPS ::MapToGpuSystemProcess sur le matériel qui nécessite que les adresses virtuelles de GPU de barrière native soient également mappées dans l'espace d'adressage du processus de pagination du GPU. Un bit MapToGpuSystemProcess défini indique au système d'exploitation de créer des mappages d'adresses virtuelles de GPU dans l'espace d'adressage du processus de pagination que les valeurs CurrentValue et MonitoredValue de la barrière native soient utilisées par le CMP. Ces adresses virtuelles de GPU sont ensuite transmises à DxgkDdiCreateNativeFence en tant que DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa et MonitoredValueSystemProcessGpuVa.
API de noyau D3DKMT pour les barrières natives
Les API en mode noyau D3DKMT suivantes sont introduites pour créer et ouvrir un objet de barrière native.
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl appelle la fonction D3DKMTDestroySynchronizationObject existante pour fermer et détruire (libérer) un objet de barrière native existant.
Les structures et énumérations de prise en charge introduites ou mises à jour sont les suivantes :
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
Indication d'un objet de barrière native de progression de la file d'attente matérielle
La mise à jour suivante est introduite pour indiquer un objet de barrière native de progression de file d'attente matérielle :
Un indicateur NativeProgressFence est ajouté pour les appels à DxgkDdiCreateHwQueue.
- Sur les systèmes pris en charge, le système d'exploitation met à jour la barrière de progression de file d'attente matérielle vers une barrière native. Lorsque le système d'exploitation définit NativeProgressFence, il indique au KMD que le handle DXGKARG_CREATEHWQUEUE ::hHwQueueProgressFence pointe vers le handle de pilote d'un objet de barrière native GPU précédemment créé à l'aide de DxgkDdiCreateNativeFence.
Interruption signalée par barrière native
Les modifications suivantes sont apportées au mécanisme d'interruption pour prendre en charge les interruptions signalées par des barrières natives :
- L'énumération DXGK_INTERRUPT_TYPE est mise à jour pour avoir un type d'interruption DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED.
- La structure DXGKARGCB_NOTIFY_INTERRUPT_DATA est mise à jour par l'inclusion d'une structure NativeFenceSignaled pour indiquer une interruption signalée par une barrière native. NativeFenceSignaled est utilisée pour informer le système d'exploitation qu'un ensemble d'objets de barrière native GPU surveillés par le processeur ont été signalés sur un moteur GPU. Si le GPU est capable de déterminer le sous-ensemble exact d'objets ayant des waiters de processeur actifs, il transfère ce sous-ensemble via pSignaledNativeFenceArray. Les handles de ce tableau doivent être des handles hGlobalNativeFence valides que Dxgkrnl a transmis au KMD dans DxgkDdiCreateNativeFence. Le passage d'un handle à un objet de barrière native détruit provoque une vérification de bogue.
- La structure DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS est mise à jour pour inclure un membre EvaluateLegacyMonitoredFences.
Le GPU peut transmettre un pSignaledNativeFenceArray NULL dans les conditions suivantes :
- Le GPU est incapable de déterminer le sous-ensemble exact d'objets ayant des waiters de processeur actifs.
- Les différentes interruptions de signal sont réduites ensemble, ce qui rend difficile la détermination de l'ensemble signalé avec des waiters actifs.
Une valeur NULL indique au système d'exploitation d'analyser tous les waiters d'objets de barrière native GPU en suspens.
Le contrat entre le système d'exploitation et le pilote est le suivant : si le système d'exploitation a un waiter de processus actif (exprimé par MonitoredValue) et que le moteur GPU a signalé l'objet à la valeur qui nécessite une interruption du processeur, le GPU doit exécuter l'une des actions suivantes :
- Inclure ce handle de barrière native dans le pSignaledNativeFenceArray.
- Déclencher une interruption NativeFenceSignaled avec un pSignaledNativeFenceArray NULL.
Par défaut, lorsque le KMD déclenche cette interruption avec un pSignaledNativeFenceArray NULL, Dxgkrnl n'analyse que les waiters de barrière native en suspens, et non les waiters surveillés hérités. Lorsque le matériel ne peut pas faire la distinction entre un DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED hérité et un DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED, le KMD peut toujours ne déclencher que l'interruption DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED introduite avec pSignaledNativeFenceArray = NULL et EvaluateLegacyMonitoredFences = 1, ce qui indique au système d'exploitation d'analyser tous les waiters (waiters de barrière surveillée hérités et waiters de barrière native).
Demande de mise à jour des lots de valeurs au KMD
Les interfaces suivantes sont introduites pour indiquer au KMD de mettre à jour un lot de valeurs actuelles ou surveillées :
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
Barrières natives inter-adaptateurs
Le système d'exploitation doit prendre en charge la création de barrières natives inter-adaptateurs, car les applications DX12 existantes créent et utilisent des barrières inter-adaptateurs surveillées. Si les files d'attente sous-jacentes et la planification de ces applications sont passées à la soumission en mode utilisateur, leurs barrières surveillées doivent également être passées à des barrières natives (les files d'attente en mode utilisateur ne peuvent pas prendre en charge les barrières surveillées).
Une barrière inter-adaptateurs doit être créée avec le type D3DDDI_NATIVEFENCE_TYPE_DEFAULT. Sinon, D3DKMTCreateNativeFence échoue.
Tous les GPU partagent la même copie du stockage de CurrentValue, qui est toujours alloué dans la mémoire système. Lorsque le runtime crée une barrière native inter-adaptateurs sur GPU1 et l'ouvre sur GPU2, les mappages d'adresses virtuelles de GPU sur les deux GPU pointent vers le même stockage physique de CurrentValue.
Chaque GPU obtient sa propre copie de MonitoredValue. Par conséquent, le stockage de MonitoredValue peut être alloué en mémoire système ou en mémoire locale.
Les barrières natives inter-adaptateurs doivent résoudre la condition dans laquelle GPU1 attend une barrière native signalée par GPU2. Aujourd'hui, le concept de signaux GPU-à-GPU n'existe pas ; par conséquent, le système d'exploitation résout explicitement cette condition en signalant GPU1 à partir du processeur. Ce signalement est effectué en ajustant la valeur MonitoredValue de la barrière inter-adaptateurs sur 0 pendant toute sa durée de vie. Ensuite, quand GPU2 signale la barrière native, il déclenche également une interruption du processeur, ce qui permet à Dxgkrnl de mettre à jour CurrentValue sur GPU1 (à l'aide de DxgkDdiUpdateCurrentValuesFromCpu avec l'indicateur NotificationOnly défini sur TRUE) et de débloquer les waiters de processeur/GPU en suspens de ce GPU.
Bien que MonitoredValue soit toujours 0 pour les barrières natives inter-adaptateurs, les attentes et signaux envoyés au même GPU bénéficient toujours d'une synchronisation sur GPU plus rapide. Toutefois, le bénéfice en termes de consommation d'énergie de la réduction des interruptions de processeur est perdu, car ces dernières se déclenchent de manière inconditionnelle, même s'il n'y a pas de waiters de processeur ou de waiters sur l'autre GPU. Ce compromis est conçu pour simplifier le coût de conception et d'implémentation de la barrière native inter-adaptateurs.
Le système d'exploitation prend en charge le scénario dans lequel un objet de barrière native est créé sur GPU1 et ouvert sur GPU2, et où GPU1 prend en charge la fonctionnalité, mais pas GPU2. L'objet de barrière est ouvert en tant que MonitoredFence standard sur GPU2.
Le système d'exploitation prend en charge le scénario dans lequel un objet de barrière surveillée standard est créé sur GPU1 et ouvert en tant que barrière native sur GPU2, lequel prend en charge la fonctionnalité. L'objet de barrière est ouvert en tant que barrière native sur GPU2.
Combinaisons attentes/signaux inter-adaptateurs
Les tableaux des sous-sections suivantes prennent l'exemple d'un système iGPU et dGPU, et répertorient les différentes configurations possibles des attentes/signaux de barrière native à partir du processeur/GPU. Les deux cas suivants sont pris en compte :
- Les deux GPU prennent en charge les barrières natives.
- L'iGPU ne prend pas en charge les barrières natives, contrairement au dGPU.
Le deuxième scénario est également similaire au cas où les deux GPU prennent en charge les clôtures natives, mais les attentes/signaux de barrière native sont envoyés à une file d'attente en mode noyau sur l'iGPU.
Les tableaux doivent être lues en sélectionnant une paire d'attente et de signal dans les colonnes, par exemple WaitFromGPU - SignalFromGPU ou WaitFromGPU - SignalFromCPU, etc.
Scénario 1
Dans le Scénario 1, les deux processeurs dGPU et iGPU prennent en charge les barrières natives.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| L'UMD insère une attente pour l'instruction hfence CurrentValue == 10 dans la mémoire tampon de commande | Le runtime appelle D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch effectue le suivi de cet objet de synchronisation dans sa liste de waiters de processeur de barrière native | |||
| L'UMD insère une instruction de signal d'écriture hFence CurrentValue = 10 dans la mémoire tampon de commande | Le runtime appelle D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch reçoit un ISR signalé par une barrière native quand CurrentValue est écrit (car MonitoredValue est toujours égale à 0) | VidSch appelle DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch propage le signal (hFence, 10) au iGPU | VidSch propage le signal (hFence, 10) au iGPU | ||
| VidSch reçoit le signal propagé et appelle DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch reçoit le signal propagé et appelle DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| Le KMD réanalyse la liste d'exécution pour débloquer le canal matériel qui attendait hFence | VidSch débloque la condition d'attente du processeur en signalant le KEVENT |
Scénario 2a
Dans le Scénario 2a, l'iGPU ne prend pas en charge les barrières natives, contrairement au dGPU. Une attente est envoyée à l'iGPU et un signal est envoyé au dGPU.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| Le runtime appelle D3DKMTWaitForSynchronizationObjectFromGpu | Le runtime appelle D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch effectue le suivi de cet objet de synchronisation dans sa liste d'attente de barrière surveillée | VidSch effectue le suivi de cet objet de synchronisation dans sa tête de liste de waiters du processeur de barrière surveillée | ||
| L'UMD insère une instruction de signal d'écriture hFence CurrentValue = 10 dans la mémoire tampon de commande | Le runtime appelle D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch reçoit NativeFenceSignaledISR quand CurrentValue est écrit (car MV est toujours égale à 0) | VidSch appelle DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch propage le signal (hFence, 10) au iGPU | VidSch propage le signal (hFence, 10) au iGPU | ||
| VidSch reçoit le signal propagé et observe la nouvelle valeur de barrière | VidSch reçoit le signal propagé et observe la nouvelle valeur de barrière | ||
| VidSch analyse sa liste d'attente de barrière surveillée et débloque les contextes logiciels | VidSch analyse sa liste d'attente de barrière surveillée et débloque les contextes logiciels en signalant le KEVENT |
Scénario 2b
Dans le Scénario 2b, la prise en charge de la barrière native reste la même (iGPU ne la prend pas en charge, contrairement à dGPU). Cette fois-ci, un signal est envoyé à l'iGPU et une attente est envoyée au dGPU.
| iGPU SignalFromGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGpu (hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| L'UMD insère une attente pour l'instruction hfence CurrentValue == 10 dans la mémoire tampon de commande | Le runtime appelle D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch effectue le suivi de cet objet de synchronisation dans sa liste de waiters de processeur de barrière native | |||
| L'UMD appelle D3DKMTSignalSynchronizationObjectFromGpu | L'UMD appelle D3DKMTSignalSynchronizationObjectFromCpu | ||
| Lorsque le paquet se trouve à la tête du contexte logiciel, VidSch met à jour la valeur de barrière directement à partir du processeur | VidSch met à jour la valeur de barrière directement à partir du processeur | ||
| VidSch propage le signal (hFence, 10) au dGPU | VidSch propage le signal (hFence, 10) au dGPU | ||
| VidSch reçoit le signal propagé et appelle DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch reçoit le signal propagé et appelle DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| Le KMD réanalyse la liste d'exécution pour débloquer le canal matériel qui attendait hFence | VidSch débloque la condition d'attente du processeur en signalant le KEVENT |
Futur signal inter-adaptateurs GPU-à-GPU
Comme décrit dans Problèmes de synchronisation, pour les barrières inter-adaptateurs natives, nous perdons les économies d'énergie, car les interruptions du processeur sont déclenchées de façon inconditionnelle.
Dans une prochaine version, le système d'exploitation développera une infrastructure grâce à laquelle un signal GPU sur un GPU pourra interrompre d'autres GPU en écrivant dans une mémoire de doorbell commune, permettant ainsi la sortie de veille d'autres GPU, le traitement de leur liste d'exécution et le déblocage des files d'attente matérielles prêtes.
Pour ce faire, le défi consiste à concevoir :
- La mémoire de doorbell commune.
- Une charge utile ou un handle intelligent qu'un GPU puisse écrire dans la doorbell, permettant à d'autres GPU d'identifier la barrière qui a été signalée afin qu'elle puisse analyser uniquement un sous-ensemble de HWQueues.
Avec un tel signal inter-adaptateurs, il peut même être possible que des GPU partagent la même copie du stockage de barrière native (une allocation inter-adaptateurs au format linéaire, similaire aux allocations d'analyse inter-adaptateurs) à partir de laquelle tous les GPU peuvent accéder en lecture et en écriture.
Conception de la mémoire tampon d'un journal de barrières natives
Avec les barrières natives et la soumission en mode utilisateur, Dxgkrnl n'a pas de visibilité sur le moment où les attentes et les signaux natifs GPU mis en file d'attente à partir de l'UMD sont débloqués sur le GPU pour une HWQueue particulière. Avec les barrières natives, une interruption signalée par une barrière surveillée peut être supprimée pour une barrière donnée.
:
Un moyen de recréer les opérations de barrière comme indiqué sur cette image GPUView est nécessaire. Les cases rose foncé sont des signaux, et les rose clair sont des attentes. Chaque case commence au moment où l'opération est envoyée au processeur à Dxgkrnl et se termine lorsque Dxgkrnl met fin à l'opération sur le processeur. Nous pouvons ainsi analyser toute la durée de vie d'une commande.
Par conséquent, à un niveau élevé, les conditions requises pour la journalisation de chaque HWQueue sont les suivantes :
| Condition | Signification |
|---|---|
| FENCE_WAIT_QUEUED | Horodatage processeur du moment où l'UMD insère une instruction d'attente GPU dans la file d'attente de commandes |
| FENCE_SIGNAL_QUEUED | Horodatage processeur du moment où l'UMD insère une instruction de signal GPU dans la file d'attente de commandes |
| FENCE_SIGNAL_EXECUTED | Horodatage GPU du moment où une commande de signal est exécutée sur GPU pour une HWQueue |
| FENCE_WAIT_UNBLOCKED | Horodatage GPU du moment où une condition d'attente est satisfaite sur GPU et que la HWQueue est débloquée |
DDI de mémoire tampon de journal de barrière native
Les DDI, structures et énumérations suivantes sont introduites pour prendre en charge les mémoires tampons de journal de barrière native :
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- Une mémoire tampon de journal qui contient un en-tête et un tableau d'entrées de journal. L'en-tête identifie si les entrées correspondent à un signal ou une attente, et chaque entrée identifie le type d'opération (exécuté ou débloqué) :
Mécanisme de mémoire tampon de journal
Dxgkrnl alloue deux mémoires tampons de journal dédiées de 4 Ko à chaque HWQueue.
- Une pour la journalisation des attentes.
- Une pour la journalisation des signaux.
Ces mémoires tampons de journal ont des mappages pour la VA du processeur en mode noyau (LogBufferCpuVa), une VA de GPU dans l'espace d'adressage du processus (LogBufferGpuVa) et la VA du CMP (LogBufferSystemProcessGpuVa), afin qu'elles puissent être lues/écrites dans le KMD, le moteur GPU et CMP. Dxgkrnl appelle DxgkDdiSetNativeFenceLogBuffer deux fois : une fois pour définir la mémoire tampon destinée à la journalisation des attentes et une autre fois pour la journalisation des signaux.
Immédiatement après l'insertion d'une instruction d'attente ou de signal de barrière native dans la liste de commandes, l'UMD insère également une commande indiquant au GPU d'écrire une charge utile dans une entrée déterminée de la mémoire tampon de journal.
Une fois que le moteur GPU a exécuté l'opération de barrière, il voit l'instruction de l'UMD d'écrire une charge utile dans une entrée déterminée de la mémoire tampon de journal. De plus, le GPU écrit également le FenceEndGpuTimestamp actuel dans cette entrée de mémoire tampon de journal.
Bien que l'UMD ne puisse pas accéder à la mémoire tampon de journal accessible par le GPU, elle contrôle sa progression. Autrement dit, l'UMD détermine la prochaine l'entrée libre dans laquelle écrire, si elle existe, et programme le GPU avec cette information. Lorsque le GPU écrit dans la mémoire tampon de journal, il incrémente la valeur FirstFreeEntryIndex dans l'en-tête du journal. L'UMD doit veiller à ce que les écritures dans les entrées du journal augmentent de façon monotonique.
Examinez le cas suivant :
- Il existe deux HWQueues, HWQueueA et HWQueueB, et les tampons de journal de barrière correspondants avec les VA de GPU de FenceLogA et FenceLogB. HWQueueA est associée à la mémoire tampon de journalisation des attentes et HWQueueB à celle de journalisation des signaux.
- Il existe un objet de barrière native avec un D3DKMT_HANDLE en mode utilisateur de FenceF.
- Une attente GPU sur FenceF de valeur V1 est mise en file d'attente dans HWQueueA au temps CPUT1. Lorsque l'UMD génère la mémoire tampon de commande, elle insère une commande indiquant au GPU de journaliser la charge utile : LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED).
- Un signal GPU sur FenceF de valeur V1 est mis en file d'attente dans HWQueueB au temps CPUT2. Lorsque l'UMD génère la mémoire tampon de commande, elle insère une commande indiquant au GPU de journaliser la charge utile : LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED).
Une fois que le programmateur de GPU exécute le signal GPU sur HWQueueB au temps GPUT1 du GPU, il lit la charge utile de l'UMD et journalise l'événement dans le journal de barrière fourni par le système d'exploitation pour HWQueueB :
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
Une fois que le programmateur GPU observe que HWQueueA est débloquée au temps GPUT2 du GPU, il lit la charge utile de l'UMD et journalise l'événement dans le journal de barrière fourni par le système d'exploitation pour HWQueueA :
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl peut détruire et recréer une mémoire tampon de journal. Chaque fois qu'il le fait, il appelle DxgkDdiSetNativeFenceLogBuffer pour informer le KMD du nouvel emplacement.
Horodatage processeur des opérations en file d'attente de barrière
Il n'y a pas beaucoup d'intérêt à faire en sorte que l'UMD journalise ces horodatages processeur, pour les raisons suivantes :
- Une liste de commandes peut être enregistrée plusieurs minutes avant l'exécution GPU d'une mémoire tampon de commandes qui inclut la liste de commandes.
- Ces quelques minutes peuvent être décalées par rapport à d'autres objets de synchronisation qui se trouvent dans la même mémoire tampon de commande.
Il est coûteux d'inclure les horodatages processeur dans les instructions de l'UMD pour la mémoire tampon de journal écrite par le GPU, de sorte que les horodatages processeur ne sont pas inclus dans la charge utile d'entrée de journal.
Au lieu de cela, le runtime ou l'UMD peut émettre un événement ETW de file d'attente de barrière native avec l'horodatage processeur au moment où une liste de commandes est enregistrée. Les outils peuvent ainsi générer une chronologie des événements mis en file d'attente de barrière et terminés en combinant l'horodatage processeur à partir de ce nouvel événement et l'horodatage GPU à partir de l'entrée de la mémoire tampon de journal.
Ordre des opérations sur GPU lors du signalement ou du déblocage d'une barrière
L'UMD doit s'assurer qu'elle conserve l'ordre suivant lorsqu'elle génère une liste de commandes indiquant au GPU de signaler/débloquer une barrière :
- Écriture de la nouvelle valeur de barrière à la VA GPU/VA CMP d'une barrière.
- Écriture de la charge utile de journal dans la mémoire tampon de journal correspondante de la VA GPU/VA CMP.
- Déclenchement d'une interruption signalée par une barrière native, si nécessaire.
Cet ordre des opérations garantit que Dxgkrnl puisse voir les entrées de journal les plus récentes lorsque l'interruption est déclenchée vers le système d'exploitation.
Le dépassement de la mémoire tampon de journal est autorisé
Le GPU peut dépasser la mémoire tampon de journal en remplaçant les entrées qui n'ont pas encore été vues par le système d'exploitation. Pour ce faire, il incrémente le WraparoundCount.
Lorsque le système d'exploitation lit le journal, il peut détecter qu'un dépassement s'est produit en comparant la nouvelle valeur WraparoundCount dans l'en-tête du journal à celle mise en cache. Si un dépassement s'est produit, le système d'exploitation dispose des options de secours suivantes :
- Pour débloquer des barrières lorsqu'il se produit un dépassement, le système d'exploitation analyse toutes les barrières et détermine les waiters qui ont été débloqués.
- Si le traçage a été activé, le système d'exploitation peut émettre un indicateur dans la trace pour prévenir un utilisateur que des événements ont été perdus. De plus, lorsque le traçage est activé, le système d'exploitation augmente tout d'abord la taille de la mémoire tampon de journal pour éviter les dépassements au niveau de la première position.
Il n'est pas nécessaire que l'UMD implémente la prise en charge de la contre-pression pendant la saisie des entrées de mémoire tampon de journal.
Horodatages de mémoire tampon de journal vides ou répétés
Dans la plupart des cas, Dxgkrnl s'attend à ce que les horodatages des entrées de journal augmentent de façon monotonique. Il existe cependant des scénarios où les horodatages des entrées de journal suivantes sont nuls, ou identiques aux entrées précédentes.
Par exemple, dans les scénarios avec des adaptateurs d'affichage liés, l'un des adaptateurs chaînés de la LDA peut ignorer l'opération d'écriture de barrière. Dans ce cas, l'horodatage de l'entrée de mémoire tampon de journal est nul. Dxgkrnl gère ce type d'incident. Cela dit, Dxgkrnl ne s'attend jamais à ce que l'horodatage d'une entrée de journal donnée soit inférieur à celui de l'entrée précédente ; en d'autres termes, les horodatages ne peuvent jamais revenir en arrière.
Mise à jour synchrone du journal de barrière native
Les écritures du GPU destinées à mettre à jour la valeur de barrière et la mémoire tampon de journal correspondante doivent être totalement propagées avant la lecture du processeur. Cette exigence requiert l'utilisation de barrières mémoire. Par exemple :
- Signal Fence(N) : écrire N comme nouvelle valeur actuelle
- Écrire l'entrée de journal, y compris l'horodatage GPU
- MemoryBarrier
- Incrémenter FirstFreeEntryIndex
- MemoryBarrier
- Interruption de barrière surveillée (N) : lire l'adresse « M » et comparer la valeur avec N pour décider du déclenchement de l'interruption du processeur
Il est trop coûteux d'insérer deux barrières sur chaque signal GPU, surtout lorsqu'il est probable que la vérification de l'interruption conditionnelle n'est pas satisfaite et que l'interruption du processeur n'est pas nécessaire. Par conséquent, la conception déplace le coût d'insertion de l'une des barrières de mémoire du GPU (producteur) vers le processeur (consommateur). Dxgkrnl appelle la fonction DxgkDdiUpdateNativeFenceLogs introduite pour que le KMD vide de manière synchrone les écritures de journal de barrière native en suspens à la demande (à l'instar de DxgkddiUpdateflipqueuelog qui a été introduit pour le vidage d'un journal de file d'attente matérielle des basculements).
Opérations GPU :
- Signal Fence(N) : écrire N comme nouvelle valeur actuelle
- Écrire l'entrée de journal, y compris l'horodatage GPU
- Incrémenter FirstFreeEntryIndex
- MemoryBarrier => Garantit que FirstFreeEntryIndex est entièrement propagé
- Interruption de barrière surveillée (N) : lire l'adresse « M » et comparer la valeur avec N pour décider du déclenchement de l'interruption
Opérations CPU :
Dans le gestionnaire d'interruptions signalées par barrière native de Dxgkrnl (DISPATCH_IRQL) :
- Pour le journal de chaque HWQueue : lire FirstFreeEntryIndex et déterminer si de nouvelles entrées sont écrites.
- Pour chaque journal de HWQueue avec de nouvelles entrées : appeler DxgkDdiUpdateNativeFenceLogs et fournir les handles de noyau pour ces HWQueues. Dans ce DDI, le KMD insère une barrière de mémoire dans chaque HWQueue donnée, ce qui garantit que toutes les écritures d'entrée de journal sont validées.
- Dxgkrnl lit les entrées du journal pour extraire la charge utile d'horodatage.
Ainsi, tant que le matériel insère une barrière de mémoire après des écritures dans FirstFreeEntryIndex, Dxgkrnl appelle toujours le DDI du KMD, ce qui permet au KMD d'insérer une barrière de mémoire avant que Dxgkrnl ne lise toutes les entrées de journal.
Future configuration matérielle requise
La plupart du matériel de génération actuelle ne peut prendre en charge que l'écriture du handle de noyau de l'objet de barrière qu'il a signalé dans l'interruption signalée par barrière native. Cette conception est décrite précédemment dans Interruption signalée par barrière native. Dans ce cas, Dxgkrnl traite la charge utile d'interruption de la manière suivante :
- Le système d'exploitation effectue une lecture (potentiellement sur PCI) de la valeur de barrière.
- Sachant quelle barrière a été signalée et connaissant la valeur de barrière, le système d'exploitation met en sortie de veille les waiters du processeur qui attendent cette barrière/valeur.
- Séparément, pour l'appareil parent de cette barrière, le système d'exploitation analyse les mémoires tampons de journal de toutes ses HWQueues. Le système d'exploitation lit ensuite les dernières entrées de mémoire tampon de journal écrites pour déterminer la HWQueue d'où provient le signal et extrait la charge utile d'horodatage correspondante. Cette approche peut lire de manière redondante certaines valeurs de barrière dans PCI.
Sur les futures plateformes, Dxgkrnl préfère obtenir un tableau de handles HwQueue de noyau dans l'interruption signalée par barrière native. Cette approche offre au système d'exploitation les possibilités suivantes :
- Lire les dernières entrées de mémoire tampon de journal pour cette HwQueue. L'appareil utilisateur n'étant pas connu du gestionnaire d'interruptions, ce handle de HwQueue doit être un handle de noyau.
- Analyser la mémoire tampon de journal pour les entrées qui indiquent les barrières qui ont été signalées, et les valeurs correspondantes. La lecture seule de la mémoire tampon de journal garantit une lecture unique sur PCI au lieu de devoir lire de manière redondante les valeurs de barrière et la mémoire tampon de journal. Cette optimisation réussit tant que la mémoire tampon de journal n'est pas dépassée (suppression d'entrées que Dxgkrnl n'a jamais lues).
- Si le système d'exploitation détecte que la mémoire tampon de journal a été dépassée, elle revient au chemin non optimisé qui effectue la lecture de la valeur dynamique de chaque barrière appartenant au même appareil. Les performances sont proportionnelles au nombre de barrières détenues par l'appareil. Si la valeur de barrière est en mémoire vidéo, ces lectures sont cohérentes avec le cache dans le PCI.
- Sachant quelles barrières ont été signalées et connaissant les valeurs de barrière, le système d'exploitation met en sortie de veille les waiters du processeur qui attendent ces barrières/valeurs.
Interruption signalée par barrière native optimisée
Aux modifications décrites dans Interruption signalée par barrière native s'ajoute la modification suivante pour prendre en charge l'approche optimisée :
- La capacité OptimizedNativeFenceSignaledInterrupt est ajoutée à DXGK_VIDSCHCAPS.
Si elle est prise en charge par le matériel, au lieu de remplir un tableau avec les handles des barrières qui ont été signalées, le GPU doit simplement mentionner le handle KMD de la HWQueue qui s'exécutait lorsque l'interruption a été déclenchée. Dxgkrnl analyse la mémoire tampon de journal de barrière pour cette HWQueue, lit toutes les opérations de barrière qui ont été effectuées par le GPU depuis la dernière mise à jour et débloque tous les waiters de processeur correspondants. Si le GPU n'a pas pu déterminer quel sous-ensemble de barrières ont été signalées, il doit spécifier un handle de HWQueue NULL. Quand Dxgkrnl voit un handle de HWQueue NULL, il revient en arrière pour réanalyser la mémoire tampon de journal de toutes les HWQueues sur ce moteur afin de déterminer quelles sont les barrières qui ont été signalées.
La prise en charge de cette optimisation est facultative ; le KMD doit définir la capacité DXGK_VIDSCHCAPS :OptimizedNativeFenceSignaledInterrupt si elle est prise en charge par le matériel. Si la capacité OptimizedNativeFenceSignaledInterrupt n'est pas définie, le GPU/KMD doit suivre le comportement décrit dans Interruption signalée par barrière native.
Exemple d'interruption signalée par barrière native optimisée
HWQueueA : Signal GPU vers Barrière F1, Valeur V1 -> Écrire dans l'entrée E1 de la mémoire tampon du journal -> aucune interruption requise
HWQueueA : Signal GPU vers Barrière F1, Valeur V2 -> Écrire dans l'entrée E2 de la mémoire tampon du journal -> aucune interruption requise
HWQueueA : Signal GPU vers Barrière F2, Valeur V3 -> Écrire dans l'entrée E3 de la mémoire tampon du journal -> aucune interruption requise
HWQueueA : Signal GPU vers Barrière F2, Valeur V3 -> Écrire dans l'entrée E4 de la mémoire tampon du journal -> interruption déclenchée
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl lit la mémoire tampon de journal pour HWQueueA. Il lit les entrées E1, E2, E3 et E4 de la mémoire tampon du journal pour observer les barrières signalées F1 à la valeur V1, F1 à la valeur V2, F2 à la valeur V3 et F2 à la valeur V3, et débloque tous les waiters en attente de ces barrières et valeurs
Journalisation facultative et obligatoire
La prise en charge de la journalisation des barrières natives pour DXGK_NATIVE_FENCE_LOG_TYPE_WAITS et DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS est obligatoire.
À l'avenir, d'autres types de journalisation peuvent être ajoutés uniquement lorsque des outils tels que GPUView activent la journalisation ETW détaillée dans le système d'exploitation. Le système d'exploitation doit informer à la fois l'UMD et le KMD du moment où la journalisation détaillée est activée et désactivée afin que la journalisation de ces événements détaillés soit activée de manière sélective.